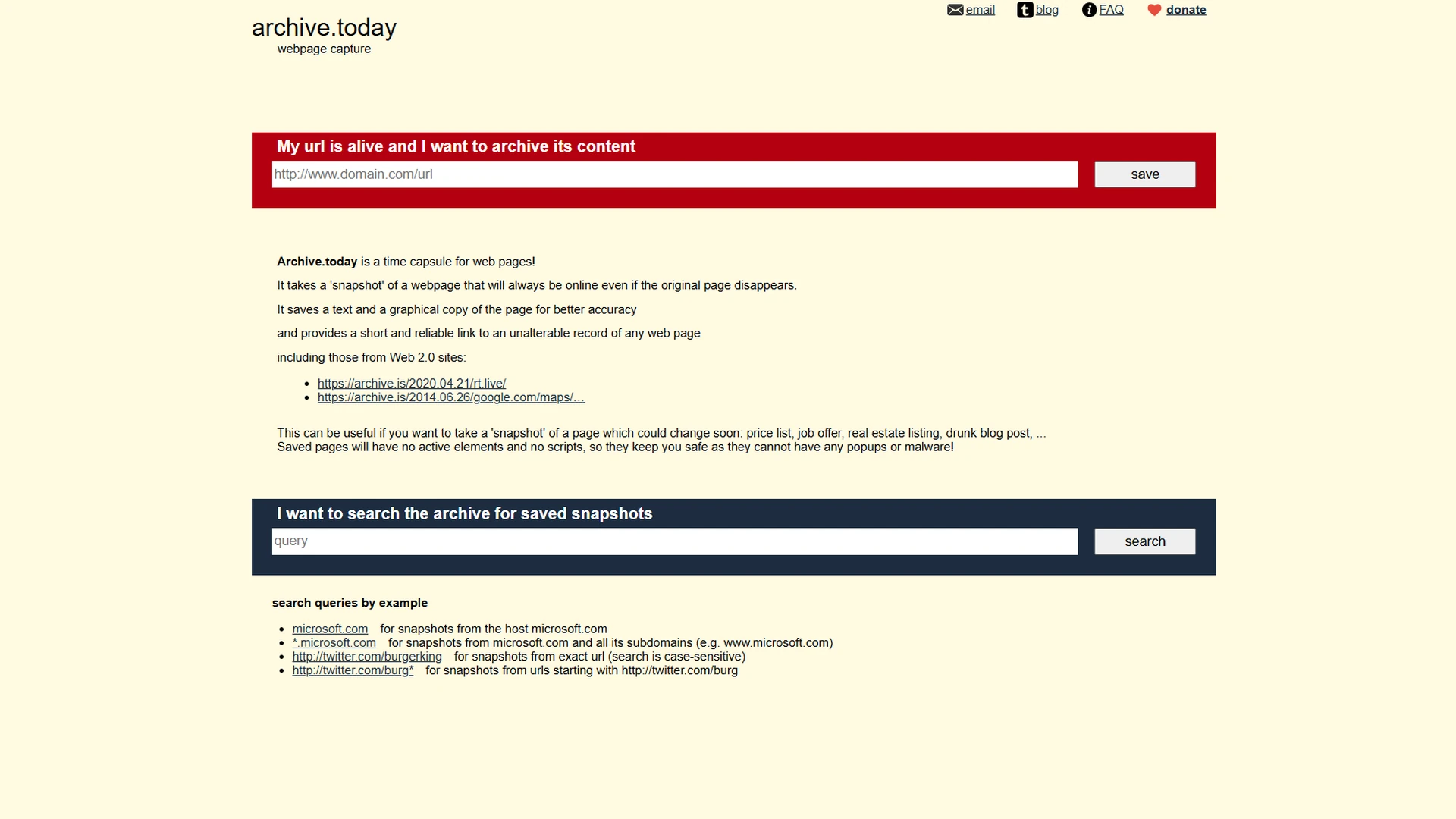
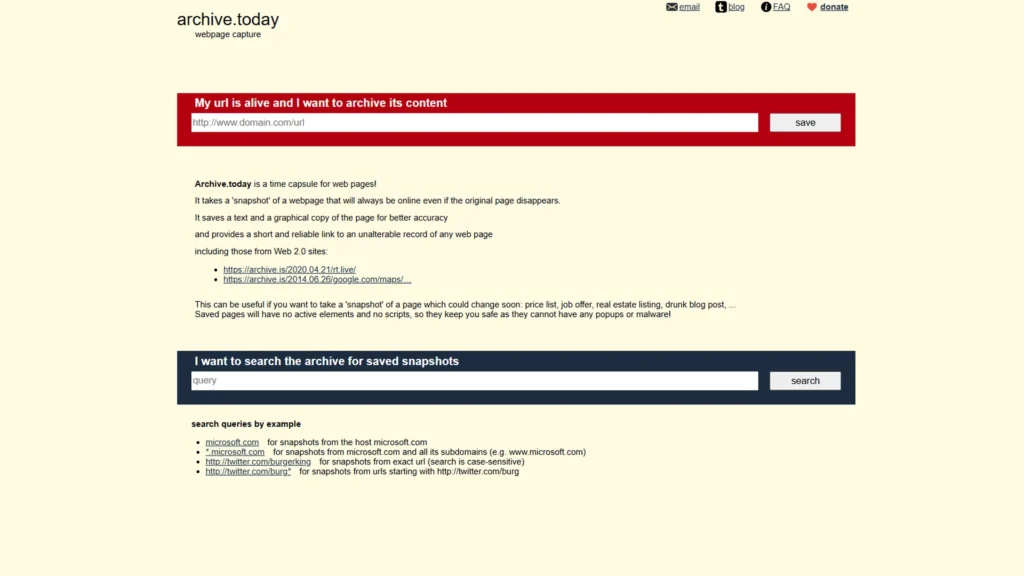
Archive.is looks like one of those websites you open once, size up in five seconds, and then keep returning to for years. It is spare, blunt, and almost indifferent to modern product polish. That is part of its charm. Its job is narrow: take a live page, freeze it, and give you a stable public link to that version before the original changes, disappears, or gets cleaned up. The homepage says it plainly: Archive.today is “a time capsule for web pages,” and the pitch still lands because the live web keeps proving how fragile it is.
Table of Contents
That fragility is no longer a niche complaint from librarians and link nerds. Pew found that a quarter of webpages that existed at some point between 2013 and 2023 were no longer accessible by October 2023. News pages break. Government pages drift. Wikipedia references rot. The web keeps acting like a permanent public record while behaving more like a constantly edited draft. Archive.is matters because it takes that instability seriously.
A small site doing a job bigger platforms still fumble
Archive.is is not trying to be the whole memory of the internet. It is not trying to map every site, preserve every link trail, or build a formal citation system for journals and courts. It is much more immediate than that. You paste in a URL, it makes a manual capture, and you get a public record tied to a specific moment. That makes it feel less like a grand archive and more like a freeze it now utility for people who have learned not to trust the live page to stay put.
That focus is why the service keeps turning up in journalism, open-source investigations, fact-checking, research notes, and ordinary internet disputes. Bellingcat’s guidance is blunt about the value of archiving digital evidence: you preserve material in case it disappears, and you give readers a way to see that it existed as presented. GIJN makes the same point from a reporter’s angle: save public material while it is still public, because access can change fast. Archive.is fits that reflex almost perfectly.
There is also something deeply webby about the service itself. It feels like an old internet utility that never stopped being useful just because sleeker products arrived. You do not open it for a curated experience. You open it because the page in front of you may not survive the afternoon in the same form. That is a different kind of product promise, and a more honest one.
What you actually get when you save a page
Calling Archive.is a screenshot service misses the point. Its newer toolkit entry at Bellingcat describes a capture as a preserved snapshot of the page’s text, images, design, rendered HTML, CSS, JavaScript-generated content, and a lossless PNG screenshot of the same page. Archive.today’s own homepage says it saves both a text copy and a graphical copy “for better accuracy.” That mix is what makes it so handy. You get visual proof and a preserved page rendering, not just a flat image somebody could dismiss as easy to fake.
The service also gives you a few small but surprisingly useful retrieval tricks. The homepage supports archive searches by host, wildcard subdomain, and exact URL pattern. The FAQ shows shortcuts for jumping to the newest or oldest archived version of a page, and even for linking to selected text or a scroll position inside a long capture. That sounds nerdy until you need to compare wording across versions or send somebody to the exact part that changed. Then it feels brilliant.
Its limits are just as important as its strengths. The FAQ says it saves textual content, images, frame content, JavaScript-loaded material, and a screenshot, but not Flash, PDF, most XML reliably, or the actual media payload behind video and audio. The archived page also strips active elements and scripts. Forms, search boxes, and other live functions stop being live. What you keep is a rendered historical page, not a living clone of the original site.
One detail from the FAQ is easy to miss and worth knowing: when you archive a page, your IP is sent to the website being archived in an X-Forwarded-For header so the target site can serve region-specific content as if the request came from you. That will not matter for everyday use, but it is exactly the kind of small operational detail that matters to researchers and investigators. Archive.is is simple on the surface. It is not consequence-free.
The people who feel its value first
The first people to really love Archive.is are usually people who have already been burned. A reporter cites a company page, goes back later, and finds softened language. A researcher bookmarks a post, returns a week later, and hits a deletion notice. A fact-checker remembers what a public figure said, but memory is not enough when the post is gone. Archive.is turns that sinking feeling into a habit: save the page now, sort out the argument later.
That habit is stronger than it sounds. Bellingcat recommends archiving materials because screenshots alone can be forged and because preserved versions let you demonstrate that a page existed as shown. It also recommends saving to both Archive.today and Archive.org when possible. That is practical advice, not tool tribalism. If a source matters, one copy is good, two are better, and your own notes are better still.
Archive.is is especially good in the tense little window before something gets tidied up. That is where its manual design becomes a feature. You do not wait and hope a crawler finds the page later. You capture it on purpose. That makes the service feel fast in a deeper sense than speed alone. It is fast because it matches the real tempo of online revision, deletion, and denial.
It is useful precisely because it is not sacred
The smartest way to use Archive.is is to trust it for what it is and stop there. It is strong at page-level capture. It is not an infallible notary, not a polished institutional repository, and not the cleanest final home for formal scholarship. Bellingcat’s older guide says Archive.today is more versatile than Archive.org for many social network pages, but also notes that it is a much smaller operation and should be seen as less stable than Archive.org. That is not a fatal flaw. It is a workflow instruction.
The right response is redundancy. Archive the page on Archive.is. Save it to the Wayback Machine too. Keep your own screenshot. Keep the original URL. Keep a note about why you captured it and what mattered on the page at that moment. GIJN’s advice on saving online evidence leans in the same direction: preserve material while it is public, and preserve more than one thing when the stakes justify it.
That point also separates Archive.is from Perma.cc. Perma.cc is built and supported by libraries, and its whole pitch is durable citation for scholars, journals, courts, and other people who need preserved links inside a formal publishing workflow. Archive.is is better understood as the quick-draw tool. Perma.cc is the cleaner final home when the end product is a citation rather than a field note.
Where it fits next to Wayback and Perma.cc
Which archive fits which job
| Tool | Best moment to use it | What stands out | What to watch |
|---|---|---|---|
| Archive.is | A page may change today | Fast manual capture of a specific page | Not built as a full institutional citation system |
| Wayback Machine | You want broader site history | Strong public archive with permanent saved-page URLs | Some pages still fail or save only partially |
| Perma.cc | You are writing something formal | Built around durable citation and library support | Less of a general public discovery archive |
That split matches the way the services describe themselves and the way investigators actually use them: Archive.today for quick page freezes, the Wayback Machine for broader public preservation, and Perma.cc for citation that needs to hold up in journals, courts, and other formal settings.
What makes Archive.is interesting in that lineup is that it feels almost aggressively unceremonious. It does not ask you to buy into a theory of preservation. It just solves a recurring problem on the spot. That is why it sticks. People do not adopt it because it is pretty or institutionally reassuring. They adopt it because the first time they need an earlier version of a page, it saves them.
The habit it teaches is more important than the tool
Archive.is is worth opening not only because it works, but because it teaches the right suspicion. A live webpage is not a settled document. It is a temporary state. The moment you start treating it that way, your research gets sharper. You save first. You cite more carefully. You stop assuming that publication equals permanence. Pew’s numbers on disappearing pages make that mindset feel less paranoid and more like basic digital literacy.
That may be the most interesting thing about Archive.is as a web object. It belongs to a class of tools that became necessary because the internet quietly failed at one of its own promises. The web was supposed to make information easier to publish and easier to find again. It did the first part brilliantly. The second part turned out to be much harder. Archive.is survives because it patches that failure in one sharp, public, low-friction way.
There are bigger archives. There are cleaner academic tools. There are sturdier institutional systems. Archive.is still earns its place because it sits right at the moment where memory is about to become hearsay. That is a strange little corner of the internet, but an important one. And once you have used it to catch a page just before it vanished or changed, it stops looking strange at all.
Author:
Jan Bielik
CEO & Founder of Webiano Digital & Marketing Agency
This article is an original analysis supported by the sources cited below
Archive.today
Official homepage for the service, including its core description, search behavior, and the claim that archived pages become an unalterable record.
Archive.today FAQ
Official FAQ covering what the service captures, what it does not, how saved pages behave, and technical details that matter in practice.
Archive.today | Bellingcat’s Online Investigation Toolkit
Bellingcat’s current overview of Archive.today’s snapshot model, capture details, and investigative use cases.
How to Archive Open Source Materials
Bellingcat’s practical guide to archiving online evidence, including why it recommends using both Archive.today and Archive.org.
How to Save Online Evidence and Why It Matters: Part One
GIJN guidance on preserving public online material before it is edited, restricted, or removed.
When Online Content Disappears
Pew Research Center’s report on digital decay, broken links, and the scale of disappearing web content.
Save Pages in the Wayback Machine
Internet Archive help documentation describing Save Page Now and what a saved page includes.
Perma.cc
Official Perma.cc site explaining its library-backed role in preserving cited webpages for scholars, journals, courts, and other formal users.
| Citing this article? Brief excerpts are welcome. Please credit Webiano.digital, name the author where stated, and include a link to https://webiano.digital and to this original article. Full or substantial republication requires prior written permission. Read our Copyright and Content Use Policy. |