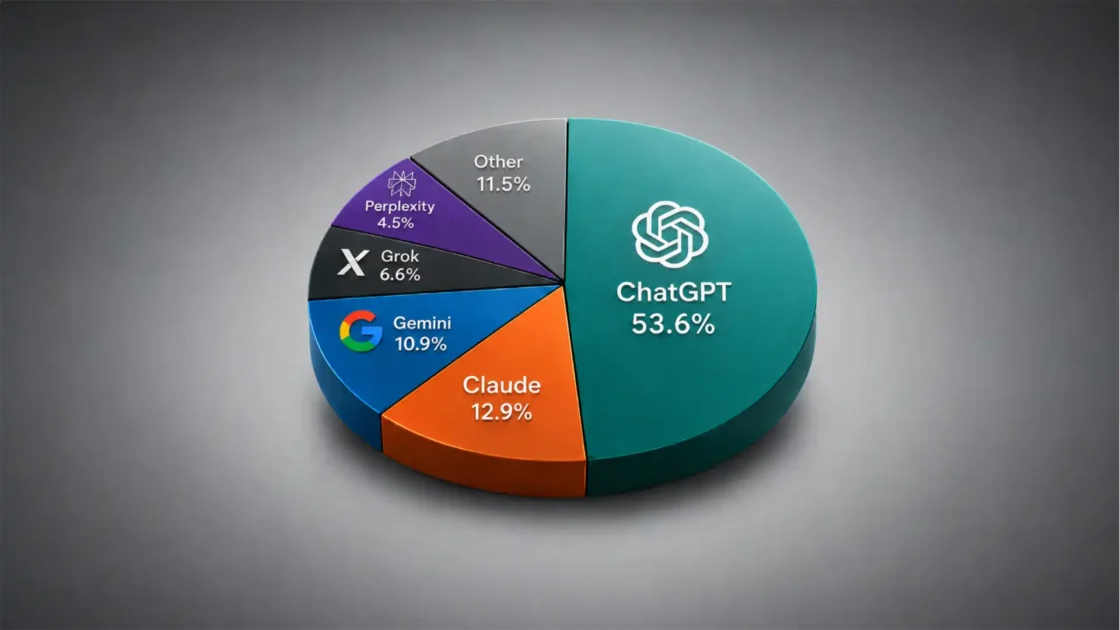
OpenAI’s GPT-5.5, Anthropic’s Claude Opus 4.7, and DeepSeek V4 arrived close enough together to look like a clean three-way race. It is not clean. It is not even one race.
Table of Contents
GPT-5.5 is OpenAI’s bet on execution-heavy professional work inside ChatGPT, Codex, and the API stack. Claude Opus 4.7 is Anthropic’s bet on long-horizon reasoning, careful tool use, coding reliability, high-resolution vision, and enterprise trust. DeepSeek V4 is China’s most forceful open-weights answer to the closed frontier, built around low prices, 1M-token context, Mixture-of-Experts architecture, and domestic hardware adaptation.
The tempting article would rank them first, second, and third. That would be too neat. These models now sit in different strategic lanes. The real comparison is not “which model is smartest?” but “which model gives the best mix of capability, control, cost, deployment freedom, and risk management for the work you actually need done?”
As of April 27, 2026, the three launches are real and current: Anthropic announced Claude Opus 4.7 on April 16, OpenAI announced GPT-5.5 on April 23, and DeepSeek posted the DeepSeek V4 Preview release on April 24. OpenAI describes GPT-5.5 as its strongest model for agentic coding and professional work; Anthropic calls Opus 4.7 its most capable generally available model for complex reasoning and agentic coding; DeepSeek describes V4-Pro and V4-Flash as open-sourced 1M-context models aimed at reasoning, knowledge, coding, and agent work.
The comparison starts with three different bets
The mistake in many AI model comparisons is treating every model as a general-purpose text engine. That framing made more sense during the GPT-3 and early Claude years, when the main question was whether a model could write, summarize, code a little, and follow instructions. The frontier has moved. The most serious models are now built for work loops, not prompt responses. They read large context, call tools, inspect outputs, revise plans, interact with files, run code, and recover when something breaks.
GPT-5.5 is strongest when the work looks like a professional workflow. OpenAI’s own documentation points to coding, tool-heavy agents, long-context retrieval, customer-facing workflows, product-spec-to-plan workflows, and multi-step execution as the model’s main zone. The company also says GPT-5.5 should not be treated as a drop-in replacement for older GPT-5.x models, because prompts, reasoning effort, verbosity, and tool descriptions may need fresh tuning.
Claude Opus 4.7 is framed less as a speed upgrade and more as a reliability upgrade for demanding work. Anthropic’s API docs call it the company’s most capable generally available model, with a “step-change improvement” in agentic coding over Opus 4.6. Its migration guide describes 1M context, adaptive thinking, prompt caching, Files API, PDF support, vision, tools, computer use, web search, MCP connectors, and memory support. That is not a chatbot pitch. It is a controlled agent platform pitch.
DeepSeek V4 is the most disruptive of the three in economic and geopolitical terms. DeepSeek-V4-Pro uses 1.6T total parameters with 49B active parameters, while V4-Flash uses 284B total with 13B active. Both support 1M context. The company positions V4-Pro as a top open model that approaches closed frontier performance, while V4-Flash is the low-cost, faster model for high-volume use.
The short version is blunt: OpenAI is selling higher-confidence execution, Anthropic is selling controlled autonomy, and DeepSeek is selling open access plus brutal price pressure.
The launch timeline matters
The dates matter because they reveal the rhythm of the frontier market. Anthropic moved first with Claude Opus 4.7 on April 16. OpenAI answered on April 23 with GPT-5.5. DeepSeek followed on April 24 with V4 Preview. The spacing was not just industry theater. It shaped how each release was read.
Anthropic’s launch landed as a direct continuation of its Opus line. Opus 4.7 was presented as a stronger, more precise successor to Opus 4.6, not as a full reset. The release leaned on partner evaluations from companies such as Hex, Notion, CodeRabbit, Genspark, Warp, Harvey, XBOW, Factory, and others. Those references matter because Anthropic used them to show how Opus 4.7 behaves in actual workflows, not only on public benchmarks. A model that writes good answers is one thing. A model that keeps a multi-step coding or research workflow alive through tool failures is a different product.
OpenAI’s GPT-5.5 launch arrived with a more direct claim to benchmark leadership. OpenAI said GPT-5.5 reaches 82.7% on Terminal-Bench 2.0 and 58.6% on SWE-Bench Pro. It also cited 84.9% on GDPval, 78.7% on OSWorld-Verified, and 98.0% on Tau2-bench Telecom. These numbers fit OpenAI’s positioning: GPT-5.5 is not only a better writer or coder, but a stronger executor across work simulations, software environments, and customer-service flows.
DeepSeek’s launch landed one day later with a different kind of force. V4 is not only a model release; it is also a supply-chain statement. Reuters reported that DeepSeek-V4 was adapted for Huawei chips, with Huawei saying the V4 series is supported on its Ascend 950-based clusters. DeepSeek’s earlier V3 and R1 releases became symbols of China’s ability to build strong models under chip pressure. V4 extends that story from model capability into domestic inference infrastructure.
The launch order created a useful contrast: Anthropic pushed trust and long-running reliability, OpenAI pushed task execution and benchmark strength, DeepSeek pushed open weights and cost under hardware constraints.
The headline comparison in one table
A table cannot settle this comparison, but it can keep the facts straight. The numbers below are taken from official model pages and documentation where available, with DeepSeek pricing reflecting its official limited-time discount window as listed on April 27, 2026.
Model comparison snapshot
| Model | Core positioning | Context and output | API price signal | Strongest visible angle |
|---|---|---|---|---|
| GPT-5.5 | OpenAI frontier model for coding and professional work | 1,050,000 context, 128,000 max output | $5 input, $0.50 cached input, $30 output per 1M tokens | Agentic coding, tool-heavy workflows, polished professional execution |
| Claude Opus 4.7 | Anthropic premium model for complex reasoning and agentic coding | 1M context, 128K max output | $5 input, $0.50 cache hits, $25 output per 1M tokens | Long-horizon coding, careful reasoning, high-resolution vision, enterprise controls |
| DeepSeek V4-Pro | Open-weight MoE model for frontier-style reasoning at low cost | 1M context, 384K max output | $0.435 input and $0.87 output per 1M tokens during limited discount, then $1.74 and $3.48 listed | Open weights, extreme price pressure, long-context architecture, Huawei adaptation |
| DeepSeek V4-Flash | Smaller open-weight MoE model for low-cost high-volume work | 1M context, 384K max output | $0.14 input and $0.28 output per 1M tokens | Cheap reasoning, fast agent tasks, broad developer access |
GPT-5.5 pricing comes from OpenAI’s API and pricing docs; Claude Opus 4.7 pricing comes from Anthropic’s pricing docs; DeepSeek V4 pricing comes from DeepSeek’s official pricing page, which lists a 75% temporary discount for V4-Pro until May 5, 2026, and much lower V4-Flash prices.
The table reveals the core tension. GPT-5.5 and Claude Opus 4.7 are priced like premium closed models. DeepSeek V4 is priced like a market weapon. Even after the temporary V4-Pro discount ends, DeepSeek’s listed output price remains far below OpenAI and Anthropic’s frontier output pricing.
Yet price alone does not pick the winner. The closed models may still justify their cost in workflows where reliability, safety controls, tool integration, support, latency consistency, enterprise compliance, and multimodal quality matter more than raw tokens. DeepSeek’s advantage is strongest when developers can tolerate more integration work, want open weights, need low-cost scale, or operate in markets where price and deployment control beat premium polish.
GPT-5.5 is built for execution-heavy professional work
GPT-5.5 is not best understood as a “smarter chatbot.” OpenAI’s own language points toward something more specific: a model that can carry harder professional tasks through planning, tool use, verification, and final output with less human steering. That matters because the expensive part of AI work is often not the first answer. It is the retries, corrections, missed constraints, failed tool calls, hallucinated assumptions, and half-finished implementation work that follow.
OpenAI says GPT-5.5 is designed for coding, online research, information analysis, document and spreadsheet creation, and moving across tools to get work done. The system card says the model “understands the task earlier,” asks for less guidance, uses tools better, checks its work, and keeps going until it is done. Those are agentic behaviors, not merely language behaviors.
The clearest GPT-5.5 strength is coding inside an execution loop. OpenAI reports 82.7% on Terminal-Bench 2.0 and 58.6% on SWE-Bench Pro. The public Terminal-Bench 2.0 leaderboard lists Codex with GPT-5.5 at the top with 82.0% ± 2.2, ahead of many previous GPT, Claude, Gemini, and agent combinations. Benchmarks are imperfect, but Terminal-Bench is useful because it tests command-line workflows where a model must plan, run commands, inspect errors, and recover.
GPT-5.5 also has an enterprise writing and analysis angle. GDPval, OSWorld-Verified, and Tau2-bench Telecom are not pure coding tests. They measure knowledge-work deliverables, computer-use tasks, and workflow handling. OpenAI’s strongest claim is not that GPT-5.5 wins every domain. The stronger claim is that it has become more consistent across work shapes where older models tended to break: long task setup, tool coordination, intermediate state tracking, and final packaging.
Its cost profile is more complicated. GPT-5.5 output tokens cost more than Claude Opus 4.7 output tokens, with OpenAI listing $30 per 1M output tokens versus Anthropic’s $25 for Opus 4.7. OpenAI’s answer is that GPT-5.5 can reach better outcomes with fewer reasoning tokens and fewer retries. That may be true for many workloads, but it is not a universal law. For teams, the question is not token price alone. It is total cost per accepted task.
GPT-5.5 is probably the safest first pick when a team already lives inside OpenAI’s ecosystem, uses Codex, needs strong tool use, wants polished outputs, and values broad professional versatility. It is less obvious as the default when deployment freedom, open weights, local hosting, or token cost at very high volume dominate the decision.
Claude Opus 4.7 is built for careful long-horizon reasoning
Claude Opus 4.7 is a more restrained release on the surface, but it may be the most interesting model for teams that care about sustained work quality over a long task horizon. Anthropic is not only competing on raw scores. It is competing on behavior: fewer tool errors, better self-verification, stronger handling of ambiguous instructions, high-resolution visual understanding, and more predictable agent loops.
Anthropic calls Opus 4.7 its most capable generally available model for complex reasoning and agentic coding. Its docs point to text and image input, multilingual use, vision, availability through Claude API, Amazon Bedrock, Vertex AI, and Microsoft Foundry, plus a clear migration path from Opus 4.6.
The most telling Anthropic claims are not the generic ones. They are the partner-specific comments around missing-data discipline, implicit-need handling, code review recall, tool failure recovery, dashboard creation, legal document handling, visual acuity, and long-running engineering work. In Anthropic’s launch page, Hex says Opus 4.7 correctly reports missing data rather than inventing plausible replacements. Notion says it improved multi-step workflows by 14% over Opus 4.6 with fewer tokens and a third of the tool errors. CodeRabbit says recall improved by over 10% on difficult code-review bugs. XBOW reports a large visual-acuity jump over Opus 4.6 for computer-use work.
Claude Opus 4.7’s high-resolution image support is a practical upgrade, not a side feature. Anthropic says the maximum image resolution increased to 2576px on the long edge and 3.75MP, up from 1568px and 1.15MP. That matters for screenshots, dashboards, dense PDFs, charts, UI inspection, document analysis, and computer-use tasks where small visual details change the answer.
The tradeoff is token behavior. Anthropic’s migration guide says Opus 4.7 uses a new tokenizer that may use roughly 1x to 1.35x as many tokens as Opus 4.6 for the same text, depending on content. It also says higher effort levels may generate more output tokens. Anthropic is candid here: the model may do better work, but some workloads will cost more unless prompts, effort settings, compaction, and task budgets are tuned.
Claude Opus 4.7 feels less like the cheapest model to call and more like the model to choose when mistakes are expensive, tasks are long, and the agent must keep its head.
DeepSeek V4 is built around open weights and cost pressure
DeepSeek V4 changes the comparison because it brings a different ownership model. GPT-5.5 and Claude Opus 4.7 are premium closed systems. DeepSeek V4 is a preview open-weights family with official API access, OpenAI and Anthropic API compatibility, 1M context, and two price tiers.
DeepSeek’s official release says V4-Pro has 1.6T total parameters and 49B active parameters, while V4-Flash has 284B total and 13B active. Both support 1M context and dual thinking and non-thinking modes. The API docs say developers can keep the same base URL and set the model parameter to deepseek-v4-pro or deepseek-v4-flash, with support for OpenAI ChatCompletions and Anthropic-style APIs.
The Hugging Face model page adds useful technical detail. DeepSeek describes V4 as a Mixture-of-Experts family using hybrid attention, combining compressed sparse attention and heavily compressed attention. In the 1M-token setting, DeepSeek says V4-Pro uses 27% of the single-token inference FLOPs and 10% of the KV cache of DeepSeek-V3.2. Those are vendor claims, but they point to the core design goal: make ultra-long context cheaper to serve.
The pricing is aggressive enough to force every buyer to recalculate. DeepSeek’s pricing page lists V4-Flash at $0.14 per 1M input tokens and $0.28 per 1M output tokens. It lists V4-Pro at $0.435 per 1M input and $0.87 per 1M output during a 75% discount through May 5, 2026, with struck-through full prices of $1.74 input and $3.48 output. Reuters also reported the 75% V4-Pro discount and the reduction of cache-hit pricing across DeepSeek’s API lineup.
That is the DeepSeek shock. Even if DeepSeek V4-Pro loses to GPT-5.5 or Claude Opus 4.7 on high-stakes closed-frontier tasks, its price and open access make it hard to ignore for retrieval, batch analysis, code assistance, agent experiments, local research, synthetic data workflows, and cost-sensitive products.
The weak point is trust and verification. AP reported that DeepSeek’s own evaluation suggests V4 is competitive, but analysts still want independent evaluations before final conclusions. AP also noted allegations from OpenAI and Anthropic that DeepSeek benefited from distillation of U.S. models, allegations China has pushed back against. Those disputes do not decide the technical quality of V4, but they affect enterprise risk, procurement, national-security review, and public perception.
Coding is now an agent benchmark, not a chatbot benchmark
A few years ago, “best coding model” often meant a model that could write a function or explain an error. That bar is too low now. The real coding contest is whether the model can operate as a software agent: inspect a repository, infer the real bug, edit files, run tests, interpret failures, fix regressions, and stop when the acceptance criteria are met.
GPT-5.5 has the clearest public Terminal-Bench signal among the three. OpenAI reports 82.7% on Terminal-Bench 2.0, and the public leaderboard lists Codex with GPT-5.5 at 82.0% ± 2.2. That is especially relevant because Terminal-Bench tasks force the model to work in a terminal environment, not merely produce code in a chat window.
Claude Opus 4.7’s coding case is more behavior-rich. AWS, summarizing Anthropic’s claims for Bedrock users, lists Opus 4.7 at 64.3% on SWE-bench Pro, 87.6% on SWE-bench Verified, and 69.4% on Terminal-Bench 2.0. Anthropic also frames Opus 4.7 as stronger at long-horizon autonomy, systems engineering, and complex code reasoning.
Those numbers create an interesting split. GPT-5.5 appears especially strong in Terminal-Bench-style tool execution, while Claude Opus 4.7 has a strong SWE-bench story and many partner claims around real coding workflows. If your coding agent lives in a terminal and runs multi-step command sequences, GPT-5.5 deserves first evaluation. If your work involves large refactors, code review, ambiguous product requirements, and careful validation, Opus 4.7 deserves equal testing.
DeepSeek V4 is harder to judge from independent public data at launch. DeepSeek claims V4-Pro is open-source SOTA in agentic coding benchmarks and world-class in Math, STEM, coding, and reasoning. Reuters reports that V4-Pro is positioned as comparable to leading closed models in agentic coding, STEM, world knowledge, and competitive programming, while still trailing top closed systems in some areas.
For developers, the better method is straightforward. Run each model on your own repository, with your own tests, against tasks your team actually fails on. Measure not only pass rate, but tool calls, retries, token use, human corrections, time to accepted pull request, and regression rate. Public coding benchmarks are useful filters. Your private harness decides the purchase.
Long context has become a product feature with hidden costs
All three models now advertise or document roughly 1M-token-class context. That looks like parity. It is not parity.
OpenAI’s GPT-5.5 API docs list a 1,050,000-token context window and 128,000 max output tokens. Anthropic’s Opus 4.7 documentation lists 1M context and 128K max output, with standard pricing across the full context window. DeepSeek’s V4 pricing docs list 1M context and a much larger 384K maximum output.
The headline number matters, but it hides three practical questions.
First, how much of that context does the model use well? Long context is not useful if the model misses the one clause, function, test, or table row that matters. Retrieval quality inside the context window is separate from the size of the window.
Second, how much does long context cost? GPT-5.5 and Claude Opus 4.7 both charge premium rates, though both support caching. DeepSeek V4’s long-context economics are far cheaper by token, and DeepSeek’s technical report claims architectural savings in FLOPs and KV cache for 1M-token workloads. Those savings may matter most in applications that repeatedly process large logs, codebases, transcripts, books, contracts, research corpora, or knowledge bases.
Third, does the product surface expose the full context? OpenAI’s ChatGPT and Codex availability may differ from API availability and model-card capacity. Anthropic’s Claude API, Bedrock, and product surfaces may also differ by integration. DeepSeek offers API and open weights, but self-hosting V4-Pro at useful speed is not trivial for most teams.
A 1M-token model is not a replacement for information architecture. You still need chunking, retrieval, ranking, deduplication, provenance, compaction, memory policy, and good context hygiene. Long context lets you carry more evidence into a task. It does not excuse dumping the whole company drive into a prompt and hoping the model behaves like a database.
Tool use separates polished demos from useful agents
Tool use is where these models stop being writers and start behaving like workers. A tool-heavy agent has to decide when to search, when to run code, when to inspect a file, when to call a database, when to ask for clarification, when to continue, and when to stop. That chain is fragile.
OpenAI’s GPT-5.5 guide says the model is stronger and more precise in tool use, especially across large tool surfaces, multi-step service workflows, and long-running agent tasks. It recommends the Responses API for reasoning, tool-calling, and multi-turn use cases, and tells developers to tune reasoning effort, tool descriptions, verbosity, preambles, and assistant-item replay.
Anthropic’s Opus 4.7 migration guide describes a different control philosophy. It pushes developers toward adaptive thinking and effort levels, removes manual extended thinking budgets, removes non-default sampling parameters, and adds stricter effort calibration. It also says Opus 4.7 uses fewer tool calls by default and more reasoning, with tool use rising at higher effort levels.
DeepSeek V4 focuses on API compatibility and developer access. Its docs say the API supports both OpenAI ChatCompletions and Anthropic interfaces, along with JSON output, tool calls, and chat prefix completion. That compatibility is powerful because it lets teams test DeepSeek without fully rewriting their integration layer.
The tool-use winner depends on your product architecture. OpenAI will appeal to teams already invested in OpenAI’s Responses API, Codex, hosted tools, and ChatGPT surfaces. Anthropic will appeal to teams that want a tighter agent-control model with adaptive thinking, explicit effort settings, strong computer-use heritage, and enterprise cloud distribution. DeepSeek will appeal to builders who want lower cost, API interchangeability, and the option to inspect or self-host open weights.
The most mature teams will not choose only one. They will route. GPT-5.5 might handle high-stakes execution, Claude Opus 4.7 might handle document-heavy reasoning and visual workflows, DeepSeek V4-Flash might handle cheap first-pass retrieval or classification, and DeepSeek V4-Pro might serve open-weight research or cost-sensitive agent work.
Multimodal work favors the model with the right visual pipeline
The AI race is no longer text-only. Screenshots, PDFs, diagrams, charts, forms, maps, legal exhibits, medical images, industrial dashboards, financial filings, slide decks, and UI states are now part of routine model input. Vision quality is becoming a deciding feature for business AI.
Claude Opus 4.7 has the clearest visual upgrade story among the three in this launch cycle. Anthropic says Opus 4.7 is its first Claude model with high-resolution image support, raising maximum resolution to 2576px on the long edge and 3.75MP. The company specifically calls out computer use, screenshots, artifacts, and document understanding. The migration guide also warns that full-resolution images can use up to roughly three times more image tokens than prior Claude models.
GPT-5.5 supports text and image input according to OpenAI’s model docs, and OpenAI’s ChatGPT Help Center says GPT-5.5 Thinking supports image analysis and file analysis in eligible ChatGPT plans, subject to the Pro exception it lists for some tools.
DeepSeek V4’s launch materials focus much more on text, reasoning, coding, long context, and agents than on multimodal capability. That does not make it weak for every visual-adjacent workflow, since teams can combine DeepSeek with OCR, document parsing, or separate vision models. But as a single-model choice for dense visual reasoning, Claude Opus 4.7 and GPT-5.5 deserve earlier testing.
The practical split is clear. Claude Opus 4.7 looks especially attractive for visual work where tiny details matter, such as UI debugging, chart reading, dense document review, and computer-use tasks. GPT-5.5 may be stronger when the visual work is only one step inside a broader execution pipeline. DeepSeek V4 is better treated as a text-first and code-first open model unless your own tests prove otherwise.
Pricing tells a different story than benchmark scores
Pricing is where DeepSeek V4 changes the market. It is easy to admire benchmark leadership until the monthly bill arrives. The best model for a one-off task may not be the best model for a product that sends hundreds of millions of tokens through agent loops.
OpenAI lists GPT-5.5 at $5 per 1M input tokens, $0.50 cached input, and $30 per 1M output tokens. Anthropic lists Claude Opus 4.7 at $5 input, $0.50 cache hits and refreshes, and $25 output per 1M tokens. DeepSeek lists V4-Flash at $0.14 input and $0.28 output, while V4-Pro is listed at $0.435 input and $0.87 output during the temporary discount, with full prices of $1.74 input and $3.48 output.
The gap is enormous. GPT-5.5 output is roughly 34 times the discounted V4-Pro output price and more than 100 times the V4-Flash output price. Even DeepSeek V4-Pro’s listed post-discount output price remains far below GPT-5.5 and Claude Opus 4.7.
Yet cheap tokens can become expensive if the model needs many retries, produces unusable answers, misses safety requirements, or requires extra engineering support. Premium tokens can become cheap if they finish the task once, reduce human review, and avoid costly errors. The correct metric is accepted work per dollar, not tokens per dollar.
For a startup building a coding assistant, the choice may start with DeepSeek V4-Flash or V4-Pro for broad usage and route hard cases to GPT-5.5 or Claude Opus 4.7. For a bank, law firm, insurer, or healthcare organization, the cost of a bad answer may dwarf token price. For a research lab, open weights may matter more than hosted convenience. For a large enterprise, procurement, security review, regional deployment, audit logs, and data handling may matter more than the model leaderboard.
The market implication is harsher for OpenAI and Anthropic than for buyers. DeepSeek has made low-cost long-context reasoning a credible default to test. Closed frontier vendors now have to prove that their higher prices produce lower total operating cost in real workflows.
Enterprise adoption depends on controls, deployment, and ecosystem
Enterprises rarely buy a raw model. They buy a deployment path, a risk posture, a support relationship, a governance story, and a way to fit the model into existing systems. This is where OpenAI and Anthropic still have strong advantages over DeepSeek, even when DeepSeek wins on price.
OpenAI’s advantage is distribution through ChatGPT, Codex, the API, and a broad developer ecosystem. The ChatGPT Help Center describes GPT-5.5 Thinking access for eligible paid plans and GPT-5.5 Pro for higher tiers, with tools such as web search, data analysis, image analysis, file analysis, Canvas, image generation, Memory, and Custom Instructions in supported modes. The API docs then add model-level controls such as reasoning effort and pricing details.
Anthropic’s advantage is enterprise cloud coverage and a clear agent platform story. Its docs say Claude models are available through Claude API, Amazon Bedrock, Vertex AI, and Microsoft Foundry. Anthropic release notes say Claude Opus 4.7 and Claude Haiku 4.5 are available self-serve in Amazon Bedrock through the Messages API in 27 AWS regions with global and regional endpoints. AWS’s own Bedrock launch page reinforces Opus 4.7’s role in agentic coding, long-running tasks, knowledge work, and vision.
DeepSeek’s advantage is developer portability. Its API can be used through OpenAI-style and Anthropic-style formats. That is a smart move because switching costs often stop model experimentation. DeepSeek is telling developers: keep your SDK pattern, change the base URL and model name, then test.
For enterprise buyers, the ranking changes by workload. A team that wants a governed assistant inside existing productivity and coding tools may prefer OpenAI. A team standardizing AI inside AWS, Google Cloud, or Microsoft ecosystems with serious agentic coding use may prefer Anthropic. A team that wants lower cost, self-hosting options, or market leverage against closed-model vendors will test DeepSeek.
The enterprise winner is rarely the model with the loudest launch. It is the model that passes security review, fits the workflow, keeps costs predictable, and fails in ways the organization can manage.
Open weights change the strategic value of DeepSeek V4
DeepSeek V4’s open-weights release changes its value even when it does not win every benchmark. Open weights give researchers and developers something closed models do not: the ability to inspect, host, modify, fine-tune, quantize, benchmark, and deploy outside a vendor-controlled black box.
That matters for universities, sovereign AI programs, regulated industries, defense-adjacent research, on-premise customers, startups trying to avoid API dependency, and developers in regions where U.S. model access is costly, restricted, or unstable. Open weights turn the model from a service into infrastructure.
The DeepSeek V4-Pro Hugging Face page lists model downloads for V4-Flash, V4-Flash-Base, V4-Pro, and V4-Pro-Base, with mixed precision variants and 1M context. The release page links to open weights on Hugging Face and positions the V4 family as open-sourced.
The tradeoff is operational difficulty. Running V4-Pro is not like calling a hosted API. A 1.6T total parameter MoE model, even with only 49B active parameters, demands serious infrastructure for useful throughput. Smaller teams may get more value from DeepSeek’s hosted API or V4-Flash than from self-hosting V4-Pro. Communities will likely produce quantized versions, optimized runtimes, deployment recipes, and fine-tuned variants, but those bring their own reliability and security concerns.
Open weights also create governance questions. A company can audit and control deployment more tightly, but it also takes more responsibility for safety filters, logging, access control, abuse prevention, and model updates. Closed systems shift much of that burden to the provider. Open systems hand more power to the user, which is exactly why they are attractive and exactly why they need care.
DeepSeek V4 is strategically important even if a buyer still uses GPT-5.5 or Claude Opus 4.7 for premium tasks. It becomes the price anchor, the open fallback, the research base, and the pressure point in vendor negotiations.
Safety posture is no longer a side note
Frontier-model safety used to be treated as a separate policy section. That no longer works. These models can write code, call tools, reason over long context, analyze biology and security material, and operate more autonomously. Safety posture now affects availability, API access, enterprise trust, and which workloads a model is allowed to handle.
OpenAI’s GPT-5.5 system card says the company subjected the model to predeployment safety evaluations and its Preparedness Framework, including targeted red-teaming for advanced cybersecurity and biology capabilities. OpenAI says it collected feedback from nearly 200 early-access partners before release and is deploying GPT-5.5 with its strongest safeguards to date.
Anthropic’s Opus 4.7 release sits inside a company that has made safety branding central to its identity. The public system-cards page lists a Claude Opus 4.7 system card dated April 2026. Anthropic’s migration guide also says Opus 4.7 has real-time cybersecurity safeguards and that legitimate security professionals can apply to the Cyber Verification Program for reduced restrictions.
Anthropic’s safety story also includes friction. The company published a postmortem on recent Claude Code quality reports, saying product-level issues affected user experience around Opus 4.7’s launch, including a cache optimization bug, a reasoning-level change, and a system-prompt change to reduce verbosity that caused measurable degradation in one evaluation. Anthropic said it reverted the prompt on April 20 and changed internal processes. That post is useful because it shows that model quality is not only model weights. Product harnesses, prompts, defaults, cache behavior, and context access can degrade the user experience even when the core model remains strong.
DeepSeek V4’s safety and governance picture is more complex for international buyers. Open weights increase user control but reduce vendor-enforced central control. AP’s report notes ongoing allegations from OpenAI and Anthropic around distillation, and it also says independent evaluations are still needed before final conclusions on V4 performance. For enterprise buyers outside China, legal, compliance, data-sovereignty, and procurement teams will ask hard questions.
External governance frameworks matter here. NIST’s Generative AI Profile for the AI Risk Management Framework is designed to help organizations identify and manage generative AI risks. ISO/IEC 42001 provides a management-system standard for organizations developing or using AI systems. These frameworks do not pick a model, but they give buyers a better lens than hype: map use cases, measure risk, manage controls, document suppliers, test failure modes, and audit outcomes.
Benchmark claims need heavier skepticism
Every frontier launch now arrives with a wall of numbers. Some are public. Some are vendor-run. Some are partner-run. Some use custom harnesses. Some are not yet independently replicated. Benchmarks are useful, but the farther they get from your workload, the less authority they deserve.
GPT-5.5 has strong official claims and at least one strong public leaderboard signal through Terminal-Bench. Still, OpenAI’s 82.7% number and Terminal-Bench’s public 82.0% number are not identical, likely due to harness or reporting differences. That is not a scandal; it is normal benchmark reality. Details matter: agent wrapper, tools, time limits, retries, environment, pass criteria, and whether the model can use hidden scaffolding.
Claude Opus 4.7 has many partner claims and strong reported coding scores. Those are useful, but partner tests tend to reflect specific production environments. They may be more relevant than public benchmarks for similar companies and less relevant for everyone else. A CodeRabbit bug-detection harness does not automatically predict legal drafting. A Notion agent workflow does not automatically predict financial research. A visual-acuity benchmark does not automatically predict medical image reasoning.
DeepSeek V4 has the greatest need for outside testing at launch. DeepSeek’s own claims are ambitious, and the pricing is real, but independent evaluations will decide how often V4 can replace closed frontier models in demanding work. AP quoted an analyst saying independent evaluations are needed before final conclusions, and that is the correct stance.
The best benchmark strategy is layered. Start with public benchmarks to narrow the field. Add vendor and partner claims for context. Then run a private evaluation with your actual documents, code, policies, tools, languages, latency targets, and review rules. Track not only success rate but also false confidence, refusal quality, citation discipline, output length, tool-call waste, hidden failure patterns, and human correction time.
The model that wins the public chart may not win your production harness. The model that looks expensive per token may be cheaper per accepted workflow. The model that looks cheap may become costly if it needs too much supervision.
The best choice for developers, enterprises, and researchers
For developers building code agents, GPT-5.5 is the most natural first test if the workflow depends on terminal execution, Codex integration, tool-rich debugging, and high success on multi-step command-line tasks. Claude Opus 4.7 deserves equal testing when the work involves large codebases, design judgment, careful review, long agent runs, and visual UI inspection. DeepSeek V4-Pro and V4-Flash should be tested when cost, open weights, or self-hosting matter.
For enterprise knowledge work, Claude Opus 4.7 and GPT-5.5 are closer. GPT-5.5 has a broad professional-work pitch and strong results on work simulation benchmarks. Claude Opus 4.7 has a strong story around careful handling of missing data, finance workflows, legal review, long context, and document-heavy reasoning. DeepSeek V4 may serve as a low-cost engine for first-pass analysis, retrieval over large material, translation-like tasks, and internal experiments, but sensitive use cases need a formal risk review.
For research teams, DeepSeek V4 is the most interesting from an inspectability standpoint. Open weights make it possible to study architecture, fine-tuning behavior, long-context mechanics, compression tradeoffs, safety scaffolds, and deployment cost. GPT-5.5 and Claude Opus 4.7 may still be stronger research assistants for many tasks, but they are not open research artifacts in the same way.
For startups, the decision is strategic. A GPT-5.5-only product may deliver strong quality fast but face high token costs. A Claude-first product may win on reliability and enterprise trust but require careful effort and token tuning. A DeepSeek-first product may crush cost targets but require more product engineering, fallback routing, safety layers, and quality review.
For agencies, consultants, and marketing teams, GPT-5.5 likely wins where polished synthesis, document production, spreadsheet help, and tool-based research matter. Claude Opus 4.7 may win where long editorial judgment, structured document interpretation, and careful ambiguity handling matter. DeepSeek V4 may win on internal drafting, multilingual scale, and cheap document processing, especially if output quality is reviewed by humans.
The broader market signal behind the three launches
These launches show that the AI market is splitting along three axes.
The first axis is closed premium intelligence. OpenAI and Anthropic both want customers to pay more for fewer failures, stronger work completion, better tools, and safer deployment. They are not only selling tokens. They are selling confidence.
The second axis is agent infrastructure. All three releases speak the language of agents: coding workflows, tool calls, long context, computer use, API compatibility, autonomous task execution, and recovery from failures. The next competitive line is not who can answer a prompt. It is who can run a bounded task loop without breaking trust.
The third axis is sovereign and open model pressure. DeepSeek V4’s Huawei adaptation and open-weights release show a future where frontier-like AI is not controlled only by U.S. closed-model providers. Reuters framed V4 as part of China’s push toward AI infrastructure self-sufficiency, while AP described V4 as a response to U.S. competitors and a symbol of intensified AI rivalry.
That split will shape buying behavior. Large enterprises may keep premium closed models for high-risk work while moving cheaper tasks to open or low-cost models. Governments may build domestic stacks around open models. Developers may use routing layers across GPT, Claude, DeepSeek, Gemini, Qwen, Kimi, and smaller specialized models. Model loyalty will weaken as evaluation and routing improve.
The age of choosing one “best AI model” is giving way to model portfolios. The winning organization will know which model to use for which task, at which effort level, under which safety policy, with which fallback, and at what acceptable cost.
GPT-5.5 vs Claude Opus 4.7 vs DeepSeek V4 by workload
A practical comparison needs workload-level answers. A model can be excellent for one job and wasteful for another.
Workload fit summary
| Workload | Best first model to test | Reason |
|---|---|---|
| Terminal-based coding agents | GPT-5.5 | Strong public Terminal-Bench signal and Codex alignment |
| Large code review and careful refactoring | Claude Opus 4.7 | Strong partner claims around bug recall, validation, and long-running coding |
| Cheap large-scale text processing | DeepSeek V4-Flash | Very low token price and 1M context |
| Open-weight research and self-hosted experiments | DeepSeek V4-Pro | Open weights, large MoE design, long-context architecture |
| Dense screenshot and document vision | Claude Opus 4.7 | High-resolution image support and computer-use orientation |
| Professional mixed workflows | GPT-5.5 | Strong positioning across coding, research, documents, tools, and execution |
| Enterprise cloud deployment on AWS | Claude Opus 4.7 | Bedrock availability and Anthropic enterprise distribution |
| Budget-sensitive agent products | DeepSeek V4-Pro or V4-Flash with fallback routing | Low price, API compatibility, and routeable architecture |
This table is not a final verdict. It is a testing order. Each team should run a private evaluation with real prompts, files, tools, user roles, latency targets, and review standards before standardizing on any model.
The table also shows why a single answer is weak. A team may use GPT-5.5 for high-value agent tasks, Claude Opus 4.7 for careful reasoning and visual work, and DeepSeek V4-Flash for cheap background processing. That routing pattern may beat any single-model deployment on cost and quality.
The hidden migration work behind each model
A model upgrade is not a model-name swap. Every provider now says this in its own way.
OpenAI’s GPT-5.5 guide tells developers to start with a fresh baseline, tune reasoning effort, verbosity, tool descriptions, and output format, and benchmark against accuracy, token use, and latency. It also says coding agents should be explicit about reuse, subagent delegation, tests, acceptance criteria, and continuation rules.
Anthropic’s migration guide is even more concrete. Claude Opus 4.7 removes manual extended-thinking budgets, removes non-default sampling parameters, omits thinking content by default unless configured, changes token counting, and requires care with effort levels. It also introduces behavior shifts such as more literal instruction following, more direct tone, fewer subagents by default, and fewer tool calls by default.
DeepSeek’s migration story is simpler on the surface because of API compatibility. Developers can use OpenAI or Anthropic-style APIs. But simplicity at the API layer does not remove evaluation work. DeepSeek V4 may differ in tool-call formatting, refusal behavior, output style, factuality, long-context retrieval, JSON reliability, latency, and safety performance. If a team uses open weights, the migration work expands into infrastructure, inference serving, quantization, monitoring, access control, and abuse prevention.
The serious cost of switching models is not the SDK edit. It is the retesting of every assumption your product made about model behavior. That includes formatting, hidden reasoning patterns, verbosity, hallucination shape, retrieval discipline, refusal tone, tool-call eagerness, and failure recovery.
The teams that benefit most from this model race will be the ones with portable evaluation harnesses. They will not ask “which model is best?” once per quarter. They will continuously test models against real tasks and route work based on live evidence.
The final verdict is not one model wins everything
GPT-5.5 looks like the strongest all-around pick for execution-heavy professional work, especially where coding agents, tool use, and polished task completion matter. It has the strongest visible Terminal-Bench story and a broad work-oriented launch narrative. Its premium price makes sense only when it reduces retries and human correction enough to lower total cost.
Claude Opus 4.7 looks like the best pick for careful long-horizon work, especially coding review, complex reasoning, document-heavy tasks, visual analysis, and enterprise deployments that need strong controls. It is not the cheapest model, and its tokenizer and effort behavior require cost tuning, but it may be the model teams trust when the task is messy and failure is expensive.
DeepSeek V4 looks like the most disruptive pick for cost-sensitive, open, long-context AI, especially for developers and researchers who value open weights, API compatibility, and low token prices. It is not yet as independently proven as the closed leaders, and self-hosting V4-Pro is not easy, but it changes the economics of the field.
The best model choice after these launches is a routing decision, not a loyalty decision. Use GPT-5.5 where execution quality earns its price. Use Claude Opus 4.7 where careful reasoning and controlled agents matter. Use DeepSeek V4 where open access, long-context cost, and deployment control change the business case.
The frontier AI race has stopped being a single scoreboard. It is now a fight between three futures: closed premium execution, governed enterprise autonomy, and open low-cost scale. The winner depends on which future your work needs.
Questions readers are asking after the three launches
Yes. OpenAI announced GPT-5.5 on April 23, 2026 and describes it as a frontier model for coding, research, data analysis, tool-heavy work, and professional tasks. OpenAI’s docs and pricing pages list GPT-5.5 model details, context size, token pricing, and usage guidance.
Yes. Anthropic announced Claude Opus 4.7 on April 16, 2026 and calls it its most capable generally available model for complex reasoning and agentic coding. The model is documented in Anthropic’s model overview, pricing docs, migration guide, and system-card index.
Yes. DeepSeek published the DeepSeek V4 Preview release on April 24, 2026. The release includes DeepSeek-V4-Pro and DeepSeek-V4-Flash, both with 1M context and official API access. DeepSeek also links to open weights on Hugging Face.
There is no honest single-model answer. GPT-5.5 looks strongest for tool-heavy professional execution and terminal-style coding agents. Claude Opus 4.7 looks strongest for careful long-horizon reasoning, enterprise agent work, and high-resolution visual understanding. DeepSeek V4 is strongest on open weights, long-context cost, and deployment freedom.
GPT-5.5 has the strongest visible Terminal-Bench 2.0 signal, while Claude Opus 4.7 has strong reported SWE-bench and partner workflow results. DeepSeek V4-Pro may be very strong for open-model coding, but it needs more independent public testing before it can be treated as a proven replacement for the top closed models in demanding software work.
DeepSeek V4 is far cheaper by listed token price. DeepSeek V4-Flash is especially cheap at $0.14 input and $0.28 output per 1M tokens. V4-Pro is also much cheaper than GPT-5.5 or Claude Opus 4.7, even before considering the temporary 75% discount window that ends on May 5, 2026.
All three are in the 1M-token class. GPT-5.5 is listed with a 1,050,000-token context window and 128,000 max output. Claude Opus 4.7 has 1M context and 128K max output. DeepSeek V4 has 1M context and lists a maximum output of 384K tokens.
Claude Opus 4.7 and GPT-5.5 should both be tested for premium long-document work. Claude may have an edge when careful interpretation, missing-data discipline, and document vision matter. DeepSeek V4 is attractive for cheap long-context processing, but high-stakes document work still needs testing, citation checks, and human review.
Claude Opus 4.7 has the strongest explicit visual upgrade in this comparison, with high-resolution image support up to 2576px on the long edge. GPT-5.5 supports image input and image analysis in supported surfaces. DeepSeek V4’s launch messaging is less focused on vision.
It depends on the enterprise stack. OpenAI is strong for ChatGPT, Codex, and OpenAI API workflows. Anthropic is strong for Claude API, Amazon Bedrock, Vertex AI, Microsoft Foundry, and agentic coding deployments. DeepSeek is strong for cost-sensitive and open-weight strategies, but enterprise buyers may need extra legal, security, and governance review.
Not across the board based on current evidence. DeepSeek claims V4-Pro is the leading open model and approaches top closed models in some areas, but AP and Reuters both frame the strongest claims as needing outside validation. DeepSeek’s clearest lead is cost and open-weight access, not proven universal superiority.
Open weights let developers and researchers inspect, host, modify, fine-tune, quantize, and deploy the model outside a closed API. That matters for research, sovereignty, procurement control, offline use, and cost management. The tradeoff is that the user takes more responsibility for safety, monitoring, infrastructure, and updates.
OpenAI and Anthropic are selling premium closed-model systems with support, managed infrastructure, safety controls, mature product surfaces, and enterprise integrations. DeepSeek is pushing a lower-cost and open-access model. The real comparison is accepted work per dollar, not token price alone.
A startup should test DeepSeek V4 early because the cost difference is too large to ignore. A safe production pattern is often routing: use DeepSeek for cheap first-pass or high-volume work, then route hard or high-risk tasks to GPT-5.5 or Claude Opus 4.7.
Possibly, but not as a default without review. The model’s cost and context length are attractive, but legal, financial, and regulated work needs strict controls around confidentiality, provenance, vendor risk, jurisdiction, auditability, and error handling. GPT-5.5 or Claude Opus 4.7 may be easier to approve in many enterprise settings.
GPT-5.5 appears strongest for execution-heavy agents and command-line workflows. Claude Opus 4.7 appears strongest for careful, controlled, long-running agents with strong reasoning and visual understanding. DeepSeek V4 is attractive for low-cost agent experiments and open deployments.
No. Benchmarks are a first filter. A team should run its own evaluation on real tasks, tools, files, languages, latency targets, review standards, and failure cases. The production winner is the model that produces the most accepted work with acceptable risk and cost.
Build a model portfolio. Test GPT-5.5, Claude Opus 4.7, DeepSeek V4-Pro, and DeepSeek V4-Flash against your own work. Route tasks by difficulty, risk, cost, privacy, and required tools. Keep fallback models ready. Re-test often because model behavior and pricing are changing quickly.
For coding agents, start with GPT-5.5 and Claude Opus 4.7 side by side, then test DeepSeek V4-Pro for cost pressure. For document-heavy enterprise reasoning, start with Claude Opus 4.7 and GPT-5.5. For low-cost long-context scale or open research, start with DeepSeek V4.
A single-model monopoly looks less likely after these releases. The market is moving toward routing, specialization, and model portfolios. Premium closed models will keep winning high-value tasks, while cheaper open models will absorb more high-volume work.
Author:
Jan Bielik
CEO & Founder of Webiano Digital & Marketing Agency

This article is an original analysis supported by the sources cited below
Introducing GPT-5.5
OpenAI’s official launch article for GPT-5.5, including benchmark claims, product positioning, and capability framing for coding, research, and professional work.
GPT-5.5 System Card
OpenAI’s system card for GPT-5.5, covering model purpose, predeployment safety evaluations, red-teaming, and release safeguards.
GPT-5.5 Model
OpenAI’s developer model page for GPT-5.5, including context size, output limit, supported input types, and token pricing details.
OpenAI API Pricing
OpenAI’s official API pricing page used to verify GPT-5.5 input, cached input, and output token prices.
GPT-5.3 and GPT-5.5 in ChatGPT
OpenAI Help Center article describing GPT-5.5 availability in ChatGPT, model picker behavior, plan access, and supported tools.
Using GPT-5.5
OpenAI’s migration and usage guide for GPT-5.5, including prompt guidance, reasoning effort, tool use, and production workflow advice.
Our updated Preparedness Framework
OpenAI’s official Preparedness Framework update, used for context on how OpenAI evaluates and manages frontier-model risk.
Introducing Claude Opus 4.7
Anthropic’s official launch article for Claude Opus 4.7, including partner evaluations, coding claims, long-running workflow examples, and product positioning.
Claude Opus 4.7
Anthropic’s product page for Claude Opus 4.7, describing the model as a hybrid reasoning model for coding, agents, and 1M-context work.
What’s new in Claude Opus 4.7
Anthropic’s technical documentation for Opus 4.7 changes, including high-resolution image support and related implementation details.
Models overview
Anthropic’s Claude model overview, used to verify Opus 4.7 positioning, model ID, supported modalities, and deployment channels.
Pricing
Anthropic’s official pricing documentation for Claude Opus 4.7 input, output, prompt caching, and batch pricing.
Claude Platform release notes
Anthropic’s release notes confirming the Claude Opus 4.7 launch, pricing continuity, API changes, and Bedrock availability.
Migration guide
Anthropic’s migration guide for Claude Opus 4.7, used to verify context length, adaptive thinking, tokenizer changes, effort levels, and breaking API changes.
Model system cards
Anthropic’s public index of model system cards, including the April 2026 Claude Opus 4.7 system card entry.
An update on recent Claude Code quality reports
Anthropic’s engineering postmortem on Claude Code quality issues around the Opus 4.7 launch, including prompt, cache, and reasoning-default findings.
Introducing Anthropic’s Claude Opus 4.7 model in Amazon Bedrock
AWS’s launch article for Claude Opus 4.7 in Amazon Bedrock, used for deployment, benchmark, and enterprise-access context.
Responsible Scaling Policy Version 3.0
Anthropic’s official update on its Responsible Scaling Policy, used for context on AI Safety Levels and frontier-model governance.
DeepSeek V4 Preview Release
DeepSeek’s official V4 Preview announcement, including V4-Pro and V4-Flash parameters, 1M context, API availability, and open-weight links.
Change Log
DeepSeek’s API change log confirming V4-Pro and V4-Flash support, model parameters, and retirement timing for legacy model names.
Models and Pricing
DeepSeek’s official pricing page for V4-Flash and V4-Pro, including input, cache-hit, output prices, 1M context, max output, and temporary V4-Pro discount.
Your First API Call
DeepSeek’s API quick-start guide, used to verify OpenAI-format and Anthropic-format base URLs, supported model names, and integration approach.
DeepSeek-V4-Pro
DeepSeek’s Hugging Face model page, used for technical details on parameters, active parameters, architecture, context length, and open model downloads.
DeepSeek-V4, the Chinese AI model adapted for Huawei chips
Reuters reporting on DeepSeek V4’s Huawei chip adaptation, V4-Pro and V4-Flash positioning, long-context support, and China’s AI infrastructure push.
China’s DeepSeek launches an update of its AI model
AP coverage of DeepSeek V4, including independent analyst reactions, benchmark caution, open-source positioning, and geopolitical context.
China’s DeepSeek slashes prices for new AI model
Reuters report on DeepSeek’s V4-Pro discount and API cache-hit price reductions following the V4 launch.
Terminal-Bench 2.0 leaderboard
The public Terminal-Bench 2.0 leaderboard used to cross-check GPT-5.5’s performance in terminal-based agentic coding tasks.
Artificial Intelligence Risk Management Framework Generative Artificial Intelligence Profile
NIST’s Generative AI profile for the AI Risk Management Framework, used for governance and risk-management context.
ISO/IEC 42001:2023
ISO’s AI management system standard, used for context on organizational AI governance, risk management, and responsible deployment.