

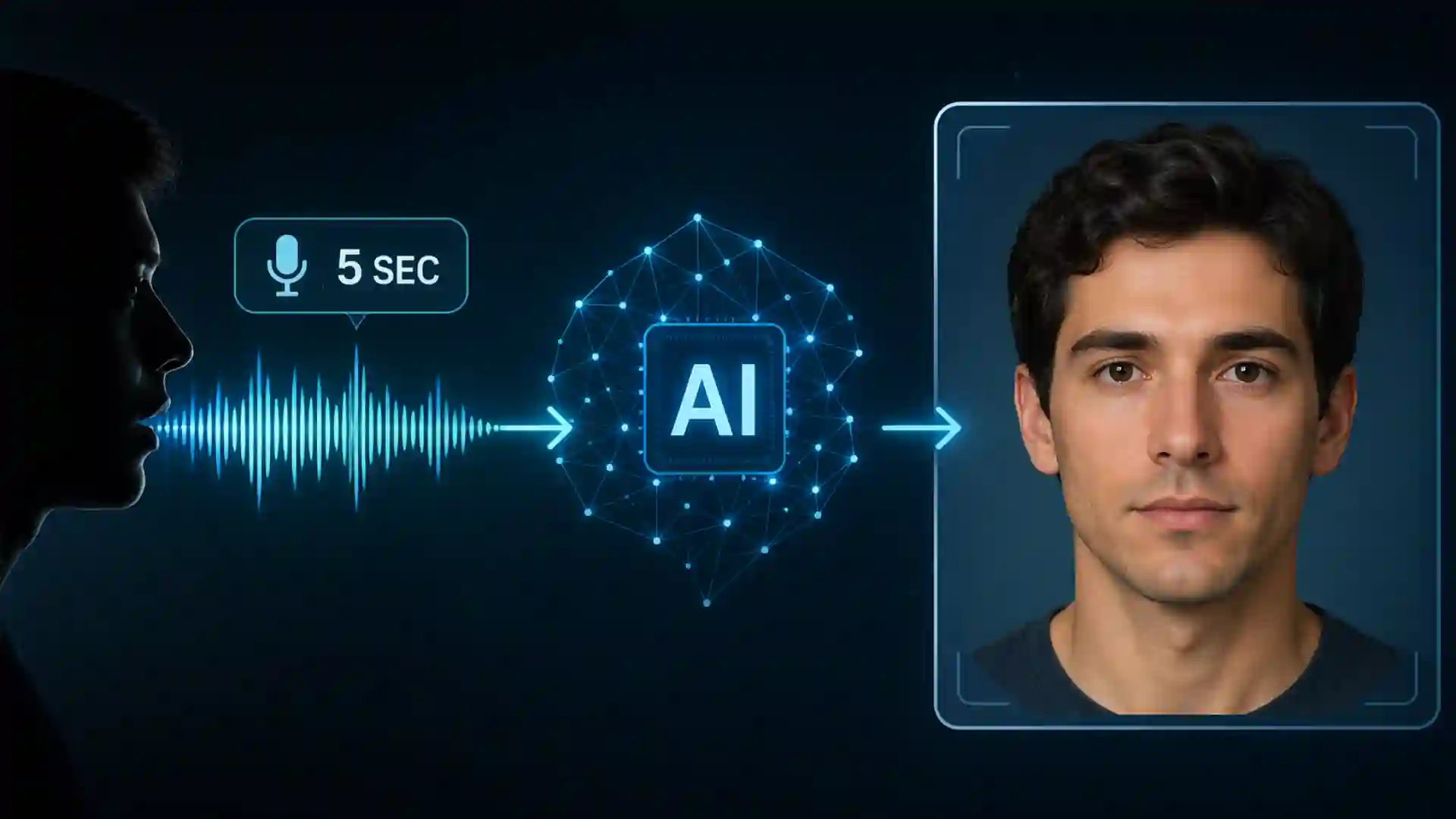
For years, the idea sounded like a party trick dressed up as science. Hear a few seconds of speech, press a button, get a face. Yet that is now a real research problem with a clear technical lineage. MIT’s Speech2Face project showed in 2019 that a model trained on huge volumes of paired web video could generate a frontal, neutral face from a short clip of speech. Since then, newer systems have pushed the same task with stronger cross-modal learning and diffusion-based generation, producing portraits that are sharper, more coherent, and more convincing to human eyes.
Table of Contents
That does not mean AI can pull a hidden photograph out of your voice like a forensic scanner. The stronger claim is different, and in some ways more unsettling. A voice carries enough information for a model to infer probable facial traits rather than a true identity: broad age cues, sex-linked vocal features, some ethnicity-linked patterns, and even a few craniofacial correlations. The generated image is best understood as a statistical portrait built from patterns in training data, not a recovered likeness. That distinction matters because the pictures can still feel deeply personal, even when they are not literally “you.”
The claim sounds wilder than it is
A large part of the public confusion comes from the way the achievement gets described. Headlines often imply that AI has learned to identify a person from voice alone and then render their actual face. That is not what the foundational research says. The Speech2Face authors were unusually direct about this: there is no one-to-one mapping between faces and voices, and their goal was not to reconstruct an exact, recognizable individual. Their system aimed to recover dominant visual traits correlated with speech, producing an average-looking face in a canonical pose and expression.
That framing lines up with an older body of work on face-voice association. Before the image generators arrived, researchers were already testing whether humans and machines could match unfamiliar faces and voices better than chance. MIT researchers showed in 2018 that people could do this above chance accuracy and that machine-learned cross-modal representations could capture overlapping information between the two signals at roughly human-comparable performance. The current generation of image models did not invent the link between voices and faces. It operationalized it.
This is why the result feels eerie without being magical. Human beings already make fast judgments from a voice. We guess age, sex, confidence, social background, sometimes even face shape, often with too much confidence and uneven accuracy. A model trained on millions of paired examples can formalize the same correlations at scale. The unsettling part is not that the machine possesses mystical insight. The unsettling part is that ordinary speech leaks more embodied information than most people assume, and machine learning is very good at harvesting weak signals that humans only sense intuitively.
The difference between intuition and automation is the real story. A person hears a voice and imagines a face, then forgets the guess. A trained system can do that millions of times, keep the pattern, improve it, and embed it inside products. That turns a vague social habit into a scalable technical capability. Once that shift happens, the debate changes from “is this possible?” to “what should be done with it, who benefits, and who absorbs the risk?”

What a short voice clip really contains
Speech is not just language. It is also anatomy, habit, health, environment, and social history compressed into sound. The Speech2Face paper points to obvious examples: age, pitch differences related to sex, mouth shape, bone structure, and lip configuration all affect the way speech is produced. The model learned from that overlap rather than from a hand-coded theory of faces. It was trained end to end on naturally co-occurring speech and faces from internet video, letting the network discover which audio patterns map to which visual traits.
That does not make the output stable or pure. The same paper also reports mixed behavior around accent, spoken language, and pitch. A high-pitch male voice can push the model toward female-looking facial features. A speaker using a language or accent not aligned with the model’s learned assumptions can generate mismatched ethnicity cues. In other words, the model is not extracting a timeless biological truth from audio. It is learning a bundle of correlations, some anatomical, some demographic, some cultural, some plainly biased.
What the model is doing and what it is not doing
| What the model is doing | What many people assume it is doing |
|---|---|
| Predicting facial traits correlated with speech | Reconstructing the speaker’s exact face |
| Producing a canonical, average-looking portrait | Recovering a hidden photo or mugshot |
| Learning from population-level patterns in paired data | Revealing ground-truth biological identity |
| Reflecting the biases of its training set | Delivering neutral, courtroom-grade evidence |
That distinction is not academic. A statistically plausible face can still shape human judgment. If a hiring manager, police analyst, fraud investigator, or call-center worker sees a generated portrait, they may treat it as evidence even when the model was never designed to identify a specific person. The risk sits right there: a soft, probabilistic output can harden into a social fact once it reaches a screen and a human decision-maker.
Another point often missed is that “brief audio clip” is not a metaphor. The MIT system was publicly described as working from around five seconds of speech, and the underlying research evaluated short clips in the three- to six-second range. That is a tiny amount of data by human standards. A short voicemail, a clipped social video, a customer service call opener, or a few words lifted from a livestream may already be enough to feed a model in this family.
The lab prototypes that made the idea real
The early systems were only possible because researchers had access to huge paired audio-video corpora. Speech2Face was trained on millions of internet and YouTube speaking videos. The broader ecosystem also depends on datasets such as AVSpeech and VoxCeleb, both assembled from web video at scale. AVSpeech describes itself as a large audio-visual dataset of speech clips with a single visible speaker and no interfering background noise, totaling roughly 4,700 hours from about 290,000 YouTube videos. VoxCeleb likewise consists of short speech clips extracted from interview videos uploaded to YouTube.
Those datasets did two things at once. They made cross-modal learning feasible, and they locked the field into the biases of internet media. Celebrity interviews, public talks, broadcast appearances, tutorial videos, and online speaking footage are not a neutral sample of the human voice. They overrepresent the camera-ready, the publicly visible, the linguistically dominant, and the already documented. The model does not learn “people.” It learns the people who show up in the data.
The first generation of models also kept the task narrow in a smart way. Speech2Face did not try to generate a full unconstrained portrait with hairstyle, pose, background, or expression. It generated a canonical face: frontal-facing, neutral, normalized. That choice removed some obvious variables and let the model focus on the core correlation between audio and facial structure. It also explains why the output often looks generic. The system was designed to strip the image down to a controlled visual proxy, not a natural photograph of a living moment.
This matters because people tend to mistake genericity for failure. In fact, average-looking output was part of the original design logic. The researchers explicitly noted that the model would only produce average-looking faces with characteristic features correlated to the input speech, not images of specific individuals. That should have settled the matter. Instead, sharper models arrived, the pictures became more compelling, and the old caveat started to disappear from casual coverage. The capability became easier to overread just as it became easier to admire.
Diffusion models changed the quality of the results
The biggest technical shift after the early proof-of-concept phase came from diffusion models. In 2023, researchers proposed a speech-conditioned latent diffusion model for speech-to-face generation, arguing that earlier GAN-based systems were unstable and often failed to produce realistic faces. Their method used contrastive pretraining to align speech and face representations and added a face prior to control unwanted diversity in the generation process. The move is familiar from the wider generative AI boom: diffusion tends to produce images that look more natural, more coherent, and more photoreal.
That change matters for more than aesthetics. A blurry, obviously synthetic output invites skepticism. A cleaner portrait attracts trust, even when the underlying epistemic limit has not changed. Sharper pictures can make a weak inference look stronger than it is. The field’s more recent papers show a steady push toward identity-consistent generation, better cross-modal alignment, and more convincing facial detail. A 2024 IEEE ICME paper described voice-to-face generation through coupled self-supervised representation learning with diffusion, while a 2024 ACM paper called VoiceStyle brought voice cues into a latent diffusion image pipeline through cross-modal representation learning.
By 2026, the pattern was even clearer. Vox2Face, published in Information, framed the central challenge as a tradeoff between identity fidelity and visual quality. Its answer was to stop relying on direct speech-to-image mapping and instead build an identity-centric pipeline with an identity space alignment stage and an identity-conditioned diffusion prior. That is a useful marker of where the field has gone: the problem is no longer “can we generate any plausible face?” but “can we generate a face that feels more consistently tied to this speaker?”
This is where public misunderstanding becomes dangerous. Better generation quality does not erase the one-to-many nature of the task. It just makes the result easier to believe. A polished synthetic portrait can be more misleading than a crude one because humans tend to infer confidence from visual fidelity. The technical community often keeps the caveats in the paper. Products, headlines, and demos tend to keep the image and drop the caveat. That is the familiar path from research nuance to social overreach.
Why a generated face is not an identity match
The most important sentence in this entire debate may be the simplest one: there is no one-to-one mapping between faces and voices. Many people share similar pitch ranges, resonance patterns, speech habits, and demographic cues. A model can infer a likely visual neighborhood around a voice. It cannot derive an exact face from the audio signal alone. The foundational papers say this plainly. Speech2Face aimed to recover correlated traits, not the exact person. It produced average-looking faces rather than specific individuals.
That does not make the output useless. It makes it probabilistic. A generated face may be good enough to nudge a search, steer suspicion, personalize an avatar, or fill a screen in a communications product. The problem begins when probabilistic media is treated as evidentiary media. A model can be wrong in the identity sense while still being persuasive in the social sense. People do not need a result to be exact before they react to it. They only need it to look coherent.
It also helps to separate three neighboring capabilities that often get blurred together. Voice cloning creates a synthetic version of a person’s voice. Talking-face animation makes a face image speak. Face-from-voice generation predicts a likely facial appearance from audio. These are distinct tasks, but they are converging in the same synthetic identity stack. A bad actor does not need one perfect model. They need a toolkit. With enough audio, they may clone a voice. With a short sample, they may predict a face-like avatar. With animation tools, they can make that avatar move. That is an inference about the ecosystem, but the pieces are increasingly real.
That ecosystem view is the right one. Standing alone, face-from-voice may look like a niche research curiosity. Combined with synthetic speech, avatar generation, and cheap distribution, it becomes a way to manufacture plausible human presence from fragments of data. The reason this deserves serious attention is not that any one model can unmask a stranger from a voicemail. It is that modern generative systems are getting better at turning partial signals into socially convincing identities.
Bias, training data, and the stereotype problem
The stereotype problem is not a side issue. It is built into the task. If a model predicts a face from a voice, it must rely on demographic, anatomical, and cultural regularities found in training data. Some of those regularities reflect physiology. Some reflect media selection. Some reflect labeling systems. Some reflect old stereotypes that the model cannot distinguish from signal. Speech2Face itself evaluated age, gender, and ethnicity using a commercial service, Face++, with a fixed and limited category set. The paper also shows failure cases where pitch, accent, or language push the model toward visibly mismatched outputs.
That should make everyone cautious about claims that the system simply “reveals” what a speaker looks like. The output is shaped by the data pipeline from end to end: who appears in the source videos, how speech is segmented, which faces are usable, what labels exist, which features are optimized, and what visual norms the generator learns to favor. A face-from-voice system is always, in part, a portrait of its dataset.
There is a strong warning from adjacent biometric research as well. A 2022 Scientific Reports study on voice biometrics found non-negligible racial and gender disparities across commercial and research speaker-identification products, with measurable performance gaps across subgroups. That study was about voice biometrics rather than face generation, but the lesson travels cleanly: once systems use voice as a biometric signal, performance and fairness do not distribute evenly by default. Any pipeline that infers appearance from voice inherits a similar risk of demographic distortion, especially if users read the output as objective.
The privacy side of dataset construction has already started to bite the field. The 2023 SynVox2 paper describes ethical, privacy, and legal concerns around large-scale natural speech datasets and notes that the widely used VoxCeleb2 dataset was no longer accessible from its official website. That matters because it shows the research community recognizing a truth that industry learned late: massive public-data collection is not a frictionless foundation. Even when the data was visible online, it did not follow that people expected it to become raw material for identity modeling.
The privacy, fraud, and regulatory collision
The privacy issue starts before any face gets generated. A voice recording is already personal data in many contexts, and regulators treat voice and face as core biometric material when used for recognition systems. The UK ICO explains biometric capture through examples that include a digital photograph of someone’s face and a recording of someone talking. That does not automatically settle every legal question around face-from-voice generation, but it makes the stakes clear: audio and facial data sit close to the center of modern identity infrastructure.
That legal ambiguity is exactly why deployment context matters more than the demo. A research paper making a probabilistic portrait for academic analysis is not the same thing as an employer screening applicants, an insurer profiling callers, a platform auto-generating avatars, or a law-enforcement body inferring suspect appearance from intercepted audio. The EU AI Act takes a risk-based approach and treats some biometric systems, biometric categorization uses, and emotion-recognition uses as prohibited or high-risk, depending on context. The AI Act Service Desk makes clear that most biometric AI systems are not outright banned, but certain biometric categorization systems and some other uses face strict limits or prohibitions.
That does not yield a one-line answer such as “face-from-voice is illegal” or “face-from-voice is fine.” It yields a more realistic answer: the closer the system moves toward biometric inference, profiling, categorization, or high-stakes decision-making, the less room there is for casual experimentation. A playful demo inside a lab can become a compliance problem the moment it is operationalized against real people. That is where many frontier capabilities change character. The model stays the same; the institutional setting turns it into something else.
The fraud angle strengthens the case for caution even though it comes from neighboring technologies like voice cloning. The FTC launched a Voice Cloning Challenge because the technology posed both promise and significant risk, including extortion scams and appropriation of creative labor. The agency later highlighted approaches such as synthetic-voice detection, real-time liveness scoring, and watermarking. The FCC also announced in February 2024 that AI-generated voices in robocalls are treated as “artificial” under robocall restrictions. By May 2025, the FBI was warning about an active campaign in which malicious actors used text and voice messages to impersonate senior US officials. None of those examples is face-from-voice exactly. Together, they show the same pattern: once a short voice sample becomes enough to synthesize identity cues, abuse scales quickly.
The tools that might keep synthetic identity from running loose
No single safeguard solves this problem. Detection alone is not enough. Watermarking alone is not enough. Regulation alone is not enough. That is why the best current work focuses on layers: provenance, disclosure, auditing, policy, and product restraint. NIST’s 2024 report on synthetic content makes that layered approach explicit. It reviews methods for content authentication and provenance tracking, synthetic labeling, detection, prevention of abusive outputs, testing, and auditing. The point is not to find one silver bullet. The point is to make deception harder at each stage.
This is where C2PA and Content Credentials enter the picture. C2PA describes itself as an open technical standard for establishing the origin and edits of digital content, with Content Credentials acting like a nutrition label for media. The spec explainer is careful about the limit: Content Credentials do not declare whether a claim is true. They establish whether the provenance information is well formed, associated with the asset, and tamper-evident within the trust model. That is a meaningful distinction. Provenance can strengthen trust, but it does not replace judgment, media literacy, or forensic work.
The governance piece matters just as much as the cryptography. Partnership on AI’s framework for synthetic media is organized around consent, disclosure, and transparency, and it addresses builders, creators, distributors, and publishers rather than pretending the burden sits on one actor alone. That is the right direction because synthetic identity systems fail socially long before they fail technically. A company can make a very accurate model and still deploy it irresponsibly. A platform can attach a provenance signal and still design an interface that encourages overtrust. A newsroom can label altered media and still circulate it without adequate context.
The responsible path is not hard to describe, even if it is hard to enforce. Do not treat generated faces from audio as identification evidence. Do not deploy them in high-stakes settings without a clear legal basis, oversight, and external review. Keep humans aware of uncertainty. Preserve provenance where synthetic media is created or edited. Limit data collection. Build opt-out and redress. None of that will make the capability disappear. It will make it harder to turn a weak inference into a harmful decision.
The deeper significance of this technology is not that AI has somehow learned to “see” through sound. It is that the boundary between modalities is collapsing. A voice can suggest a face. A face can help synthesize a voice. An image can be animated into speech. As those links tighten, small fragments of personal data become more generative than they used to be. That is the shift worth understanding. A five-second clip may not tell the world exactly who you are. It may still tell a machine enough to build a plausible version of you, and that is already a profound change.
FAQ
Yes. Research systems such as Speech2Face were built to generate a frontal, neutral face from a short speech sample, and MIT publicly described the prototype as working from roughly five seconds of audio.
No. The core papers state that the goal is not to reconstruct an exact, recognizable individual but to recover facial traits correlated with the speech signal.
They can capture broad traits such as age-related cues, sex-linked vocal features, ethnicity-linked patterns used in the papers, and some craniofacial correlations, though none of these is perfectly reliable.
Speech is shaped by anatomy as well as language, including pitch, vocal tract characteristics, mouth shape, and other physical factors that influence sound production.
The research focuses on short clips. Speech2Face used short segments and reported results from roughly three to six seconds, while MIT described the public demo as using about five seconds.
Because the systems are designed to output average-looking canonical faces that express correlated traits rather than full natural portraits of specific individuals.
No. Face-from-voice predicts a likely facial appearance from audio. Voice cloning reproduces a synthetic version of a person’s voice. They are different tasks, even though both can be used in synthetic identity workflows.
Diffusion-based methods improved image realism and cross-modal consistency, making generated faces look sharper and more persuasive than earlier GAN-style systems.
Yes, in visual quality and alignment. Work from 2023, 2024, and 2026 shows a steady push toward more realistic, identity-consistent outputs.
Large paired audio-video corpora such as AVSpeech and VoxCeleb are central because they provide many examples of faces and voices occurring together in real video.
Because the model learns from demographic and media patterns in the training data, and adjacent voice-biometric research has already documented racial and gender disparities in performance.
Yes. Speech2Face reported mixed behavior around language, accent, and pitch, including examples where those cues led to mismatched visual predictions.
It should not be treated as identity evidence. The technology is probabilistic, and the foundational papers explicitly reject the idea that it recovers an exact person.
Voice can function as biometric material in recognition contexts. The ICO’s biometric guidance uses a recording of someone talking and an image of someone’s face as examples of biometric samples.
The AI Act uses a risk-based framework and places strict limits on some biometric and categorization uses. Whether a face-from-voice system falls into a regulated category depends heavily on how it is deployed.
Yes, especially in avatars, representative call visuals, and synthetic character generation. Even the early Speech2Face work pointed to uses such as cartoon renderings and faces for machine-generated voices.
Because the same short audio clips can feed multiple synthetic systems. Regulators and law enforcement are already dealing with harms from AI-generated identity cues built from voice data.
They help, but they do not solve it alone. C2PA can provide tamper-evident provenance information, yet its own explainer says it is not a cure-all for misinformation and does not judge whether claims are true.
Author:
Jan Bielik
CEO & Founder of Webiano Digital & Marketing Agency
This article is an original analysis supported by the sources cited below
Speech2Face: Learning the Face Behind a Voice
Foundational paper that framed face generation from short speech clips as a cross-modal learning problem.
Speech2Face
MIT CSAIL summary of the 2019 system, including the widely cited five-second demo description.
On Learning Associations of Faces and Voices
Early research showing that humans and machines can match unseen faces and voices above chance.
Seeking the Shape of Sound: An Adaptive Framework for Learning Voice-Face Association
CVPR paper on stronger voice-face association learning, useful for understanding the field’s middle stage.
Realistic Speech-to-Face Generation with Speech-Conditioned Latent Diffusion Model with Face Prior
Paper that brought diffusion-based image generation into speech-to-face synthesis.
Voice-to-Face Generation: Couple of Self-Supervised Representation Learning with Diffusion Model
2024 IEEE paper that pushed the task with self-supervised cross-modal learning and diffusion.
VoiceStyle: Voice-Based Face Generation via Cross-Modal Prototype Contrastive Learning
ACM paper showing how voice cues can be injected into latent diffusion image generation.
Vox2Face: Speech-Driven Face Generation via Identity-Space Alignment and Diffusion Self-Consistency
Recent paper focused on identity fidelity and visual quality in speech-driven face generation.
AVSpeech: Audio Visual Speech Dataset
Official dataset page describing a large web-scale corpus used in audiovisual speech research.
VoxCeleb
Official page for one of the most widely used large-scale audio-visual speech datasets.
SynVox2: Towards a privacy-friendly VoxCeleb2 dataset
Paper that addresses legal, ethical, and privacy concerns around large natural speech datasets.
Exploring racial and gender disparities in voice biometrics
Open-access study documenting subgroup disparities in voice biometric performance.
Fighting back against harmful voice cloning
FTC consumer guidance on real-world misuse of AI-enabled voice cloning.
The FTC Voice Cloning Challenge
FTC challenge page outlining the risks and the policy interest around cloned voices.
FTC Announces Winners of Voice Cloning Challenge
FTC press release summarizing detection, watermarking, and authentication ideas aimed at reducing harm.
Senior US Officials Impersonated in Malicious Messaging Campaign
FBI warning that shows how synthetic voice impersonation is already being used in live attacks.
AI Act
European Commission overview of the EU’s risk-based AI regulatory framework.
Frequently Asked Questions
Official AI Act Service Desk FAQ clarifying how biometric systems are treated under the law.
Article 5: Prohibited AI practices
Official AI Act Service Desk page outlining prohibited AI uses, including certain biometric applications.
Biometric recognition
ICO guidance explaining how biometric capture, feature extraction, and templates work.
Reducing Risks Posed by Synthetic Content: An Overview of Technical Approaches to Digital Content Transparency
NIST report on provenance, labeling, detection, testing, and other synthetic-content safeguards.
FCC Makes AI-Generated Voices in Robocalls Illegal
FCC announcement that AI-generated voices in robocalls are covered by existing robocall restrictions.
C2PA | Verifying Media Content Sources
Official overview of the open standard behind Content Credentials and media provenance claims.
C2PA and Content Credentials Explainer
Technical explainer that clarifies what Content Credentials can prove and what they cannot.
PAI’s Responsible Practices for Synthetic Media
Governance framework centered on consent, disclosure, and transparency for synthetic media systems.
| Citing this article? Brief excerpts are welcome. Please credit Webiano.digital, name the author where stated, and include a link to https://webiano.digital and to this original article. Full or substantial republication requires prior written permission. Read our Copyright and Content Use Policy. |














