

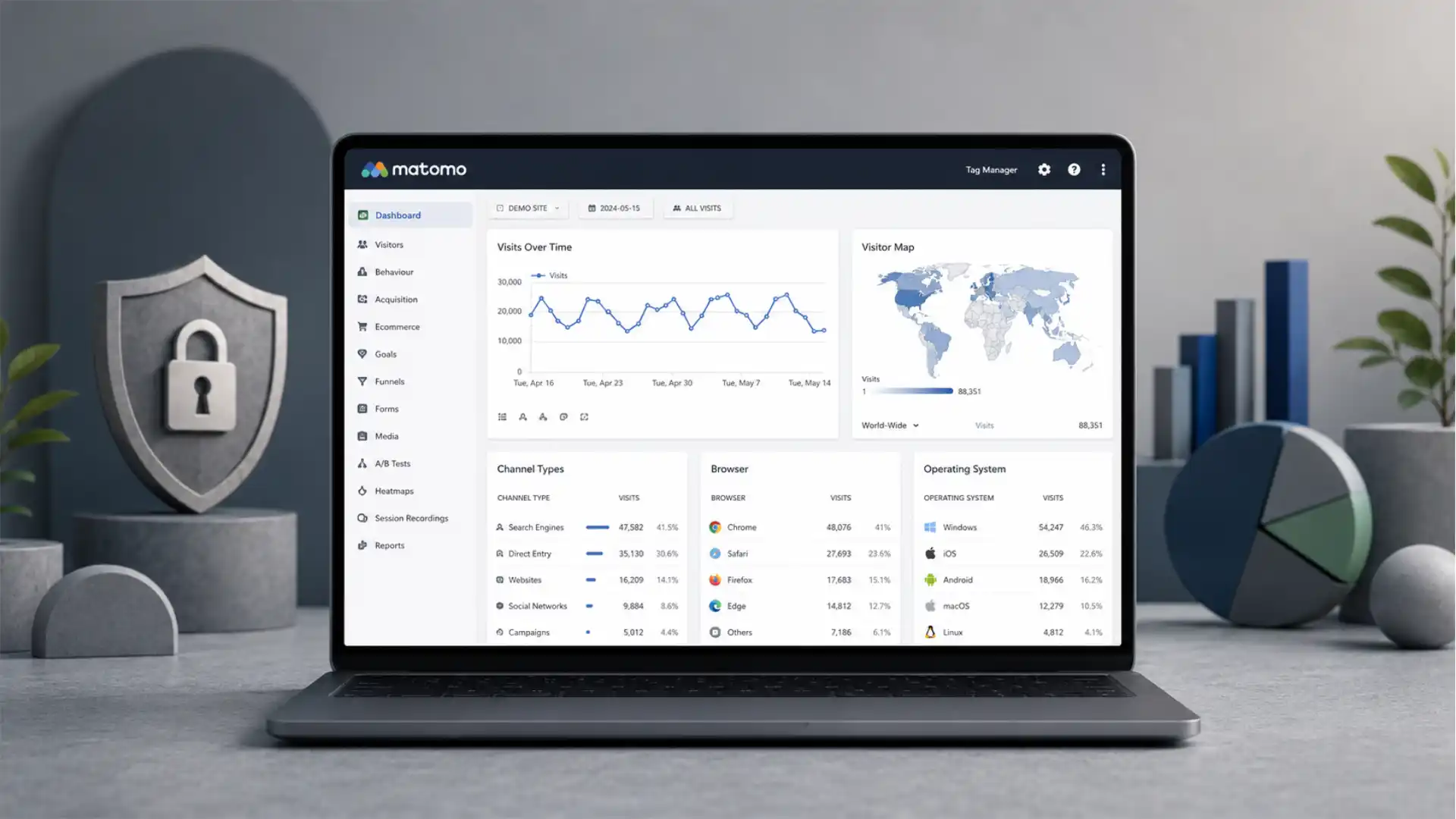
Matomo’s current pitch is blunt: popular analytics tools can miss up to 40% of traffic, while Matomo offers privacy-first, GDPR-compliant analytics with full data ownership and fast setup. That claim matters because it turns a familiar analytics question into a governance question. The issue is no longer only whether a dashboard looks clean. The issue is whether a company can trust the numbers it uses to decide what content to publish, where to spend media budget, which product journey to fix, and which markets deserve more attention. Matomo states that it is trusted by more than 1 million organisations worldwide and positions itself around privacy protection, data ownership, no sampling, open source, and GDPR alignment.
Table of Contents
The trust problem behind website analytics
The claim also arrives at a time when analytics teams are caught between two pressures that do not fit neatly together. On one side, managers still expect precise performance reporting. They want conversion rates, attribution paths, content performance, campaign returns, funnel drop-offs, search traffic quality, ecommerce revenue, device breakdowns, and proof that marketing work is paying back. On the other side, the technical and legal ground under tracking has shifted. Consent banners reduce the data available to many trackers. Browsers restrict identifiers. Ad blockers interfere with common analytics scripts. Privacy regulators expect proof that collection is limited, documented, lawful, and understandable to users. Google’s own Analytics documentation confirms that GA4 explorations may be sampled above certain event volumes and that thresholds may withhold data in reports and explorations to reduce identification risk.
The result is a quiet crisis of confidence. Teams often act as if web analytics is a neutral record of what happened. It is not. Analytics is an instrument. Its numbers depend on tag placement, browser behavior, user consent, data retention settings, identity rules, bot filtering, event design, geographic law, and the vendor’s processing model. A dashboard is not a fact table by default; it is the visible output of many choices that can distort the picture before anyone opens a report.
Matomo’s advantage, if implemented carefully, is not magic accuracy. No lawful analytics platform should promise perfect visibility into every visitor in every jurisdiction. The stronger argument is narrower and more useful: a privacy-first, first-party analytics setup reduces avoidable measurement loss, keeps governance closer to the organisation, and makes the trade-offs easier to inspect. That matters to marketing teams, publishers, ecommerce operators, public institutions, universities, agencies, SaaS companies, product teams, and any organisation that has learned the hard way that consent, browser privacy, and platform dependency are not side issues.
The phrase “privacy-first analytics” is often used loosely. In Matomo’s case, the practical meaning is more concrete. Matomo can be self-hosted. It can be configured without cookies in some circumstances. It includes privacy controls, GDPR-related tools, anonymisation options, consent and opt-out features, and settings that address national ePrivacy requirements. It is open source under the GNU GPL v3 or later, and its public GitHub repository describes Matomo as a PHP/MySQL analytics application that users can download and install on their own web server.
That does not make compliance automatic. It changes where responsibility sits. With a platform built around ownership and privacy controls, the organisation still needs a lawful purpose, a clear configuration, a retention policy, an opt-out or consent path where required, and honest documentation. Matomo gives teams more control over analytics data; it does not remove the need to make controlled choices. That distinction is the difference between serious privacy-first analytics and a marketing slogan.
Matomo’s claim lands at a difficult moment for measurement
The missing-traffic problem is not a hypothetical fear created by privacy vendors. It is visible in the way modern web measurement is built. Many analytics stacks depend on browser-side JavaScript, cookies or local storage, third-party domains, tag managers, advertising identifiers, consent-management platforms, and integrations with ad networks. Each dependency creates a failure point. If a browser blocks the request, a user declines consent, a tag fires late, a consent mode is misconfigured, an ad blocker filters the script, or a platform thresholds the report, the number that appears in the dashboard is not the full population. It is the measurable remainder.
Matomo’s homepage claim that common analytics tools may miss up to 40% of traffic should be read as a market argument, not as a universal benchmark. A public-sector site with low ad-blocking exposure, strict consent controls, and limited paid media may see a different loss profile from a developer-focused SaaS site, a news publisher, or a privacy-conscious technology community. Audience type matters. Device mix matters. Country matters. Browser mix matters. Tag architecture matters. Consent design matters. The point is that large blind spots are plausible, and in some audiences they are routine enough to change business decisions. Matomo’s claim sits alongside broader ad-blocking data showing substantial adoption: Backlinko’s 2026 update, citing GWI data, puts global ad-blocker use at 29.5% of internet users as of Q2 2025.
The most dangerous version of the problem is not undercounting alone. It is biased undercounting. If all visitors disappeared randomly, teams could still estimate direction with some confidence. Real measurement loss is not random. People who block ads, reject cookies, use privacy-focused browsers, browse in private mode, work inside locked-down corporate networks, or use security tools may differ sharply from people who allow every tag to fire. A product aimed at developers, security professionals, students, researchers, journalists, healthcare staff, public-sector users, or European buyers may lose a different slice of its audience than a mass-market retail site. The missing visitors may be exactly the people whose behaviour the business most needs to understand.
That bias can mislead teams in ordinary decisions. A content team may think a topic underperforms because privacy-conscious readers are not counted. An ecommerce team may overvalue paid traffic because consented users are easier to attribute. A SaaS team may underestimate documentation usage because technical users block common scripts. A university may misread international interest because consent rates vary by region. A public institution may understate access to critical pages because strict privacy settings are common among its audience. Measurement loss is not just a reporting nuisance; it changes where money and attention go.
The technical market has already responded with server-side tagging, consent mode, first-party collection, cookieless measurement, privacy-preserving aggregation, and modeled conversions. Each approach has a place. Yet many of them keep the organisation dependent on large advertising platforms and their interpretation of missing data. Google Consent Mode, for example, lets sites adjust Google tag behavior based on consent states for advertising and analytics purposes, while GA4 has its own rules around thresholds, retention, and report visibility.
Matomo’s counter-position is different. Instead of treating missing data mainly as an advertising-modeling problem, it treats measurement as a first-party analytics and governance problem. The organisation can run Matomo on its own infrastructure, avoid data sampling, limit personal data, configure privacy controls, and keep analytics data separate from advertising resale or cross-site profiling. That structure appeals to teams that want to answer operational questions without feeding a larger ad ecosystem. The strategic shift is from “recover signals for platforms” to “measure the site for the organisation.”
That distinction explains why Matomo’s message has become sharper. Privacy-first analytics used to sound like a niche preference for organisations with strict legal teams. Now it speaks to a wider operational pain. Teams want fewer consent losses, fewer unexplained report gaps, fewer platform assumptions, fewer dependencies on black-box modeling, and a clearer answer when a data protection officer asks what is collected, where it is stored, who receives it, and how long it remains available.
Missing traffic is a business risk, not a dashboard quirk
The phrase “missing traffic” can sound harmless because the web has trained teams to accept approximate data. Most organisations know that analytics is not accounting. They tolerate some bot filtering, some attribution uncertainty, some cookie loss, some session stitching weakness, and some campaign-tag mistakes. The problem starts when “approximate” becomes “materially wrong” and no one knows which part is wrong. A 10% measurement gap may be manageable; a 30% or 40% gap can change a board-level decision.
A media publisher might use analytics to decide whether to hire for a topic vertical. A SaaS company might use analytics to prioritise onboarding fixes. A retailer might use analytics to decide whether paid search is profitable after margin. A public authority might use analytics to decide which service pages deserve translation. A nonprofit might use analytics to report campaign reach to funders. In each case, missing traffic can distort the economic story. It can make strong work look weak, weak work look strong, or expensive channels look better than owned demand because more of their paths are consented and attributed.
The most expensive damage often sits inside segmentation. Total visits may be wrong, but teams rarely make decisions from total visits alone. They cut by source, campaign, landing page, country, device, browser, new versus returning users, referrer, content group, checkout step, event, or custom dimension. The smaller the segment, the more fragile the report. GA4 documentation confirms that explorations may be based on sampled data when a query includes more than 10 million events, and that reports and explorations may be subject to thresholds when demographic information or Google signals are involved.
A segment can look clean while hiding its weakest assumptions. A team may compare two landing pages and conclude that one converts better. Yet the worse-looking page may attract a more privacy-conscious audience whose visits and conversions are undercounted. A campaign may appear to produce low engagement because users arrive through in-app browsers or privacy tools. A documentation page may look unimportant because technical readers block the analytics request. These errors are hard to spot because the dashboard does not show the counterfactual. It shows the visitors who passed through the measurement gate.
Matomo’s no-sampling argument matters here. Matomo says it does not use data sampling on any plan, which means the platform is not intentionally estimating reports from a subset of collected data in the way sampling systems do. That does not mean Matomo counts every human visit on the web. It means that once data is collected into Matomo, reporting is not reduced by platform sampling rules.
For teams that work with small segments, this distinction is not academic. Search specialists want landing-page and query-adjacent analysis. Content teams want long-tail article performance. Ecommerce teams want SKU, coupon, campaign, and funnel combinations. Product teams want feature-event cohorts. Agencies want client-by-client reports. Public bodies want service pages by language and region. A platform that withholds or samples data under certain conditions may still be powerful, but teams need to know when the report is an estimate, when a row is hidden, and when a number represents the whole collected dataset.
The business risk grows when analytics is treated as a single source of truth without reconciliation. Mature teams compare analytics with server logs, CRM records, ecommerce orders, payment data, search-console data, ad-platform clicks, and backend event streams. Smaller teams often lack that discipline. They look at one dashboard and act. Matomo’s appeal to those teams is that it offers a more inspectable measurement base. The data sits closer to the organisation. Reports are not sampled. Privacy settings are explicit. Self-hosting is possible. Data ownership is a product promise rather than a contract footnote.
Still, a privacy-first platform cannot save a careless measurement culture. If the tracking plan is weak, events are named inconsistently, consent rules are misunderstood, ecommerce revenue is duplicated, internal traffic is not excluded, or campaign parameters are chaotic, the platform will faithfully preserve bad data. Accurate analytics starts with architecture; software only decides how much control the team has over that architecture.
The mechanics behind disappearing visits
Traffic disappears from analytics through mundane technical routes. A JavaScript file is blocked. A network request is filtered. A cookie cannot be set. Consent is denied. A tag loads after the user leaves. A browser limits storage. A privacy extension blocks a domain. A corporate firewall removes tracking calls. A content security policy breaks a tag. A single-page application fails to send route-change events. A consent management platform suppresses analytics by default and never updates the tag state. None of these failures has to be dramatic. A few small losses can compound until the report no longer describes the audience.
Ad blockers are the most visible mechanism because they target the infrastructure used by advertising and analytics. Many filter lists block known tracking domains, scripts, URL patterns, tag managers, and endpoints. Analytics tools that rely on easily recognized third-party domains or common script names may lose users before consent logic even runs. The loss may be higher in technology-heavy audiences and lower in less privacy-conscious markets. Backlinko’s GWI-based estimate of 29.5% worldwide ad-blocker use does not mean all analytics tools lose 29.5% of all visits. It does show that blocking behaviour is mainstream enough to affect business reporting.
Browsers add another layer. Apple’s WebKit introduced Intelligent Tracking Prevention to reduce cross-site tracking by limiting cookies and other website data. Mozilla says Firefox Enhanced Tracking Protection blocks trackers that follow people around the web and includes protections against certain scripts. Google, after years of shifting plans around third-party cookies in Chrome, said in April 2025 that it would maintain its current approach to third-party-cookie choice while continuing to improve tracking protections in Chrome’s Incognito mode, including IP Protection.
Consent rules create a separate and legally driven loss path. In much of Europe, analytics collection may require consent unless it falls inside a narrow exemption. Matomo itself warns that cookieless does not automatically mean consent-exempt in most European countries because ePrivacy rules can apply to tracking technologies beyond cookies.
That point matters because many analytics debates confuse “no cookie” with “no legal issue.” A tool can avoid cookies but still access terminal equipment, process personal data, or create identifiers. The EDPB’s 2024 guidance on the technical scope of Article 5(3) of the ePrivacy Directive states that the rule concerns storing information or gaining access to information stored in a user’s terminal equipment and addresses tracking tools beyond traditional cookies.
Matomo’s practical answer is configuration. It can be used with cookies, without cookies, with consent, under opt-out regimes in some jurisdictions, or in a CNIL-aligned consent-exempt mode where strict conditions are met. Its documentation says it is possible, with the right configuration, to use Matomo in a way that does not collect personal data or set cookies, and Matomo provides guidance for using analytics without asking for consent or showing a cookie banner in qualifying setups.
The strongest form of privacy-first analytics does not pretend these mechanisms are irrelevant. It maps them. It asks which users are not being collected, which rules apply in which markets, which identifiers exist, whether a cookie is used, whether IP addresses are anonymised, whether data is shared with a third party, whether behavioural features require consent, and whether reports reflect collected data without sampling. Good analytics implementation treats missing data as a known design constraint, not a surprise discovered after reporting goes wrong.
Privacy-first analytics means fewer hidden dependencies
Privacy-first analytics is often mistaken for a softer version of analytics, as if respecting privacy means accepting weaker measurement. The better reading is different. Privacy-first measurement reduces hidden dependencies that make analytics fragile. Instead of collecting as much as possible and sorting out legality later, it starts with a stricter question: which data is needed to understand site and product performance, and which data creates risk without adding enough decision value?
That question changes the design of analytics. It pushes teams toward first-party collection, shorter retention, anonymised IP addresses, clear event taxonomies, limited user identifiers, transparent consent flows, opt-out tools, and separate treatment of analytics and advertising. It discourages the habit of connecting every tool to every other tool because integration looks convenient. A smaller data footprint is not only a legal posture. It makes measurement easier to explain.
Matomo’s privacy positioning rests on that premise. Its privacy page presents the platform as privacy-friendly analytics with full data ownership and GDPR compliance, while its GDPR page describes a GDPR Manager and privacy features such as locating, exporting, deleting, anonymising, and managing visitor data. Matomo’s privacy user guide also gathers topics such as compliance, ePrivacy, anonymisation, cookies, consent, opt-out tools, and data retention.
Hidden dependency is the right frame because most analytics failures come from relationships the business does not fully see. A site owner may think it is collecting pageview data for internal reporting. In practice, a tag may send data to a vendor that also runs advertising services. A consent signal may travel through a third-party framework. A report may rely on modeled data. A retention rule may differ by data type. A dashboard may suppress rows for privacy thresholds. A product team may add session recording without realising that it changes the consent and privacy analysis. The organisation thinks it installed analytics; it has built a small data supply chain.
Matomo’s full data ownership claim speaks to this problem. Matomo says its users own their analytics data, with no external parties looking in, and contrasts that with Google Analytics, which it says uses data to serve Google’s advertising platform. Google’s exact contractual and technical treatment of analytics data depends on settings, account type, region, consent, linked products, and product terms, but Matomo’s broader point is easy to understand: an analytics platform tied to an advertising giant carries different governance questions from a platform designed for first-party measurement.
This does not make one tool right for every organisation. Google Analytics remains deeply embedded in paid media, Google Ads, Search Ads 360, Looker Studio workflows, BigQuery exports, and marketing teams trained around GA4. For advertisers that need tight Google ecosystem integration, GA4 will often remain part of the stack. Matomo’s strongest fit is for teams that see analytics as owned infrastructure rather than as an extension of advertising operations.
Privacy-first analytics also changes the conversation with users. A privacy policy that says analytics data is collected for audience measurement, stored under the organisation’s control, anonymised where possible, retained for a defined period, and not reused for cross-site advertising is easier to defend than a long chain of vendor purposes. Users may still decline tracking. Regulators may still require consent. But the collection story is cleaner.
Trustworthy analytics is not only about better numbers; it is about being able to explain how the numbers came into existence. That explanation has become part of the product. Customers, procurement teams, data protection officers, public-sector buyers, universities, and enterprise security reviewers increasingly ask for it. Matomo’s pitch aligns with that shift because it sells analytics as a controlled system rather than a black box.
Data ownership changes who controls the measurement layer
Data ownership sounds abstract until a team needs to answer a difficult question. Who can access raw event data? Where is it stored? Can it be deleted? Can it be exported? Can it be retained beyond a vendor’s default period? Can the organisation audit changes? Can the analytics database be joined with internal systems without sending more data to an advertising vendor? Can a regulator or client be shown a clear processing record? Can a public body keep analytics inside its own infrastructure? These are ownership questions, and they are no longer limited to large enterprises.
Matomo’s ownership model gives organisations two main routes. Matomo Cloud is hosted by Matomo, while Matomo On-Premise lets teams install and run the platform themselves. Matomo’s own materials emphasise self-hosting, privacy controls, no data sampling, open-source software, and ownership of collected data. Its GitHub repository describes a five-minute installation process ending with a JavaScript tracking code that can be placed on websites. Its on-premise requirements page covers the server-side requirements teams need to check before running the platform themselves.
The practical value of this model is strongest in organisations that already treat data infrastructure as a governance asset. A bank may want analytics data inside controlled hosting. A healthcare provider may need stricter access controls and retention limits. A university may need to avoid unnecessary third-party transfers. A government agency may have procurement rules around data residency. A publisher may want raw analytics without sampling or platform thresholds. An agency may need to prove to clients that their website analytics are not being reused by an ad network.
Ownership also affects historical analysis. Google Analytics data retention settings apply to user-level and event-level data, and Google’s documentation says Google-signals data is retained for a maximum of 26 months regardless of settings. GA4 offers powerful reporting, but its retention model is a product constraint that teams need to plan around. Matomo’s self-hosted model gives organisations more control over retention, though they still need lawful limits under GDPR, ePrivacy laws, and their own privacy notices.
Data control trade-offs in common analytics models
| Analytics model | Main control benefit | Main operational risk |
|---|---|---|
| Advertising-platform analytics | Strong ad ecosystem integration | More vendor dependency and reporting rules |
| Privacy-first cloud analytics | Easier deployment with cleaner governance | Less infrastructure control than self-hosting |
| Self-hosted analytics | Maximum control over storage, access and retention | Requires maintenance, security and technical ownership |
| Server-side tagging layer | More control over request routing | Misconfiguration can increase privacy risk |
| Log-based analytics | Independent traffic reference point | Less behavioural and campaign context |
This table does not rank tools by quality. It shows why the right analytics choice depends on governance needs, technical capacity, paid-media dependency, and the level of control the organisation is ready to operate.
Ownership carries work. Self-hosted analytics is not a free lunch. A team must patch servers, secure admin access, manage backups, monitor performance, document retention, test upgrades, and restrict user permissions. If the organisation has no technical owner, cloud hosting may be safer than a neglected self-hosted instance. Control only improves trust when someone is accountable for operating it well.
Matomo’s position is strongest because it does not force a single answer. Teams can start with cloud hosting for speed or choose on-premise for stronger internal control. The choice should be made with legal, security, marketing, product, and engineering input. A marketing manager alone may prefer the fastest path. A data protection officer may prefer the least intrusive configuration. Engineering may care about maintainability. Security may care about access and patching. Finance may care about cost predictability. The right decision balances all of those needs without pretending that one department owns analytics in isolation.
This is where ownership becomes strategic. Analytics data describes what customers, readers, users, donors, students, or citizens do on digital properties. It reveals demand, friction, intent, content value, and conversion behaviour. Treating that data as rented exhaust from a vendor platform gives away more control than many organisations realise. Treating it as first-party infrastructure makes measurement slower to design but easier to defend.
GDPR compliance is configuration, not a slogan
GDPR compliance is often used as a badge on analytics websites. The phrase is incomplete unless it points to a lawful configuration and a real processing model. The GDPR governs personal data processing, and the European Commission describes it as the EU framework for data protection rights, business obligations, and lawful handling of personal data. The EDPB’s consent guidance explains the conditions for valid consent under Regulation 2016/679.
For analytics, GDPR questions usually overlap with ePrivacy rules. GDPR asks whether personal data is processed lawfully, fairly, transparently, and with rights and safeguards. ePrivacy rules often decide whether consent is needed before storing information on, or accessing information from, a user’s device. A web analytics setup may need to satisfy both. That is why a tool’s generic “GDPR-compliant” promise is only the start of the analysis.
Matomo’s documentation is unusually direct about this point. Its FAQ says the type of tracking technology does not automatically exempt a site from consent requirements and that ePrivacy laws can apply to any interaction with a visitor’s terminal device, whether through cookies, JavaScript, or similar tools. It also says consent requirements differ across EU countries because each country implements the ePrivacy Directive into national law.
This is the right level of caution. A privacy-first analytics platform can provide the controls needed for compliance, but the site owner remains responsible for applying them correctly. If a team enables cookies, session recording, ecommerce tracking, user IDs, heatmaps, campaign attribution, CRM matching, or behavioural profiling, the legal analysis changes. If the team limits analytics to audience measurement with anonymisation, short retention, no cross-site tracking, and an opt-out mechanism, the analysis may be more favourable in certain countries. The difference is not the brand name on the dashboard; it is the configuration and use.
Matomo offers tools that fit GDPR obligations. It describes a GDPR Manager, visitor data export and deletion features, anonymisation options, opt-out mechanisms, consent features, and retention controls. These features matter because GDPR is not only about asking for consent. It also concerns rights of access, erasure, transparency, data minimisation, purpose limitation, storage limitation, security, accountability, and controller-processor relationships.
Still, teams should avoid a common mistake: treating privacy controls as a one-time setup task. Analytics implementations change. Marketers add new events. Product managers request funnels. CRO teams add heatmaps. Agencies install tag-manager templates. Paid-media teams connect ad platforms. Developers change consent banners. A privacy-compliant setup in January may no longer be compliant in June if new collection has been added without review.
The governance answer is not to freeze analytics. It is to set a review process. Every new event, tag, plugin, identity field, behavioural feature, export, and integration should answer five questions: what is collected, why it is needed, whether it includes personal data or device access, where it goes, and how long it stays. GDPR-ready analytics is a living operating model, not a checkbox saved during installation.
Matomo gives teams a stronger starting point because the platform is built around privacy controls rather than added-on privacy explanations. Its value is especially clear when a legal or compliance team needs to audit settings. If the organisation can show IP anonymisation, cookieless configuration where relevant, limited purposes, retention settings, opt-out tools, and no advertising reuse, the internal conversation becomes easier. Regulators do not reward slogans. They look for accountable choices. Matomo’s best use is to make those choices visible.
Consent exemption has narrow conditions
Consent exemption is one of the most attractive but most misunderstood ideas in web analytics. The promise sounds simple: measure audiences without forcing every visitor through a cookie banner. The reality is stricter. In France, CNIL explains that audience measurement cookies may be exempt from consent only under defined conditions, including user information, an ability to object, strictly limited purposes such as audience measurement and some A/B testing, no cross-checking with other processing, scope limited to a single site or application editor, IP truncation, and limits on tracker lifetime.
CNIL’s English guidance specifically says that most large audience measurement offerings do not fall within the exemption regardless of configuration and points to open-source software such as Matomo that can be configured by the publisher. That distinction is crucial. The exemption is not a blanket approval of analytics. It is a narrow path for analytics used for the publisher’s own audience measurement, with limited data, limited purposes, and safeguards.
Matomo has invested heavily in this area. Its FAQ on configuring Matomo for the CNIL exemption includes a self-assessment table and describes a compliance mode that disables functionalities incompatible with the exemption, assesses settings, and flags compliant, non-compliant, and unknown items. Matomo also announced in April 2026 a 1-Click CNIL Compliance feature intended to assess a setup against CNIL conditions, apply supported settings, and make remaining manual checks clearer.
The business value is obvious. Consent banners often reduce measurement coverage because some users refuse, ignore, close, or never interact with them. Matomo’s 2021 CNIL announcement argued that avoiding consent screens in qualifying setups may improve data accuracy because fewer visitors are lost at the consent step.
But this is where teams need discipline. The moment analytics is used for broader marketing purposes, personalisation, advertising retargeting, CRM enrichment, cross-site analysis, user-level behavioural profiles, or detailed session replay, the exemption may disappear. Ecommerce tracking may also raise extra consent and purpose questions; Matomo’s own CNIL ecommerce FAQ warns that features beyond CNIL exemptions require explicit consent before collection.
This creates a strategic fork. A team can choose narrower analytics with better coverage and simpler privacy review. Or it can choose richer behavioural and marketing data with more consent burden and more measurement loss. Neither choice is automatically wrong. A publisher focused on audience trends may prefer exemption-aligned measurement. An ecommerce business running advanced remarketing may need consented tracking and ad integrations. A SaaS product may split basic product analytics from consented behavioural tools. The mistake is pretending the organisation can have the narrow exemption and broad profiling at the same time.
Consent exemption is not a loophole; it is a design discipline. The analytics setup must be built to fit the exemption, not retrofitted after the marketing team has already enabled every feature. Matomo’s CNIL compliance tooling matters because it gives teams a clearer operational path. It reduces the risk that a well-intentioned team misses a buried setting. It also gives data protection officers a better review surface than scattered documentation and manual screenshots.
The wider significance goes beyond France. Other European authorities have their own interpretations of analytics consent, and Matomo’s ePrivacy documentation discusses national differences, including Spain, Italy, Switzerland, and others. The direction is clear: privacy-friendly analytics is becoming country-specific and configuration-specific. A platform that helps teams document those differences is more useful than one that treats Europe as a single consent rule.
CNIL’s approach shows where analytics law is going
CNIL’s analytics guidance has become influential because it gives a practical path between two poor extremes. One extreme says every analytics interaction should require consent, even when the data is limited and used only to keep the site working and improve the service. The other extreme says analytics is harmless and should be exempt by default. CNIL takes the harder middle route: analytics can be exempt only when it is narrow, controlled, documented, and protected.
This matters for Matomo because Matomo fits that legal imagination better than advertising-platform analytics. CNIL’s guidance says most large audience measurement offerings do not fall inside the exemption and suggests using open-source software such as Matomo that publishers can configure themselves. The French version of CNIL’s 2025 page on audience-measurement tools sets out cases where trackers may be exempt from consent when they are strictly necessary to provide the service and fit defined purposes and limits.
For organisations outside France, the CNIL model is still useful as a benchmark. It turns vague privacy language into operational requirements: limit purposes, reduce data, avoid cross-checking, restrict scope, truncate IP addresses, limit tracker life, inform users, and offer objection. A team can use that checklist even where local law differs because it expresses a defensible privacy posture.
Matomo’s 2026 1-Click CNIL Compliance feature should be seen in that light. It is not only a French feature. It is a sign that analytics platforms are starting to compete on the ability to turn legal requirements into product settings. The feature assesses a site’s configuration, applies settings Matomo can control, and marks items that require manual review. That reduces the gap between compliance advice and implementation.
This direction will likely matter more as regulators pay attention to online tracking beyond banners. The EDPB’s technical guidance on ePrivacy Article 5(3) shows that cookies are not the only concern; device access, tracking tools, and newer techniques remain under scrutiny. The UK ICO’s cookie guidance states that analytics cookies are not treated as strictly necessary under PECR and require consent, with more detailed rules depending on the UK framework.
The lesson for businesses is that privacy compliance cannot be outsourced entirely to a consent banner. Consent banners have become the visible symbol of tracking law, but the deeper question is whether the underlying data collection is necessary, proportionate, and understandable. A site can have a banner and still collect too much. A site can avoid a banner in some jurisdictions and still need to provide information and opt-out rights. The legal centre of gravity is moving toward accountability.
Matomo benefits from that shift because its product story is accountability-heavy. Self-hosting, open source, no sampling, privacy settings, data retention controls, and CNIL-specific tooling all fit an environment where teams need to prove what their analytics stack does. A platform built for proof has a better story than a platform that asks customers to trust opaque processing.
The risk for Matomo is complexity. The more country-specific privacy rules become, the more buyers may expect the platform to solve legal interpretation automatically. It cannot. Matomo can enforce settings it controls, produce self-assessment materials, and document privacy choices. It cannot decide a controller’s lawful basis, rewrite a privacy notice, audit every third-party tag, or know whether a team is using exported data for a new purpose. Privacy-first platforms reduce compliance friction; they do not replace compliance judgment.
The winners in analytics will be the tools that make judgment easier. That means clear defaults, visible warnings, exportable records, strong documentation, and settings that block incompatible features when a compliance mode is enabled. Matomo’s CNIL work points in that direction and gives the platform a sharper difference from tools that still treat privacy as a settings panel rather than a product architecture.
Accuracy means more than counting every pageview
Accuracy in analytics is often reduced to volume: did the platform count more visits? That is too narrow. A platform can count more events and still produce worse decisions if the events are poorly defined, duplicated, over-collected, unlawfully collected, or disconnected from business questions. The goal is not maximum data; the goal is trustworthy data that answers the right questions with known limits.
Matomo’s claim about missed traffic is important because collection coverage is the first layer of accuracy. If an analytics tool misses many visitors because of blockers, consent loss, or sampling, reports may be skewed. But collection is only the beginning. Teams also need semantic accuracy. A “lead” event should mean one thing. A “trial_started” event should fire once. Revenue should not duplicate after refresh. Campaign parameters should be consistent. Internal users should be filtered. Bot traffic should be handled. SPA route changes should count as pageviews. Consent states should be recorded and respected.
Privacy-first analytics can support semantic accuracy because it forces teams to define purpose. If the analytics setup is limited to audience measurement, event definitions become simpler. If ecommerce or product analytics is added, teams must justify why each event is needed. This discipline prevents the common tag-manager sprawl where every department adds fields “just in case.” The privacy review becomes a quality-control review.
No data sampling is one area where Matomo’s claim is clear. Matomo says it does not use data sampling on its plans, while Google’s own GA4 documentation confirms that explorations may use sampled data in large queries. Sampling is not inherently bad; it exists to answer complex queries faster and cheaper. The issue is whether teams know when they are looking at sampled data and whether sampling is acceptable for the decision at hand.
Thresholding is different from sampling. GA4 thresholds may hide data to prevent identification risk. That is a legitimate privacy purpose, but it can frustrate teams trying to understand small segments. A report may not only estimate; it may suppress. Again, the point is not that thresholds are wrong. The point is that organisations need to understand the reporting model they are using.
Matomo’s reporting model gives teams more direct access to collected data. That can make analysis more predictable, especially for long-tail content, small campaigns, country slices, device slices, and custom events. But it puts more responsibility on the controller to avoid creating privacy risk inside the analytics database. If a team collects personal data into Matomo unnecessarily, the platform’s openness and ownership do not make the collection safe. More direct data access is powerful, and power needs guardrails.
Accuracy also has a human layer. Analysts need to know how the data was collected. Marketers need to understand why a privacy-first setup may show different numbers from ad platforms. Executives need to stop treating dashboard disagreements as proof that one tool is broken. Different systems measure different events at different times under different rules. Google Ads counts ad interactions and conversions according to its attribution and consent systems. Search Console reports search impressions and clicks. Matomo reports site-side activity that it collects. Server logs record requests, including bots and non-human traffic. Payment systems record completed transactions. None of them is the whole truth.
The mature approach is triangulation. Use Matomo for owned site behaviour. Use server logs for independent traffic checks. Use backend revenue for final commercial truth. Use Search Console for organic search visibility. Use ad platforms for media buying, but reconcile their numbers with first-party analytics and orders. A trustworthy analytics stack has a primary measurement layer and reference points that expose blind spots.
Matomo’s role is strongest as that primary first-party layer. It gives the organisation a base that is closer to its own site, under its own control, with privacy settings it can inspect. That does not eliminate uncertainty. It makes uncertainty easier to locate.
No sampling matters when segments drive decisions
Sampling sounds like a technical footnote until a team has to defend a decision based on a narrow segment. A national traffic report may tolerate some estimation. A landing-page test in one country from one campaign over three days may not. A content team comparing twenty low-volume articles needs actual collected rows, not a modeled sketch. A SaaS team reviewing enterprise leads from privacy-conscious browsers needs confidence that the small numbers are not being hidden or estimated into uselessness.
Google’s GA4 documentation states that explorations may be sampled if more than 10 million events are part of a particular exploration query. It also states that reports and explorations can be subject to data thresholds, especially when demographic information or Google signals are present. These features exist for performance and privacy reasons, but they affect analytical confidence.
Matomo’s no-sampling position gives it a clear selling point: once events are collected, teams can work with unsampled reports. That matters most for organisations whose value sits in the long tail. Newsrooms, documentation sites, universities, government service portals, B2B SaaS companies, nonprofits, niche ecommerce stores, and agencies often need to understand small slices. A national retailer may have huge traffic on main categories. A specialist manufacturer may have a handful of high-intent visitors on a technical product page. For the manufacturer, a tiny segment may be commercially decisive.
The counterargument is that sampling is not always harmful. Large platforms can sample data well, and for broad trends the difference may be immaterial. The real problem is opacity and mismatch. If an analyst knows a report is sampled and uses it for directional analysis, fine. If a manager treats sampled, thresholded, or modeled figures as exact proof, the organisation is at risk. Matomo’s value is partly psychological: it reduces one class of invisible estimation from the reporting process.
Segmentation is where modern analytics creates most of its value. A total conversion rate says little. Teams need conversion rate by source, landing page, device, content intent, returning status, geography, campaign, product category, plan type, form path, and funnel stage. Each cut reduces volume. Each additional dimension increases the chance that sampling, thresholding, or missing consented users will distort the view. When an analytics platform preserves unsampled collected data, those cuts become easier to trust.
There is still a second risk: false precision. Unsampled collected data can look exact while excluding uncollected users. Matomo may report 2,000 visits to a page. If blockers and consent choices prevent another 500 from being collected, the number is still incomplete. The advantage is that the 2,000 collected visits are not sampled down by the platform. Teams still need to understand collection loss.
This distinction should shape reporting language. Instead of saying “the site had 100,000 visitors,” a careful analyst might say “Matomo collected 100,000 visits under the current privacy configuration.” That wording sounds cautious, but it is honest. It avoids pretending that analytics tools can observe everyone. It also makes changes in configuration easier to explain. If a site moves from consented analytics to a compliant consent-exempt Matomo setup in France, reported traffic may rise because fewer visitors are excluded at the banner stage. That does not mean demand suddenly grew; it means measurement coverage improved.
The best analytics teams separate collection coverage, reporting treatment, and business interpretation. Matomo’s no-sampling model addresses the reporting-treatment layer. Its privacy-first configuration may address part of the collection-coverage layer. Business interpretation remains human work.
This is why Matomo’s pitch should not be read as “we are always more accurate than every other platform.” The better claim is that Matomo gives teams more control over the conditions that make accuracy possible: first-party ownership, privacy configuration, no sampling, and auditability. For segment-heavy teams, those conditions are not minor. They decide whether analytics remains useful once the question becomes specific.
Google Analytics remains powerful but not neutral infrastructure
Any serious Matomo analysis has to treat Google Analytics fairly. GA4 remains one of the most widely used analytics platforms because it is free at entry level, tightly connected to Google Ads, familiar to marketers, supported by a huge training market, integrated with Google Tag Manager and Looker Studio, and backed by Google’s infrastructure. For many advertisers, GA4 is not optional because it sits inside the measurement and bidding system they use every day.
The issue is not whether Google Analytics is powerful. It is. The issue is whether it is neutral infrastructure for every organisation. It is not neutral in the way self-hosted analytics is neutral. It is part of a larger advertising, identity, consent, modeling, and platform ecosystem. Google’s Consent Mode documentation says consent mode controls data collection based on user consent for advertising and analytics purposes, and its consent mode reference includes parameters such as ad_storage, analytics_storage, ad_user_data, and ad_personalization.
For advertisers, those features can be useful. Consent Mode lets Google tags adapt to consent states and supports measurement under tighter privacy rules. Yet the model also reinforces dependence on Google’s ecosystem. Missing data may be addressed through consent signals and modeling within Google’s platform logic. That may be acceptable for paid-media management. It may be less attractive for organisations that want analytics as a standalone internal record.
Matomo’s critique of Google Analytics centres on ownership, privacy, and sampling. Its data ownership page says Matomo users own their analytics data and that external parties are not looking in. Its no-sampling page contrasts Matomo’s unsampled reports with Google Analytics sampling thresholds. Its privacy pages position Matomo as a Google Analytics alternative for organisations that want control.
The comparison should not become cartoonish. GA4 has improved privacy controls compared with older analytics models, and Google’s documentation around consent, retention, thresholds, and reports is extensive. Many teams can configure GA4 in privacy-aware ways. The problem is that GA4’s strengths are tied to Google’s advertising context. For organisations that do little paid media or that have strict public-interest, education, healthcare, or government obligations, that context may be a liability.
There is also a procurement issue. Buying or adopting analytics is not only a marketing decision anymore. Legal, security, procurement, IT, product, and executive teams may all have a stake. A marketing team may prefer GA4 because it knows the interface and needs Google Ads integration. A data protection officer may prefer Matomo because ownership and configuration are clearer. Engineering may prefer self-hosting if it already operates internal infrastructure. Finance may compare cloud pricing, support costs, and staff time. The right stack may include both GA4 and Matomo for different purposes, at least during transition.
A dual setup can work if the organisation is honest about roles. GA4 can support advertising workflows and Google campaign measurement. Matomo can serve as the owned first-party behavioural record. Server logs can validate traffic changes. Backend systems can confirm revenue and leads. The danger is double-counting or using conflicting numbers without explaining why they differ.
The real choice is not “Matomo or Google” in every case. It is whether the organisation needs an owned analytics layer that does not depend on an advertising platform’s reporting rules. Many do. Some do not. The answer depends on privacy risk, paid-media dependency, internal skills, regulatory exposure, reporting needs, and how much trust the organisation places in platform-modeled measurement.
Matomo’s opportunity is to win the organisations that have outgrown casual analytics but do not want to surrender measurement governance. That includes teams that still use Google Ads. An owned analytics layer can coexist with paid-media tools. It simply prevents paid-media platforms from becoming the only lens through which the business sees its audience.
Browser privacy has changed the ground under analytics
Browser privacy features have quietly rewritten the rules of web measurement. For years, analytics tools could assume that cookies, identifiers, and scripts would behave consistently enough across browsers. That assumption is gone. Safari, Firefox, Chrome, Brave, Edge, mobile in-app browsers, corporate browsers, and privacy extensions now create different measurement conditions. A visitor’s browser is no longer just a rendering engine. It is a privacy policy in software form.
Apple’s WebKit introduced Intelligent Tracking Prevention in 2017 to reduce cross-site tracking by limiting cookies and other website data. Mozilla’s Firefox Enhanced Tracking Protection blocks trackers that follow users across the web and includes protections against harmful scripts. Google’s Chrome strategy has changed more slowly and more visibly because Chrome carries enormous advertising-market weight, but Google said in April 2025 it would maintain its current approach to third-party-cookie choice while continuing to invest in tracking protections such as IP Protection in Incognito mode.
For analytics teams, the lesson is that browser privacy is not a single event. It is an ongoing drift. Even if third-party cookies remain available in Chrome settings, many users reject, delete, block, or limit identifiers. Safari and Firefox have already trained teams to expect weaker long-term identification. Mobile operating systems and app ecosystems add their own constraints. Browser privacy does not kill analytics, but it punishes analytics models that depend on persistent cross-site identity.
Matomo fits this shift because it focuses on first-party analytics. First-party does not mean automatically exempt from law or immune to blocking. It does mean the measurement purpose can be narrower and easier to explain. A site measuring its own audience for its own reports has a clearer privacy story than a network measuring users across many unrelated sites for advertising profiles.
The most important browser effect may be cultural, not technical. Users have learned that tracking is negotiable. They install blockers, browse privately, reject banners, use privacy browsers, and expect organisations to justify data collection. The web’s old bargain — free services in exchange for invisible tracking — no longer enjoys the same silent acceptance. That shift affects analytics even when the analytics is benign. A user who blocks all tracking does not inspect whether a script is used only for audience measurement. They block the category.
Privacy-first analytics is one answer to that cultural shift. It lets organisations say: we measure usage, but we limit collection, do not reuse your data for advertising, own the data ourselves, anonymise where possible, and give you rights or opt-out choices. That message will not persuade every blocker. It does create a more defensible relationship with users.
Browser privacy also changes benchmarking. A year-over-year traffic decline may reflect demand, SEO changes, consent design, browser mix, ad-block adoption, or implementation drift. A sudden drop in Safari returning users may reflect storage limits rather than brand weakness. A lower conversion rate among privacy browsers may reflect attribution loss. A higher direct-traffic share may reflect referrer stripping or campaign-tag loss. Analysts need to interpret reports with browser behaviour in mind.
Modern analytics cannot assume the browser is a passive measurement channel. The browser is an active participant in privacy enforcement. That is why platforms built around control, first-party measurement, and privacy settings have become more credible. They align with where browsers have been pushing the web: less cross-site tracking, less opaque identity, more user control, and fewer automatic assumptions that every action should be recorded forever.
Matomo is not the only platform in this category. Plausible, Fathom, Piwik PRO, Simple Analytics, Umami, and others speak to similar concerns in different ways. Matomo’s distinction is breadth. It offers a fuller analytics feature set, self-hosting, open source, unsampled reporting, GDPR tools, and a long history as a Google Analytics alternative. That breadth makes it attractive to teams that want privacy-first measurement without giving up the depth they associate with traditional analytics.
Ad blockers turn audience composition into measurement bias
Ad blockers are often discussed as a revenue problem for publishers and advertisers. For analytics teams, they are also a sampling problem created outside the analytics platform. If a large share of a site’s audience blocks analytics scripts, the visible audience becomes a subset shaped by privacy preference, technical skill, device type, geography, age, occupation, and browsing context. That subset may not behave like the full audience.
Backlinko’s 2026 update cites GWI data showing that 29.5% of internet users worldwide use ad blockers at least sometimes as of Q2 2025. Other sources and methods produce different numbers, but the direction is clear: ad blocking is not marginal. It is common enough that some sites should assume measurable analytics loss unless they have tested their own audience.
The bias is sharper in certain sectors. Developer tools, cybersecurity, open-source software, gaming, crypto, academic research, political news, privacy technology, and B2B technical products often attract users who are more likely to block scripts. A mainstream fashion retailer may see a different pattern. A public-health information site may see another. This makes universal claims dangerous. The right question is not “how much traffic do analytics tools miss?” The right question is “which users does this site’s current stack fail to measure, and does that failure change decisions?”
Matomo’s homepage claim about tools missing up to 40% of traffic should be interpreted through this audience-composition lens. For some sites, 40% may be too high. For others, especially those with privacy-conscious users and consent-heavy regions, it may be plausible. The number is less important than the discipline it forces: measure measurement loss. Compare Matomo with server logs. Compare consented and non-consented traffic where lawful. Review browser and device differences. Test blocker effects. Watch for unexplained gaps between ad clicks, server requests, and analytics sessions.
A first-party Matomo setup can reduce some blocking, especially when configured under the organisation’s own domain and kept separate from advertising patterns. Yet teams should not treat blocker avoidance as a license to ignore user intent. There is a line between reducing false positives against privacy-friendly audience measurement and deliberately circumventing a user’s expressed desire not to be tracked. The safer strategy is to make the analytics genuinely limited and privacy-preserving, then document it clearly. Technical resilience should follow privacy design, not replace it.
Ad blockers also reveal why analytics should be separated from advertising where possible. Users often install blockers because they dislike intrusive ads, performance drag, malware risk, or tracking. If an organisation’s analytics is bundled with advertising tags, it gets caught in the same rejection. If analytics is clearly first-party, limited, and not used for advertising profiles, it has a stronger case for collection, consent exemption in some jurisdictions, or user trust.
The business impact of blocker bias can be subtle. Suppose a documentation site sees low usage of advanced API pages. If the most advanced users block analytics, the report may push the team toward beginner content even though expert content drives enterprise deals. Suppose a news publisher sees high engagement among users who accept consent banners and low engagement among those who ignore them. The publisher may design for the most trackable readers, not the most loyal readers. Suppose a B2B buyer researches from a locked-down corporate browser and later converts through a different device. Attribution may credit the wrong channel.
Ad-blocking loss is not only a missing-number problem; it is a misread-audience problem. Matomo helps when it gives teams a better first-party measurement route, but the deeper fix is analytical humility. Every report should be read with a sense of who is absent.
Matomo’s open-source base changes procurement logic
Open source matters in analytics for reasons that go beyond licensing cost. It changes procurement, security review, vendor trust, and long-term resilience. Matomo describes itself as free and open-source software under the GNU General Public License v3 or later, and its GitHub repository is public. For organisations that care about inspectability, this is a material difference from closed analytics platforms.
Open source does not mean every buyer will read the code. Most will not. The value is that the code can be inspected, the community can review it, technical teams can understand how the platform behaves, and the organisation is not fully locked into a vendor’s private implementation. For governments, universities, nonprofits, research organisations, and technical companies, that transparency can matter in procurement. It also supports self-hosting, plugin ecosystems, and internal adaptation.
Matomo’s open-source base also gives it a different trust posture. A closed analytics vendor asks customers to trust documentation, contracts, certifications, and reputation. Matomo can ask for those too, but it also offers code visibility. This does not guarantee security. Vulnerabilities can exist in open-source software. Plugins can introduce risk. Self-hosted instances can be mismanaged. Yet open source gives organisations more ways to verify and control.
The procurement logic is especially strong when analytics is treated as public-interest infrastructure. A city, ministry, university, health organisation, or publicly funded body may not want citizen or student analytics routed through an advertising platform. Open-source analytics allows them to collect limited service-improvement data while retaining stronger control over hosting and governance. CNIL’s own guidance points to open-source software such as Matomo as a route for consent-exempt audience measurement when configured correctly.
Open source also affects exit risk. If a closed analytics vendor changes pricing, data terms, feature availability, export limits, or product direction, customers may have limited options. A self-hosted Matomo instance gives more continuity. The organisation can maintain its own data and decide upgrade timing. This is not always cheaper, because staff time and infrastructure matter. It is more controllable.
For agencies, the open-source model creates a different service opportunity. Instead of merely installing a SaaS tag, an agency can design a privacy-first measurement system: hosting choice, event taxonomy, consent rules, dashboard structure, data retention, ecommerce setup, server-log reconciliation, and governance documentation. That work is more strategic than dashboard configuration. It also makes agencies more accountable for data quality.
The drawback is responsibility. Closed platforms often hide operational complexity. Open-source and self-hosted platforms expose it. Someone must maintain the instance, handle backups, patch vulnerabilities, monitor storage, test plugins, and secure admin accounts. If an organisation installs Matomo and forgets it, the privacy story weakens. Poorly maintained self-hosting can be worse than well-managed cloud hosting.
Open source gives buyers more control, but it also reveals whether they are ready to control anything. Matomo’s cloud option exists partly because many teams want the governance benefits of Matomo without operating the server themselves. That is a sensible middle path for organisations without infrastructure capacity.
The broader market significance is that open source gives Matomo credibility at a time when analytics buyers distrust black boxes. Measurement is too close to customer behaviour, regulatory exposure, and strategic decision-making to be treated as a disposable plugin. Open-source roots make Matomo feel less like a vendor dashboard and more like infrastructure a serious organisation can own, inspect, and adapt.
Cloud versus self-hosted is a governance decision
Matomo’s two main deployment paths create a choice that is often misunderstood. Cloud is not automatically less private, and self-hosted is not automatically safer. The right option depends on governance needs, technical maturity, risk tolerance, budget, and the type of data being collected. Matomo says both Matomo On-Premise and Matomo Cloud can be configured for certain consent-exemption requirements, while its on-premise documentation covers installation, maintenance, security, updates, plugins, themes, and troubleshooting.
Self-hosting gives maximum infrastructure control. The organisation decides where the server runs, who has admin access, how backups work, what retention policy is enforced, and how data is protected. For regulated organisations, public-sector bodies, and technically mature companies, this can be the strongest option. It also supports internal integration and long-term independence.
Cloud reduces operational burden. Matomo Cloud lets teams avoid running the server, patching the application, and managing infrastructure directly. For small marketing teams, agencies, nonprofits, and companies without DevOps capacity, this may produce better real-world security than a neglected self-hosted install. A self-hosted platform maintained by no one is not a privacy win.
The governance question should start with accountability. Who owns the analytics service? If the answer is “marketing,” cloud may be safer unless marketing has technical support. If the answer is “IT and data protection,” self-hosting may fit. If the answer is “nobody,” the organisation is not ready for serious analytics, regardless of vendor.
Hosting also affects incident response. A self-hosted team must know how to respond if credentials leak, data grows too fast, plugins fail, or a server is compromised. A cloud customer needs vendor contracts, processing terms, access controls, and a clear understanding of where data is stored and who can access it. Both models require review.
Data residency may drive the decision. Some organisations need analytics data to remain in a specific country or region. Self-hosting makes this more directly controllable. Cloud hosting may still satisfy requirements depending on the provider’s region and contract, but the organisation must verify it. This is especially important for public-sector procurement, health data environments, and entities with strict internal policies.
Performance is another factor. High-traffic sites need archiving, database tuning, storage planning, and report performance management. Matomo On-Premise can scale, but it must be operated properly. Teams that underestimate traffic, retention, or event volume may create slow reports and frustrated users. Cloud can shift part of that burden to Matomo, though cost and plan limits still matter.
The hosting choice is not a technical footnote; it is the practical expression of the organisation’s data ownership claim. If a company says it wants full control but has no one to maintain the system, the claim is hollow. If it says it wants privacy but sends unnecessary personal data into any analytics platform, hosting will not fix the issue. Governance is a stack: purpose, configuration, hosting, access, retention, documentation, and review.
Matomo’s advantage is that it lets organisations choose their governance level. A startup can begin with cloud and privacy-aware defaults. A public body can self-host. An agency can run managed Matomo environments for clients. A large company can integrate Matomo into existing infrastructure and reporting workflows. This flexibility is part of the product’s strategic appeal.
The best implementation decision is usually made in a joint session between marketing, analytics, legal, IT, and security. The question should not be “Which option is easiest?” It should be “Which option will still be defensible two years from now when traffic grows, privacy rules shift, and more teams depend on the data?”
Setup in minutes does not remove implementation discipline
Matomo’s fast setup message is credible in a narrow sense. Its GitHub repository describes a five-minute installation process after which users receive JavaScript tracking code to place on websites. Matomo’s homepage also says teams can set up the platform in minutes. For a basic website, that may be true. A working dashboard can appear quickly.
The danger is confusing installation with implementation. Installing an analytics tag is the easiest part of measurement. The hard part is deciding what should be measured, how privacy rules apply, which events matter, how consent is handled, how internal traffic is excluded, how campaign parameters are governed, how ecommerce revenue is validated, how reporting is structured, and who reviews changes. A site can be “set up” in minutes and still produce untrustworthy data for years.
A disciplined Matomo implementation starts with purpose. Is the site measuring audience trends, content performance, marketing attribution, product behaviour, ecommerce conversion, intranet usage, or public-service access? Each purpose implies different data needs and privacy risks. Audience measurement may need pageviews, referrers, device class, approximate geography, and limited session data. Ecommerce may need product views, cart events, purchases, revenue, coupons, and checkout steps. Product analytics may need feature events and cohorts. Heatmaps and session recordings create their own privacy questions.
Matomo’s features include web analytics, ecommerce, goals, funnels, heatmaps, session recordings, custom reports, A/B testing, tag management, and more. Its heatmap and session recording documentation says those features track clicks, mouse movements, scrolls, form interactions, and page changes, and Matomo separately documents data masking for those features. These tools can be useful, but they are not privacy-neutral.
The implementation plan should separate basic analytics from sensitive behavioural tools. A team may deploy core Matomo in a privacy-friendly configuration while requiring consent for heatmaps, session recordings, or ecommerce features that go beyond a consent exemption. Matomo’s own CNIL ecommerce FAQ warns that features beyond exemption conditions need explicit consent before collection.
Event design is the next discipline. A clean tracking plan defines event names, categories, properties, allowed values, firing rules, consent requirements, and reporting purpose. It prevents the drift that ruins analytics: duplicate events, inconsistent naming, unused parameters, personal data in URLs, unreviewed custom dimensions, and events that fire on page load instead of user action. The smaller the organisation, the more tempting it is to skip this plan. The cost appears later when no one trusts reports.
Validation is just as important. Teams should compare Matomo pageviews with server requests, test with ad blockers, check consent-state behaviour, verify ecommerce totals against backend orders, inspect campaign tags, test across browsers, and document expected differences. A privacy-first stack should be tested under privacy conditions, not only in a clean browser with all scripts allowed.
Fast setup is useful only when it leads to controlled measurement, not when it creates a false sense of readiness. Matomo’s speed lowers the barrier to starting. It should not lower the standard for governance. The teams that get the most from Matomo will treat the initial setup as the first sprint, not the finish line.
Event design decides whether teams trust the platform
Most analytics distrust starts with event confusion. A marketing manager sees one number. A product manager sees another. The ecommerce platform reports a different revenue figure. The CRM shows fewer leads. The ad platform claims more conversions. Everyone blames the analytics tool. Often the root cause is not the tool. It is event design.
Matomo gives teams flexibility to track goals, events, ecommerce actions, campaigns, funnels, and custom dimensions. Flexibility is powerful, but without rules it creates noise. A button click can be tracked as a click, a goal, a form event, and a conversion. A purchase can fire twice if the thank-you page reloads. A lead can be counted before validation or after validation. A campaign can be split across five source names because UTM rules were not enforced. A returning user can be difficult to identify in a cookieless setup. These are design choices, not platform mysteries.
A strong Matomo tracking plan should begin with a measurement dictionary. Every key event needs a definition written in plain language. “Lead submitted” should state whether spam submissions are included, whether validation occurs before the event, whether duplicate form sends are counted, whether consent is required, and which fields are sent. “Product added to cart” should state whether quantity changes fire new events. “Trial started” should state whether it counts account creation, email confirmation, first login, or activation.
Privacy review belongs inside that dictionary. Each event should state whether it contains personal data or identifiers. URLs should be checked for email addresses, search terms, account IDs, or tokens. Custom dimensions should avoid unnecessary user-level data. IP anonymisation and geolocation settings should match the privacy notice. Retention should match business need. Consent or opt-out status should be respected.
Matomo’s privacy documentation provides the controls, but the team decides how to use them. Its user guide covers anonymising data, cookies, consent, informing users, opt-out tools, and data retention. That documentation is not a substitute for local governance; it is the reference material that makes governance possible.
The event plan should also identify source-of-truth hierarchy. Matomo may be the source for website behaviour. The ecommerce backend should be the source for final revenue. The CRM should be the source for qualified leads. The billing system should be the source for paid accounts. Search Console should be the source for search impression data. Ad platforms should be treated as media-delivery records, not final business truth. This prevents dashboard fights.
Trust grows when discrepancies are expected and explained. If Matomo reports fewer conversions than Google Ads, the team should know whether the difference comes from attribution windows, consent loss, cross-device paths, view-through conversions, duplicate prevention, or backend validation. If Matomo reports more organic traffic than GA4 after a privacy-first setup, the team should know whether consent configuration changed measurement coverage.
Event design is where privacy, accuracy, and business meaning meet. A privacy-first analytics platform gives the team permission to collect less. A good tracking plan decides what remains. The strongest Matomo implementations will not be the ones with the most events. They will be the ones where every event has a reason, a definition, a privacy status, and an owner.
This is also where agencies can create real value. Many organisations do not need another dashboard. They need a measurement operating system: naming rules, event governance, consent mapping, reporting standards, QA routines, and change control. Matomo provides the infrastructure; implementation discipline turns it into trusted intelligence.
Marketing attribution gets cleaner when consent and ownership are explicit
Marketing attribution is where analytics tools face their harshest expectations. Executives want to know which channels produce revenue. Paid-media teams want conversion feedback. SEO teams want proof of organic value. Content teams want assisted-conversion evidence. Email teams want lifecycle impact. Agencies want client reporting. Attribution promises clarity, but it often produces false confidence because it depends on identifiers, cookies, consent, redirects, campaign tags, browser storage, and platform-specific rules.
A privacy-first Matomo setup will not solve attribution perfectly. No lawful analytics tool can see every journey across devices, browsers, apps, and consent states. What Matomo offers is a cleaner first-party base. The organisation can define campaign parameters, track onsite behaviour, record conversions it collects, avoid data sampling, and keep the data under its own control. That reduces dependence on ad-platform self-reporting.
Google’s Consent Mode shows how much attribution has moved into platform-controlled consent and modeling systems. Google documentation says consent mode lets sites control data collection based on user consent for advertising and analytics, with parameters that govern storage and ad-related data use. For advertisers, this is important infrastructure. For independent analysis, it means part of the measurement logic sits inside Google’s ecosystem.
Matomo’s model is more direct: track the site, own the data, report unsampled collected events, and configure privacy. This is attractive for teams that want to compare paid channels without letting each ad platform grade its own homework. A paid social platform may claim conversions under its attribution window. Google Ads may report modeled or attributed conversions. Matomo can provide the site-side view of what arrived, what users did, and which collected conversions occurred under the organisation’s rules.
Campaign hygiene becomes central. Matomo will not rescue chaotic UTMs. Source, medium, campaign, content, and term parameters need consistent naming. Paid and organic social need separation. Email campaigns need stable conventions. Affiliates need controlled identifiers. QR codes, offline campaigns, influencer links, and partner links need naming rules. Without this, first-party analytics simply records inconsistent input.
Privacy also shapes attribution depth. A consent-exempt audience-measurement setup may not support the full campaign or user-level detail a marketer wants. Matomo’s CNIL-related documentation makes clear that consent exemptions require strict limits, and some campaign or ecommerce features may fall outside those limits depending on configuration and jurisdiction. The team must choose between broader coverage under narrow measurement and richer attribution under consent.
That trade-off is uncomfortable but healthy. It forces marketers to ask which attribution questions are worth extra privacy burden. Do they need user-level paths, or are channel-level trends enough? Do they need retargeting audiences, or only landing-page performance? Do they need session recording for every visitor, or sampled UX research with consent? Do they need personal identifiers in analytics, or can backend systems handle customer-level analysis after a lawful conversion?
Explicit consent and ownership make attribution less magical but more honest. Instead of pretending every conversion can be assigned perfectly, teams can define what they measure, what they cannot measure, and which decisions the data can support. That honesty is a competitive advantage when budgets are tight. It prevents overinvestment in channels that look strong only because their users are easier to track.
Matomo’s role in marketing attribution is strongest as an independent site-side record. It does not need to replace every ad-platform report. It should challenge them. When Matomo, backend revenue, and ad-platform numbers move in the same direction, confidence rises. When they diverge, the team has a reason to investigate before moving budget.
Product teams need behavioural signals without accidental surveillance
Product analytics and web analytics have been converging. Websites now include onboarding flows, account dashboards, pricing calculators, product tours, documentation portals, self-service checkout, communities, and support journeys. Product teams need behavioural signals to fix friction. Yet product analytics can quickly become surveillance if teams collect user-level detail without clear purpose, retention, or consent.
Matomo sits in an interesting middle ground. It is deeper than lightweight privacy analytics tools but more controllable than many product analytics platforms tied to extensive user profiles. Its features can support funnels, goals, events, custom dimensions, heatmaps, session recordings, and ecommerce. Used carefully, that can give product teams enough behavioural insight without defaulting to invasive collection.
The first rule is to separate aggregate product insight from user monitoring. Product teams often need to know where users drop off, which features are used, which documentation pages reduce support demand, which onboarding steps fail, and which device types struggle. Those questions can often be answered with aggregate events and limited identifiers. They do not always require watching individual sessions or storing detailed user profiles.
Session recording and heatmaps require extra care. Matomo’s documentation says heatmap and session recording features track clicks, mouse movements, scrolls, form interactions, and page changes, and that interactions can be replayed or visualised. Matomo also documents data masking and minimisation for these features. These controls are necessary because behavioural replay can capture sensitive context if deployed carelessly.
A mature product team should treat behavioural recording as a controlled research method, not an always-on default. It should be limited to specific pages, masked aggressively, reviewed under consent requirements, excluded from sensitive flows, and retained briefly. For many teams, aggregate funnels and event reports will answer most questions with less risk.
Privacy-first product analytics also improves internal trust. Engineers are more likely to support analytics when event requests are precise and limited. Legal teams are more likely to approve tracking when product managers can explain why each event is needed. Users are more likely to accept measurement when it is disclosed clearly and not tied to advertising reuse. Matomo’s ownership model strengthens that trust because product data can remain under the organisation’s control.
Product analytics needs a different success metric from marketing analytics. Marketing often asks, “Which channel brought this user?” Product asks, “Where did this user struggle?” The second question can be answered without building a permanent behavioural dossier. A privacy-first setup encourages teams to use enough data to improve the product, not enough data to reconstruct every visitor’s life.
The best product insight often comes from restrained measurement plus direct research. Matomo can identify drop-off points. User interviews, support tickets, usability tests, and feedback forms explain why drop-off happens. Teams that rely only on replay and click data may miss motivation. Teams that combine aggregate analytics with qualitative research get a clearer view while collecting less.
This is where Matomo’s breadth matters. A lightweight analytics tool may be too shallow for product teams. A full product analytics suite may be too identity-heavy for privacy-sensitive organisations. Matomo offers a middle path, especially for teams that want self-hosting, GDPR tools, and behavioural features they can enable selectively. The platform’s value depends on restraint. Without restraint, any analytics tool can become invasive.
Ecommerce teams face the hardest trade-offs
Ecommerce analytics is where privacy-first principles meet commercial pressure. Retailers want to know which channels drive orders, which products get viewed, where carts are abandoned, which coupons work, which checkout steps fail, which categories have high intent, and which customers return. Much of that measurement is legitimate business analysis. Some of it can also become personal, behavioural, and advertising-linked very quickly.
Matomo supports ecommerce tracking, goals, funnels, and campaign analysis. That makes it useful for merchants that want more ownership than ad-platform dashboards provide. Yet ecommerce teams need to be careful with consent and exemption claims. Matomo’s CNIL ecommerce guidance says audience measurement may be exempt under strict conditions, while features beyond CNIL exemptions, including ecommerce analytics in certain forms, may require explicit consent before collection.
The reason is purpose. Basic audience measurement is one thing. Tracking product interest, cart actions, revenue, coupons, customer types, and purchase paths is closer to commercial profiling, especially when linked to user IDs, email addresses, CRM records, or ad remarketing. Even when the purpose is internal analysis, the data can be sensitive because it reveals preferences, needs, finances, health interests, family status, or professional intent depending on the product category.
A privacy-first ecommerce setup should define layers. The first layer might collect aggregate audience measurement with strict privacy settings. The second layer might collect consented ecommerce events. The third layer might connect purchases to backend systems for order analysis under a separate lawful basis. The fourth layer might use advertising pixels only when valid consent exists. Keeping those layers separate prevents one consent decision from being stretched across unrelated purposes.
Matomo can serve as the owned ecommerce analytics layer, but it should not be the only commercial source of truth. The ecommerce platform or order-management system should remain the final record for revenue, refunds, taxes, shipping, and inventory. Matomo can explain behaviour before purchase: product views, cart starts, checkout exits, campaign paths, content influence, and onsite search. Revenue reconciliation should be routine because analytics tags can fail, duplicate, or miss orders.
Ecommerce teams also need to understand that higher reported traffic after a Matomo migration may change conversion rates. If Matomo captures more visits than a consent-limited or blocker-sensitive tool, the denominator grows. Revenue may stay the same. Conversion rate may appear lower even though measurement improved. This can surprise executives. The team should explain that better traffic coverage can make rates look different, not worse.
Privacy-first ecommerce analytics is not about collecting less commercial intelligence; it is about collecting commercial intelligence with cleaner boundaries. Merchants still need to know what works. They also need to avoid treating every browsing action as permission for retargeting, personalisation, or profile enrichment.
A good Matomo ecommerce deployment includes consent-state testing, duplicate purchase prevention, refund reconciliation, campaign naming governance, checkout-step validation, internal traffic exclusion, bot filtering review, and privacy notice updates. It should also define which reports are safe for broad internal access. Product category trends may be widely useful. User-level paths may require restricted access or may not be needed at all.
Ecommerce is demanding because the business value of detailed analytics is real. That is exactly why privacy-first design matters. The more valuable the data is, the more carefully it should be handled.
Agencies and consultants get a clearer audit trail
Digital agencies live with analytics distrust every day. Clients ask why GA4 differs from Shopify, why Google Ads claims more conversions than the CRM, why traffic fell after a cookie banner change, why organic search looks weaker than Search Console suggests, why a campaign has clicks but no sessions, and why last month’s dashboard cannot be reproduced. Agencies that answer with vague platform excuses lose trust.
Matomo gives agencies a chance to build analytics programs around clearer ownership and documentation. A Matomo implementation can include a measurement plan, privacy configuration, consent mapping, event dictionary, dashboard definitions, access roles, retention rules, and QA logs. Because the platform can be self-hosted or cloud-hosted and offers no sampling, agencies can give clients a more inspectable base than a black-box-only setup.
The audit trail matters for two reasons. First, clients increasingly ask privacy questions. They want to know whether analytics data is shared with advertising vendors, whether consent is needed, whether IP addresses are anonymised, whether data is stored in Europe, whether users can opt out, and whether reports are sampled. Matomo’s documentation gives agencies concrete answers to build from.
Second, analytics work is becoming a retention service rather than a one-off install. Agencies that set up a dashboard and disappear will struggle because tracking breaks as websites change. Agencies that run quarterly measurement audits, consent checks, event reviews, and report reconciliation become harder to replace. Matomo fits that service model because the value lies in governed measurement, not just access to a free dashboard.
Agencies should be careful not to oversell Matomo as a cure for every reporting dispute. It will not make ad platforms agree with backend revenue. It will not identify users who lawfully refuse tracking. It will not fix poor campaign naming by itself. It will not remove the need for legal review. The promise should be more precise: Matomo gives the client an owned, privacy-first, unsampled view of collected onsite behaviour, with configuration choices that can be documented and reviewed.
This precision improves client conversations. If traffic rises after migration, the agency can explain collection differences. If a report excludes heatmap data because consent is not present, the agency can explain the privacy boundary. If a client wants to connect analytics with CRM records, the agency can flag the legal and purpose implications. If a regulator or internal DPO asks for evidence, the agency can provide configuration screenshots and documentation.
The agency opportunity is not “install Matomo.” It is “build a measurement system the client can trust under privacy pressure.” That includes training. Clients need to understand collected visits versus actual visits, attribution limits, consent effects, sampling differences, and source-of-truth hierarchy. A good agency makes the client smarter, not dependent.
Matomo also gives agencies a differentiated offer for public-sector, education, nonprofit, and European clients. Many of these organisations want analytics but are uncomfortable with advertising-platform dependency. A privacy-first Matomo package with clear documentation, hosting options, and compliance review can answer that demand. It moves analytics from a commodity service to a governance and strategy service.
The risk is capability. Agencies must understand technical implementation, privacy rules, server-side realities, and data quality. A superficial Matomo migration can damage trust if the agency promises legal certainty or perfect accuracy. The better agencies will be humble and specific. They will work with legal advisors where needed, document assumptions, and test the setup carefully.
Security, retention and access controls decide the real privacy level
Privacy-first analytics is only as strong as its operational controls. A platform can offer anonymisation, opt-out tools, and self-hosting, but privacy fails if admin passwords are shared, old accounts remain active, raw data is retained forever, exports are emailed carelessly, backups are unencrypted, or plugins are installed without review. Privacy is not a product attribute alone; it is a maintenance habit.
Matomo’s privacy tools give teams building blocks: anonymisation, consent controls, opt-out features, data retention settings, GDPR-related data access and deletion support, and guidance around ePrivacy. These features are useful only when tied to internal policy.
Retention should be the first policy. Teams often keep analytics data indefinitely because storage is cheap and historical comparisons feel useful. GDPR’s storage limitation principle pushes the opposite question: how long is the data needed for the stated purpose? Aggregate trend data may be useful for years. Raw visitor logs may not be. Heatmap or session recording data should usually have short retention. Ecommerce analytics may need alignment with business reporting periods but not indefinite behavioural storage.
Access control is the second policy. Not everyone needs raw analytics access. Executives may need dashboards. Marketing may need campaign reports. Product may need funnels. Developers may need debugging access. Legal may need exports for rights requests. Admin privileges should be restricted. Agency accounts should be reviewed. Departed employees should be removed. Two-factor authentication should be used where available. Self-hosted instances should sit behind appropriate network and application security controls.
Export control is often forgotten. Analytics data becomes more risky when exported into spreadsheets, BI tools, cloud drives, email attachments, or local machines. A privacy-first platform does not protect data after a user downloads it. Teams need rules for exports, sharing, deletion, and downstream use. If Matomo data is joined with CRM, sales, or support data, the privacy analysis changes because re-identification risk increases.
Security patching matters for self-hosted deployments. Matomo On-Premise gives control, but control includes responsibility for updates, server hardening, database backups, monitoring, and incident response. Matomo’s on-premise guide covers installation and maintenance topics, but the organisation must execute them.
Data minimisation should be revisited regularly. A team may start with limited page analytics and later add custom dimensions, user IDs, search terms, form events, or behavioural tools. Each addition should be reviewed. URLs should be scanned for accidental personal data. Internal site search may reveal sensitive user intent. Form analytics may touch fields that should never enter analytics. Heatmaps may expose page content. These risks are manageable when acknowledged early.
A mature Matomo governance file should include the tracking purpose, data categories, hosting model, access roles, retention periods, consent or exemption basis, privacy notice language, opt-out method, event dictionary, plugin list, data export rules, and review schedule. This may sound heavy for a small team. It is lighter than explaining a privacy incident without records.
The real test of privacy-first analytics is what happens six months after launch. Are settings still correct? Are new tags reviewed? Are old users removed? Is retention enforced? Are exports controlled? Are reports still aligned with the privacy notice? Matomo gives teams more control than many alternatives. Control must be exercised repeatedly.
The limits of a privacy-first platform
Matomo’s strengths are real, but buyers should understand its limits. The first limit is that privacy-first analytics cannot count users who refuse lawful tracking in contexts where consent is required. If a visitor declines consent for a feature that requires consent, the respectful outcome is not to collect that data. A platform that promises to recover everything regardless of user choice is not privacy-first.
The second limit is that cookieless tracking is not a universal legal escape hatch. Matomo’s own FAQ says cookieless or anonymised tools do not automatically remove consent requirements, and that ePrivacy laws apply beyond cookies. The EDPB’s technical guidance supports that broader view of terminal equipment access.
The third limit is implementation quality. Matomo can be configured poorly. A team can collect personal data in URLs, use long retention, enable intrusive features without consent, ignore opt-out requirements, misconfigure ecommerce, or install plugins that change the privacy profile. The platform’s privacy features reduce risk only when used correctly.
The fourth limit is ecosystem integration. Google Analytics has deep ties to Google Ads, Search Ads 360, Display & Video 360, Looker Studio, BigQuery workflows, and agency habits. Matomo can integrate with many systems, but it is not a one-for-one replacement for every Google marketing workflow. Teams that rely heavily on automated bidding and Google-native conversion feedback may still need GA4 or Google tags for advertising operations.
The fifth limit is talent. Many marketers know GA4, even if they complain about it. Fewer know Matomo deeply. A migration requires training, documentation, and report redesign. Stakeholders may initially distrust new numbers because they differ from old dashboards. Teams should plan a parallel reporting period, explain differences, and define new KPIs carefully.
The sixth limit is maintenance. Cloud reduces this burden, but self-hosted Matomo needs technical care. Organisations without IT support should not self-host casually. Security, backups, updates, performance, and access control are not optional.
The seventh limit is that more accurate collected data does not guarantee better decisions. Teams can still chase vanity metrics, overinterpret small samples, ignore qualitative evidence, or confuse correlation with causation. Analytics is a decision-support system, not a decision-maker.
These limits do not weaken Matomo’s case. They make the case more credible. A serious platform should not be sold as a miracle. It should be evaluated against specific needs: privacy posture, ownership requirements, reporting depth, deployment capacity, consent environment, ad ecosystem dependency, and internal skills.
Matomo is strongest for organisations that want control and are willing to operate that control. It is less ideal for teams that want a zero-effort advertising dashboard, have no appetite for governance, or need every possible ad-platform integration above all else.
The most honest buying question is: what problem are we solving? If the problem is GA4 interface frustration, Matomo may or may not be the answer. If the problem is data ownership, unsampled reporting, privacy alignment, consent-exempt audience measurement in qualifying setups, and reduced dependence on advertising platforms, Matomo deserves serious attention.
A privacy-first analytics platform can raise the quality of measurement. It cannot replace strategic discipline. The teams that win with Matomo will be the ones that use it to simplify their data supply chain, document choices, reduce unnecessary collection, and build reports around decisions rather than dashboards.
Competition is shifting from dashboards to governance
Analytics tools used to compete mainly on reports: real-time visitors, traffic sources, goals, funnels, ecommerce, custom dimensions, dashboards, exports, and visual design. Those features still matter. The more important competition now is governance. Buyers ask who owns the data, whether it is sampled, where it is stored, whether consent is needed, how rights requests are handled, whether the tool can be self-hosted, how long data is retained, and whether the platform is tied to advertising.
Matomo has positioned itself for this governance market. Its homepage highlights privacy-first analytics, accuracy, GDPR compliance, full data ownership, and fast setup. Its navigation emphasizes data ownership, privacy protection, open source, no data sampling, GDPR, and Google Analytics alternatives.
W3Techs reports that Matomo is used by 2.7% of websites whose traffic analysis tool is known and 1.5% of all websites, with daily updated methodology. Those numbers do not make Matomo dominant, but they show it is not a fringe experiment. It is a mature alternative with meaningful adoption.
The competitive set is broad. GA4 remains the default for many marketers. Adobe Analytics serves enterprise teams with complex needs. Piwik PRO positions around privacy and enterprise analytics. Plausible and Fathom offer lightweight privacy analytics. Simple Analytics, Umami, PostHog, Mixpanel, Amplitude, and others serve different points across web, product, and privacy needs. Matomo’s niche is unusually wide: deeper than minimalist tools, more ownership-focused than ad platforms, more accessible than some enterprise suites, and open source at the core.
Governance competition changes product priorities. A platform wins not only by adding charts but by making privacy settings enforceable, compliance status visible, exports controllable, data retention clear, and hosting choices flexible. Matomo’s 1-Click CNIL Compliance feature is a governance feature, not a chart feature. It makes legal configuration easier to operationalise.
This shift also changes buyer personas. Analytics used to be bought by marketing. Now legal, IT, security, procurement, data protection officers, product leaders, and executives influence the choice. A tool that delights marketers but worries legal may stall. A tool that satisfies legal but frustrates marketers may be ignored. Matomo’s challenge is to satisfy both: enough reporting depth for teams that need insight, enough governance clarity for teams that need control.
The market is moving because privacy has become a business continuity issue. A company that depends on a measurement model vulnerable to consent loss, browser changes, regulatory pressure, and platform policy shifts is exposed. Google’s long-running changes around third-party cookies and Privacy Sandbox show how platform strategy can shift over years, creating uncertainty for advertisers and publishers.
Matomo benefits from uncertainty because it offers a simpler premise: keep analytics close to the organisation and limit the data supply chain. That premise is not always enough, especially for companies deeply tied to ad-platform bidding. But for many organisations, it is exactly the point.
The next phase of analytics competition will reward tools that make measurement explainable. Dashboards are easy to copy. Trust is harder. Trust comes from ownership, transparency, configuration, documentation, and reports that do not hide their assumptions. Matomo’s product direction is aligned with that demand.
Practical migration path for teams considering Matomo
A Matomo migration should not begin with tag replacement. It should begin with measurement inventory. List every current analytics tag, advertising pixel, consent category, event, goal, ecommerce action, dashboard, report recipient, export, and integration. Identify which reports people actually use and which exist out of habit. Many migrations fail because teams blindly recreate old dashboards instead of improving the measurement model.
The second step is purpose sorting. Separate audience measurement, marketing attribution, ecommerce analytics, product behaviour, UX research, advertising retargeting, and compliance reporting. Each purpose may need a different lawful basis, consent treatment, retention period, and data depth. A privacy-first migration is a chance to stop mixing them.
The third step is deployment choice. Decide whether Matomo Cloud or On-Premise fits the organisation. On-premise gives more control but requires technical ownership. Cloud is faster and may be safer for teams without infrastructure support. Matomo’s own documentation supports both paths, with on-premise requirements and installation guidance available for teams that self-host.
The fourth step is privacy configuration. Decide whether cookies are used, whether IP addresses are anonymised, whether consent is required, whether an opt-out is offered, whether CNIL or other national exemption conditions are relevant, and whether behavioural features need separate consent. Matomo’s documentation on consent, cookieless tracking, CNIL configuration, GDPR tools, and ePrivacy differences should be used during this stage.
Migration checklist for a privacy-first Matomo rollout
| Step | Decision to make | Evidence to keep |
|---|---|---|
| Measurement inventory | Which current tags and reports matter | Tag list, report list, owner list |
| Privacy mapping | Which purposes need consent or exemption review | Consent matrix, legal notes |
| Hosting choice | Cloud or self-hosted | Hosting rationale, access plan |
| Event plan | Which events and dimensions are approved | Tracking dictionary |
| QA period | How old and new numbers differ | Reconciliation notes |
| Governance routine | Who reviews changes | Review calendar and change log |
The checklist keeps migration work concrete. It also creates records that help future teams understand why the setup looks the way it does.
The fifth step is parallel tracking. Run Matomo alongside the existing analytics system for a defined period. Do not expect the numbers to match. Compare trends, not only totals. Review browser differences, country differences, consent states, campaign attribution, ecommerce totals, and server-log references. Document the reasons for major gaps. This period builds stakeholder confidence.
The sixth step is reporting redesign. Recreate only the reports that support decisions. A privacy-first migration is a chance to remove vanity dashboards, unused metrics, and overcomplicated attribution views. Build dashboards around audiences: executive, marketing, content, ecommerce, product, support, and compliance. Give each group the metrics it needs, not every metric Matomo can produce.
The seventh step is training. Explain collected visits versus total real-world visits. Explain why Matomo may differ from GA4, Search Console, ad platforms, ecommerce platforms, and CRM records. Explain no sampling. Explain privacy settings. Explain what the team chose not to collect. This prevents panic when numbers change.
The eighth step is governance. Set a review cadence for new events, tags, plugins, reports, retention, access, and privacy documentation. Make someone accountable. Without an owner, analytics decay begins immediately.
The best Matomo migration is not a dashboard migration; it is a measurement reset. Teams that approach it this way get more than a new tool. They get a cleaner data model, a clearer privacy posture, and a stronger basis for decisions.
The strategic meaning of Matomo’s pitch
Matomo’s message is powerful because it connects three anxieties that used to be treated separately: analytics accuracy, privacy compliance, and data ownership. Marketers care about accuracy. Legal teams care about compliance. Executives care about control. Matomo ties them together and argues that the same architecture can serve all three.
That is the strategic core. If popular analytics tools miss substantial traffic because of blockers, consent loss, browser protections, sampling, or platform thresholds, then accuracy is not only a technical issue. If analytics data is processed inside advertising ecosystems, then ownership is not only a contract issue. If consent rules vary by country and configuration, then compliance is not only a banner issue. The analytics stack becomes part of business infrastructure.
Matomo’s strengths match this moment: privacy-first positioning, full data ownership, open source, self-hosting, cloud deployment, no sampling, GDPR tooling, CNIL-focused configuration, and a familiar web analytics feature set. Its April 2026 CNIL compliance feature shows a product direction focused on turning privacy requirements into operational controls.
The harder question is whether organisations are ready to act on the implications. Many say they want privacy-first analytics but still want unlimited tracking, ad retargeting, user-level profiles, long retention, effortless setup, perfect attribution, no legal review, and dashboards that match every old number. That bundle is unrealistic. Privacy-first analytics requires trade-offs. It may mean collecting less, documenting more, training stakeholders, and accepting that some data should remain unknowable.
Matomo does not remove those trade-offs. It makes them visible and easier to control. That is a more durable advantage than any single feature. Features change. Privacy rules change. Browser behaviour changes. Advertising platforms change. A system built around ownership and configuration is better prepared for change than a system built around silent dependency.
The strongest case for Matomo is not that every organisation should abandon its current stack tomorrow. The strongest case is that every organisation should ask whether its current analytics layer is still fit for the privacy era. Can it explain where data goes? Can it defend the legal basis? Can it report without sampling where needed? Can it separate internal audience measurement from advertising use? Can it keep data under organisational control? Can it adapt to national requirements? Can it reveal rather than hide measurement limits?
For many teams, the honest answer will be uncomfortable. They may discover that their analytics numbers depend on consent rates they do not monitor, tags they do not own, reports they do not understand, and platform rules they cannot audit. Matomo enters that discomfort with a clear proposition: measure more directly, own more of the data, configure privacy deliberately, and reduce avoidable blind spots.
The deeper shift is from analytics as a free dashboard to analytics as accountable infrastructure. Matomo is one of the clearest expressions of that shift. Its success will depend not only on product features, but on whether teams are ready to treat measurement with the seriousness they already give to CRM, finance, security, and customer data platforms.
Questions teams ask before trusting privacy-first analytics
Matomo can replace Google Analytics for many website analytics, content, ecommerce, and owned reporting needs. Teams that depend heavily on Google Ads, automated bidding, or Google-native advertising workflows may still keep GA4 or Google tags for media operations while using Matomo as the owned first-party analytics layer.
Matomo provides GDPR-related tools and privacy settings, but compliance depends on configuration, purpose, consent or exemption analysis, retention, documentation, and local law. A privacy-first platform gives teams the controls they need; it does not make every use automatically lawful.
In some setups and jurisdictions, Matomo can be configured without cookies or personal data, or under narrow consent exemptions. This is not universal. Matomo’s own documentation warns that cookieless or anonymised analytics does not automatically remove consent requirements across Europe.
Matomo’s data ownership claim means analytics data is controlled by the organisation using Matomo, especially in self-hosted deployments. The data is not positioned as part of an advertising platform’s broader data system.
Matomo says it does not use data sampling on its plans. That means reports are based on collected data rather than sampled subsets inside the platform, though teams still need to account for users who were not collected because of consent, blocking, or configuration.
Traffic can be missed when users reject consent, block scripts, use privacy browsers, browse through corporate filters, leave before tags load, or trigger reports subject to sampling or thresholding. The loss is often uneven across audience groups.
No. It should be treated as a claim that may apply in some traffic environments, not as a universal benchmark. The real gap depends on audience, country, browser mix, consent design, tag setup, blocker use, and analytics architecture.
Matomo can reduce some avoidable loss through first-party setup and privacy-friendly configuration, but privacy-first analytics should not be framed as ignoring user intent. The better goal is limited, transparent audience measurement that users and regulators can understand.
Yes. Matomo’s core is free and open-source software under the GNU GPL v3 or later, and its public GitHub repository is available for inspection and contribution.
Self-hosting gives the most control over infrastructure, storage, access, and retention. Matomo Cloud reduces operational burden. The better choice depends on technical capacity, regulatory needs, security maturity, and governance requirements.
Yes. Matomo supports ecommerce tracking and related reporting. Ecommerce teams still need to review consent, privacy, duplicate purchase tracking, backend reconciliation, and whether specific features fall outside audience-measurement exemptions.
Matomo offers heatmaps and session recordings, but these features need careful privacy review because they capture detailed behavioural interactions. Teams should use masking, limited scope, short retention, and consent where required.
Matomo can improve owned site behaviour analysis for SEO teams by showing landing-page engagement, content performance, conversions, and unsampled collected data. It does not replace Google Search Console for search impressions, queries, and indexing signals.
Matomo is often attractive to public-sector organisations because it supports self-hosting, data ownership, privacy controls, and configurations aligned with stricter audience-measurement rules. Public bodies still need local legal review and proper governance.
No, not exactly. Matomo and GA4 differ in collection rules, consent handling, identity models, reporting methods, attribution, thresholds, sampling, bot filtering, and configuration. A parallel tracking period helps explain differences.
CNIL compliance refers to configuring Matomo so audience measurement can fit French consent-exemption conditions where applicable. Matomo’s 1-Click CNIL Compliance feature helps assess and apply supported settings, while some checks remain the organisation’s responsibility.
Not necessarily. It often means clearer, more defensible data with known limits. Teams may lose some user-level detail but gain a more trustworthy first-party view and reduce dependence on advertising-platform reports.
Ownership should be shared across marketing, analytics, IT, security, and privacy roles, with one accountable service owner. Marketing alone should not control privacy settings, and IT alone should not define business metrics.
The biggest mistake is treating Matomo as a tag swap. A strong rollout needs measurement inventory, event design, privacy mapping, hosting decisions, QA, training, and ongoing governance.
Author:
Jan Bielik
CEO & Founder of Webiano Digital & Marketing Agency
This article is an original analysis supported by the sources cited below
Matomo homepage
Official Matomo page presenting its privacy-first analytics positioning, full data ownership claim, GDPR-compliant messaging, setup promise and traffic-loss claim.
Matomo data ownership
Official Matomo page explaining its position that analytics data belongs to the organisation using the platform.
Matomo privacy
Official Matomo page describing privacy-friendly analytics, data ownership and GDPR-oriented positioning.
Matomo no data sampling
Official Matomo page explaining its no-sampling claim and why unsampled reporting matters.
Matomo GDPR analytics
Official Matomo page covering GDPR Manager and privacy-related compliance features.
Matomo privacy user guide
Official Matomo guide gathering documentation on privacy, anonymisation, consent, opt-out tools and retention.
Matomo analytics without consent or cookie banner FAQ
Official Matomo FAQ explaining privacy-focused configurations that may avoid cookies or personal data in qualifying circumstances.
Matomo web analytics consent FAQ
Official Matomo FAQ explaining that cookieless or anonymised analytics does not automatically remove consent requirements.
Matomo ePrivacy and national implementations FAQ
Official Matomo documentation discussing differences in analytics consent requirements across European jurisdictions.
Matomo CNIL consent exemption configuration FAQ
Official Matomo FAQ detailing configuration and self-assessment for CNIL consent exemption alignment.
Matomo 1-Click CNIL compliance announcement
Official Matomo announcement describing its April 2026 1-Click CNIL Compliance feature.
Matomo features
Official Matomo feature list covering analytics, ecommerce, heatmaps, session recordings and related capabilities.
Matomo on-premise requirements
Official Matomo documentation for self-hosted deployment requirements.
Matomo on-premise guide
Official Matomo guide covering installation, maintenance, security and troubleshooting for self-hosted deployments.
Matomo GitHub repository
Public Matomo source repository describing the open-source analytics application and installation flow.
Matomo free and open-source software
Official Matomo page explaining its GNU GPL v3 or later open-source licensing position.
CNIL sheet n°16 on analytics
French data protection authority guidance on analytics cookies, consent and audience-measurement exemptions.
CNIL audience measurement tool solutions
French CNIL guidance on conditions under which audience-measurement trackers may be exempt from consent.
European Commission data protection
European Commission information on EU data protection rights, concepts and obligations under the GDPR framework.
EDPB guidelines on consent under GDPR
European Data Protection Board guidance on consent under Regulation 2016/679.
EDPB guidelines on the technical scope of Article 5(3) of the ePrivacy Directive
EDPB guidance explaining the technical scope of device storage and access rules under Article 5(3).
Google Consent Mode setup guide
Google developer documentation explaining consent mode for websites and Google tag behavior.
Google Analytics explorations documentation
Google Analytics documentation describing explorations, sampling and data thresholds.
Google Analytics data thresholds documentation
Google Analytics documentation explaining why data thresholds may apply to reports and explorations.
Google Analytics data retention documentation
Google Analytics documentation covering user and event data retention settings and Google-signals retention.
Google Privacy Sandbox next steps
Google April 2025 update on Chrome third-party-cookie choice and tracking protection plans.
WebKit Intelligent Tracking Prevention
Official WebKit blog post introducing Intelligent Tracking Prevention and its role in limiting cross-site tracking.
Mozilla Enhanced Tracking Protection
Mozilla support documentation describing Firefox Enhanced Tracking Protection and tracker blocking.
Backlinko ad blocker usage statistics
Backlinko’s 2026 ad-blocking statistics summary citing GWI data on worldwide ad-blocker use.
W3Techs Matomo usage statistics
W3Techs usage statistics for Matomo as a website traffic analysis tool.
ICO cookies and similar technologies guidance
UK Information Commissioner’s Office guidance on cookies, similar technologies, consent and PECR.
| Citing this article? Brief excerpts are welcome. Please credit Webiano.digital, name the author where stated, and include a link to https://webiano.digital and to this original article. Full or substantial republication requires prior written permission. Read our Copyright and Content Use Policy. |














