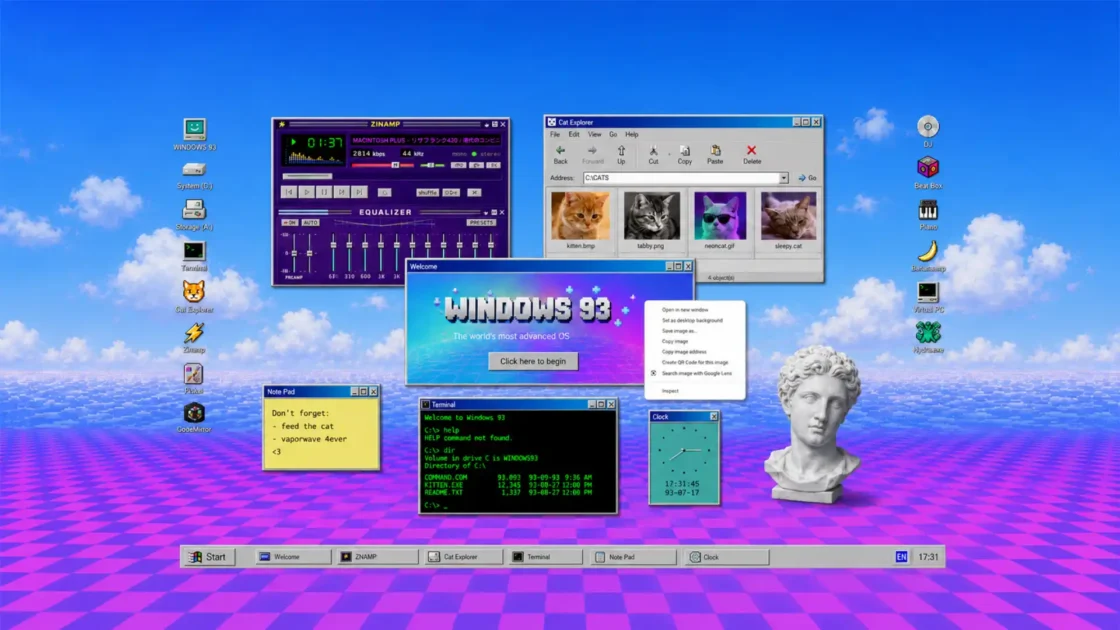
Web Shufflr does something most discovery products have trained themselves to avoid: it gives you one link, then gets out of the way. You choose a topic or accept the home page’s changing cluster of suggestions, press into the little portal, and land on somebody else’s corner of the web. The landing page is almost comically spare. There is a domain name, a category label, a way to give the pick a thumbs-up or thumbs-down, a flag button, and a route back. The site treats the click as the product. That is a bracing choice after years of feeds that bury the destination under a wall of reactions, prompts, panels, previews, and reasons to stay.
Table of Contents
The first surprise is how much this small restraint changes the feeling of browsing. Web Shufflr does not promise to know you. It does not collect a personality from your past attention, arrange a queue of content it believes will hold you, or turn curiosity into a streak. It asks a smaller question: what sort of thing do you want to stumble across right now? Books, music, mystery, Linux, handmade objects, 1980s pages, academic homepages, personal blogs. Pick a door. A stranger’s website appears on the other side.
That sounds slight until you notice what has disappeared from ordinary web discovery. Search begins with a goal. Social feeds begin with a social graph. Recommendation systems begin with a profile. Shufflr begins with a category and accepts that the result may surprise you. The experience has more in common with pulling a book at random from a shelf than typing a query into a box. It gives browsing back some of its old dignity: a willing act with no obvious commercial agenda attached.
The site frames itself as a collection of vintage and modern websites, sorted into topics for random browsing, and openly positions its project against clickbait, advertising pressure, and AI-generated spam. Its founding post says the collection started with older crawl data, followed by re-crawling surviving URLs, extracting text, and assigning sites to topics with an automated system. That mix of archive work and lightweight curation is the whole proposition. Web Shufflr is not trying to be a new social network. It is trying to make the open web feel findable again.
A one-link antidote to the feed
The contemporary feed flatters the user while quietly narrowing the room. It says every choice is personal, every suggestion is relevant, every scroll is yours. Then it repeats the same emotional temperature until a person mistakes familiarity for taste. Web Shufflr offers the opposite bargain: fewer assurances, more room. You do not get a polished prediction. You get a chance encounter shaped only by a broad interest and the odd judgment embedded in the collection.
A title such as “Web Shufflr” could have belonged to a louder product. It could have become a browser extension, a social app with daily streaks, or an AI concierge that talks at length about your interests. The actual site chooses a much humbler form. It is an index with an attitude. That modesty matters because it protects the moment of discovery from being turned into content about discovery. There is no elaborate ritual before the link. No synthetic enthusiasm. No dashboard telling you what your curiosity means.
The home page gives visitors a rotating selection of topic links and tells them to refresh for a new set. That sentence captures a rare design instinct: the page itself is not precious. The home page behaves like a shuffled drawer, not a shop window. It does not insist that its first arrangement is the best arrangement. Refreshing is part of the invitation, a small acknowledgment that a different jumble may suit a different mood.
That is why a collection of apparently ordinary topics becomes more interesting in use. “Books” may send you to an independent fiction site. “Linux” may reveal a page on old shareware. “Music” may open a musician’s personal site rather than an outlet with a search-engine strategy. The subject is a loose promise, not a content format. You are not entering a vertical packed with familiar templates. You are entering a bucket full of things that have retained enough life to remain reachable.
The practical interaction is almost austere. A random URL loader shows one destination and labels the category it came from; below it sit the feedback controls. It is a confidence game in the best sense. Shufflr trusts that the visitor will understand a hyperlink without a long explanation and trusts that the destination may be more memorable than a preview card. The interface understands that a good discovery tool should not compete with what it discovers.
This also makes the site pleasantly resistant to the false urgency of “infinite” browsing. A feed has no natural stopping point because stopping is bad for the feed. Shufflr has one after every click. Each destination is a clean decision point. Open it. Read it. Close it. Return. Try another. The rhythm feels less like consumption and more like wandering through a neighborhood where every house has chosen its own paint, its own porch furniture, and its own strange collection in the window.
The difference is not nostalgia alone. Nostalgia often smooths out old inconveniences until they look charming from a distance. Web Shufflr is better when read as a correction to a specific failure of current discovery: the web has plenty of pages, but the routes to them have become boring. Search is excellent at answering questions and weak at producing detours. The useful detour is where taste expands, where a reader meets a form of enthusiasm they did not know they wanted.
There is an emotional quietness to the site that deserves mention. No red badges beg to be cleared. No autoplay video tries to hold the room. No account asks to be created before curiosity is allowed. The absence of persuasion becomes its own feature. A person can visit for three minutes, follow one link, and leave with no digital residue except a new bookmark or a strange fact lodged in memory. That is a more generous relationship with attention than most web products manage.
The visual restraint also leaves room for the unreliable, personal, and unmarketable parts of the web. A database built for ad sales has little reason to surface a retired professor’s page, a stubbornly maintained fan site, a hobbyist’s late-1990s archive, or a niche blog whose author never learned the current rules of visibility. Shufflr gives those pages a route back into public life. It does not make them trendy. It lets them be found.
A human being may not enjoy every result. That is not a flaw to hide. It is the price of seeing beyond a preference profile. The occasional dud is evidence that the system is not only feeding you a softened version of yourself. A category can yield a stale site, an odd site, a misfit, or a page that once mattered more than it does now. The answer is not to demand a perfect stream. The answer is to keep the next click cheap.
The archive is the real machine
The part of Web Shufflr that gives it weight is not the front-end trick of random selection. Randomness is easy. The hard work sits behind the button: finding, keeping, sorting, and revisiting enough of the web that chance has something worth drawing from. The site’s launch post says the team works from crawl data from the 2010s and earlier, using repositories such as the Internet Archive to identify older URLs, then re-crawling them to see what still survives.
That process places Shufflr in an interesting middle ground between a web archive and a recommendation engine. A traditional archive preserves material and asks a visitor to know what they want. A recommendation service selects material but often focuses on the newly made, the rapidly shared, or the already rewarded. Shufflr tries to make preservation browseable. It turns the survival of obscure pages into a live discovery experience instead of a technical fact stored behind a search form.
The launch post puts the archive at more than 500,000 websites, while also admitting that most of those pages are not exciting: businesses, services, news sites, and other functional material. That admission is one of the most believable things about the project. A real archive contains an enormous amount of ordinary life. The value does not come from pretending every old URL is a jewel. It comes from admitting that rare interesting pages are difficult to locate precisely because they are scattered among a vast amount of normal web debris.
That is a better premise than the usual language of “hidden gems.” The phrase tends to assume that the internet is a mine full of sparkling prizes waiting for a clever app to reveal them. Web Shufflr’s own story is less romantic and more convincing. There are boring pages. There are broken pages. There are sites whose best years are behind them. There are personal sites that have quietly persisted. Discovery works because the collection is allowed to include the texture around the gems.
The archive’s age is part of the point. Older websites carry more than old design choices. They preserve a kind of authorial directness that has become less common: pages made by people who expected visitors to arrive by link exchange, directory listing, blogroll, search result, or pure accident. They were often written for an unknown reader rather than calibrated for a platform. Their pacing is different. Their navigation can be clumsy. Their voice is usually less filtered.
The site’s retro collections make that premise tangible. Its December 2025 post identifies categories for 2000s-era homepages, Angelfire and Tripod sites, personal blogs, and Blogspot blogs. The post explains that the first set came from mid-2000s crawl data, that only a small share of those URLs still work after two decades, and that the Blogspot collection mixes active blogs with abandoned ones. The archive does not treat the old web as a museum with ropes around it. It treats it as a partially inhabited city.
This distinction changes how a visitor reads a page. A perfectly frozen artifact asks to be admired for its age. A still-live personal homepage asks to be read as a present-tense object, even when its last update was years ago. There may be dead links and dated opinions. There may also be a list of books, a carefully maintained collection of scans, a personal archive, a cooking obsession, or an explanation of a niche technical problem that no search result now ranks. Shufflr makes room for the strange dignity of a page that never became a brand.
The automated sorting system is also worth taking seriously without treating it as magic. The site says it extracts main text and sorts websites into categories using automated evaluation, while warning that pages may change, go down, or slip through its filters. That warning is not a small footnote; it is the honest contract of the product. When the source material is the open web, categorization will be imperfect and destinations will mutate. A discovery site that claims otherwise would be selling a fiction.
There is a useful tension here. Automated classification gives the project enough scale to work with hundreds of thousands of candidates. Human taste is still visible in the idea of which categories deserve to exist, what counts as worth surfacing, and how much weirdness the system permits. Web Shufflr is not purely algorithmic and not purely hand-curated. It is a filtration project where machines do the broad sorting and human sensibility seems to shape the invitation.
The result is less glossy than a recommender trained on polished media metadata. That is a strength. A page about Linux can lead to something with the awkward charm of old web software culture. A books link may lead to a site that has no SEO strategy at all. The categories do not promise authority; they promise a direction of travel. This is browsing as a verb again, full of partial matches and accidental side streets.
A collection like this also makes fragility visible. The web often pretends that a link is permanent until it breaks, then treats the break as an isolated annoyance. Shufflr’s entire premise depends on knowing that survival is uneven. Every working older URL is a minor event. It has outlasted redesigns, hosting migrations, expired domains, personal pivots, company closures, and the social platforms that convinced people to stop owning their own pages.
That survival gives the site a quiet archival politics. It favors pages that remain independently reachable rather than fully absorbed into the feeds. It does not need to argue for a return to 2004 or pretend the old web was more democratic, safer, or technically better. Its stronger claim is practical: a web with independent pages is more interesting to explore. The evidence is in the links, not in a manifesto.
Randomness with a handrail
Pure randomness sounds liberating until it becomes a way of wasting a person’s time. A button that selects from the entire internet would mostly deliver junk, commerce, dead domains, and pages that make no sense without context. Web Shufflr avoids that trap by putting a handrail around chance. The topic is the handrail. It lets a visitor choose a mood without deciding every detail of the destination.
The category list is broader than it first appears. The site published 107 categories in December 2025, divided into broad, narrow, and specific topics. Broad topics include books, history, philosophy, science, software, music, travel, and animals. Narrow topics range from astronomy and birds to robotics, painting, libraries, and mythology. Specific labels move into much more personal territory: 1980s, comics, Halloween, DIY, Linux, puzzles, vintage, webgames, and World War II. The list feels less like a taxonomy and more like a shelf built by someone who enjoys browsing themselves.
The distinction between broad, narrow, and specific is useful because it changes the type of surprise. Choose “science” and you may get a wide, unpredictable slice of public knowledge. Choose “birds” and the field narrows but still leaves room for a birder’s diary, a conservation page, an old species index, or a personal photo archive. Choose “1980s” and the category itself becomes a cultural mood. The more specific door does not remove randomness; it gives randomness a character.
That is a more satisfying model than the ordinary filter menu. Filters usually exist to remove undesirable options from a catalogue. Shufflr’s topics exist to set the angle of a walk. They provide intention without turning the visit into a search task. You can enter “mystery” because you want atmosphere, not because you know the title of the page you need. You can enter “handmade” because you want to see what people make when no platform tells them how to package it.
The link pages make the mechanics visible. A visit to the academic-homepages category returned a researcher’s page at the University of Wisconsin. The books category returned a small independent site; Linux returned an old-looking page about “cheepware”; a Blogspot category returned a Blogger address. Each result page identifies the category and offers thumbs-up, thumbs-down, and report controls. The system does not conceal the fact that it is making a selection. It labels the selection and asks whether the match held up.
That feedback layer is easy to overlook because it is so small. Yet it is the practical mechanism that keeps a collection like this from becoming a dump. A link can remain live but no longer belong in its old category. A page can become spam. A domain can change hands. The thumbs and flag controls turn every visitor into a light-touch maintenance worker. The site does not overstate this contribution, which makes it feel more credible.
What the visit feels like
| Part of the experience | What Web Shufflr does | Why it changes the click |
|---|---|---|
| Topic choice | Lets you choose a broad or niche category | Chance has a direction |
| Destination | Shows one external website rather than a feed | The page, not the platform, gets your attention |
| Category label | Names the bucket that produced the link | You can judge the match honestly |
| Feedback | Offers thumbs-up, thumbs-down, and flagging | The archive has a way to correct itself |
| Refreshing | Changes the selection of visible topics on the home page | The entry point stays loose and playful |
The table captures why the site feels more considered than a “random website” novelty button. Every small constraint protects the quality of surprise. You retain agency at the start, see one destination at a time, and have a way to object when the match is poor. The interaction is tiny, but it respects the visitor more than a large system that hides its judgments behind vague relevance scores.
The academic-homepages addition is perhaps the clearest proof that categories can become editorial statements. Announced in January 2026, it contains nearly 10,000 personal homepages associated with researchers, laboratories, students, and faculty at US-based universities, sourced from a 2012 crawl repository. The site says some pages date back more than 25 years, while others are maintained today. That is not merely a category; it is an invitation to browse the intellectual web before professional identity became a polished LinkedIn-shaped surface.
Academic homepages are an especially rich kind of web object because they contain work, biography, hobby, teaching, and technical detritus in the same place. An academic’s page may list papers next to a bad photograph, a course handout, a favorite theorem, a personal note, an obsolete software project, and a link to a hobby site. The genre reminds us that a person’s public presence once had room to be uneven. It did not need to be a clean funnel toward professional credibility.
Shufflr’s category system could grow in bad directions. A giant list of thin labels would make the site feel like a filing cabinet. A heavily standardized label system could turn every odd page into generic content. Its present strength is that the labels are loose enough to hold personality. “Vintage” is a feeling as much as a period. “Handmade” tells you something about the maker’s relationship to the object. “Puzzles” says nothing about whether you will find logic, wordplay, games, or a peculiar personal obsession. That uncertainty is productive.
There is a minor discipline involved in using the site well. Do not arrive looking for the best page on a subject. Arrive looking for a page you would not have thought to seek. That mental shift turns an imperfect category into a source of possibility. A mismatched result becomes interesting because it reveals the limits of the label. A strange result becomes the start of a chain. The value is often one click beyond the result itself.
The best parts are the rough edges
Web Shufflr works because it does not sanitize the internet into a catalogue of finished products. The open web is not tidy. It contains amateur design, outdated software, pages that look abandoned but still answer an obscure question, and personal sites built by people who never expected an audience beyond a few friends. The roughness is not decorative; it is evidence of independent authorship.
That does not mean every old site deserves reverence. Some are simply bad. Some pages will be hard to read. Some outbound links may fail. Some categories will surface results that feel only loosely connected to the label. The home page says as much, noting that sites can change, disappear, or pass through its filters incorrectly. A good Web Shufflr visit includes the possibility of disappointment. The project earns trust by leaving that possibility visible rather than hiding it behind a promise of perfect recommendations.
This is where the service differs from a nostalgia account that posts screenshots of GeoCities pages. Screenshots turn the old web into a costume. They allow people to like its awkwardness without having to encounter its actual friction, its dead ends, or its unedited voice. Shufflr sends you into the live material. A visitor has to decide whether the page still has something to say, whether its clutter conceals care, and whether an old form of publishing still holds a surprise.
The difference between live and archived material matters. An archived snapshot is a record of what a page once was. A live page that has survived unchanged can be a record, a message, and a stubborn act of maintenance all at once. It occupies time differently. You are not only looking backward; you are encountering a site that has kept its address while the web around it changed its architecture many times.
Personal homepages are particularly good at making this point. Shufflr’s retro post observes that it has become harder to find such pages as people moved toward social platforms and as search ranking privileged commercial sites. Its categories pull from early-2000s homepages, Angelfire and Tripod pages, personal blogs, and Blogspot blogs. These are not all “content” in the contemporary sense. They are rooms made by individuals, full of lists, links, opinions, half-finished projects, images, and evidence of a life being arranged in public.
The old web has become fashionable enough that people sometimes speak about it as though its only virtue was visual mess. Blinking GIFs, beveled buttons, star fields, cramped text, and glittery backgrounds are easy symbols. Web Shufflr points toward something deeper than the visual style. The earlier web often had looser social expectations around what a website was for. A page did not need to make money, prove expertise, or turn a visitor into a subscriber. It could just document a fixation.
That freedom is often visible in structure. A hobby site may have six different navigation systems because the author added them at different times. A page may begin with a diary note, jump to a detailed tutorial, then end with a link to a guestbook. A blog may be a chronological record until the author suddenly spends a year writing only about antique radios. The lack of product discipline becomes a form of narrative. You learn about the author by the shape of their mess.
Modern web design has good reasons for consistency. Clear navigation matters. Accessibility matters. Responsive layouts matter. Security matters. None of this requires every site to feel as though it came from the same component library. The danger is not professional design; the danger is cultural flattening. When every page is engineered for the same expected behavior, the web loses the small shocks that make wandering worthwhile.
Shufflr’s interface is deliberately plain enough that these outside pages can keep their distinct voices. It would be easy to imagine a version with smart summaries, screenshots, tags, suggested follow-ups, and a polished overlay. That might make the product easier to pitch. It would also turn every destination into raw material for Shufflr’s own interface. The existing version makes a better trade: it offers a small amount of context, then hands the attention away.
The rough edge most likely to frustrate a new visitor is the absence of certainty. You may choose “music” and receive a personal site with a dated visual style. You may choose “books” and find a page whose scope is not what you expected. You may click a retro category and meet something that feels deeply specific to a person you will never know. That is precisely the point of leaving the web open. The best discoveries arrive with a bit of resistance.
There is also a larger archival lesson in the roughness. Much of the web’s real memory lives in formats nobody would call professional: a faculty page never redesigned after 1998, a neighborhood library page, a hobbyist’s web ring, a personal review archive, an old software page still hosted on a university server. If discovery systems ignore the unpolished, they erase a lot of how people actually used the medium. They preserve the headlines and lose the rooms.
The site is not a substitute for careful research, a library catalogue, a trusted archive, or a precise search engine. It does not need to be. Web Shufflr’s job is to create the first spark of interest. It gives the reader a site that may send them elsewhere: to a page’s link list, to an old mailing list archive, to a scholar’s publication list, to a forgotten fan community, to an unrelated page discovered in a sidebar. That secondary travel is where the web opens up.
The project is better for accepting that it may be slightly odd, slightly uneven, and occasionally wrong. A discovery service that copies the polish of the platforms it criticizes would lose the argument. Web Shufflr feels believable because it retains some of the web’s own imperfection. It invites you to browse the mess without pretending it has been fully tamed.
What Web Shufflr gets right about discovery
The word “discovery” has been worn down by marketing. It often means a retail page that wants to sell you a product you did not search for, a streaming service rearranging familiar options, or a social app hiding an ad between things that look like friends. Web Shufflr recovers a simpler meaning: finding something you were not already prepared to find. It does not confuse novelty with relevance, and it does not insist the result must be immediately useful.
That distinction matters because taste does not grow through confirmation alone. A person’s interests become more interesting when they brush against adjacent interests, obscure obsessions, styles they dislike, and old ideas they cannot quite place. A good discovery system should occasionally make you feel slightly underqualified. It should present a doorway rather than a conclusion. Shufflr’s categories are broad enough to make that encounter likely.
The site’s StumbleUpon comparison is obvious, and the launch post makes it itself. Yet the comparison should not be taken as a promise to recreate an old service exactly. The part of that memory that matters is not a particular button or era. It is the willingness to let a URL be an event. StumbleUpon made the next page feel like a tiny gamble. Web Shufflr brings back that feeling in a form more concerned with survival, archive material, and categories than with mass social voting.
The narrower focus gives it a sharper identity. Plenty of sites offer random Wikipedia pages, random subreddits, or random tools. Those are fun, but they tend to pick inside a single platform’s grammar. Shufflr points outward. Every good result leads away from its own brand and into someone else’s design choices. That is a rare act of product humility: success means the user spends time somewhere else.
It also restores the value of the link as an editorial gesture. A link used to carry more social weight. Blogrolls, personal bookmarks, “sites I like” pages, and web rings told readers where a person had been and what they thought deserved attention. Shufflr turns that older practice into a loose, system-level form. Its categories are not a single person’s link list, but they retain the premise that getting sent somewhere is a form of recommendation.
The links gain force because the site does not try to explain them to death. When a service gives a long rationale for every recommendation, it can make discovery feel like an exam: here is why this is relevant to your profile, here is what other people consumed, here is what you should do next. Shufflr keeps the interpretation open. A visitor has to meet the page first, then decide why it matters.
That leaves room for private reactions, which are increasingly rare online. You may land on a page and remember a computer lab, a teenage hobby, a half-forgotten book, a subject you once meant to learn, or a way of writing that feels more honest than current internet speech. The site does not ask you to perform that reaction. You can close the tab, save the link, or return the next week without turning the moment into a public signal.
The academic-homepages collection is a strong example of discovery that produces both interest and perspective. A modern professional profile is usually designed to compress a person into achievements, affiliations, and a clean portrait. An older faculty page can contain all of that, plus traces of older software, course material, informal notes, research detours, and personal enthusiasms. The page becomes a record of a mind rather than a card in a professional directory. Shufflr’s decision to surface nearly 10,000 such pages creates a different way to encounter academic life.
Discovery also requires a tolerance for time. The fastest web surfaces the newest thing because freshness is easy to measure and easy to sell. A 2003 page can look disposable through that lens. Web Shufflr treats age as a source of texture rather than a reason for exclusion. A page’s age may be exactly what makes it interesting: the old vocabulary, the old link habits, the survival of a technical explanation before today’s documentation platforms, or an author still publishing from the same address.
The site’s category list quietly argues against the idea that the web can be reduced to a few dominant hobbies and platforms. Music sits near military history. Cooking sits near robotics. Poetry sits near football. “Horror,” “puzzles,” “jewelry,” “theology,” and “vintage” all occupy their own places. The list feels human because human curiosity is not organized like a corporate content strategy. It is cluttered, seasonal, emotional, and often wonderfully specific.
This is also why the service suits people who already spend a lot of time online. It is not an introduction to the web for beginners. It is a reset for people who know the usual routes too well. The more familiar you are with the polished surfaces of the internet, the more relief there is in being sent somewhere that never learned to perform for them. Web Shufflr reminds an experienced browser that there are still doors not preloaded in their habits.
A person who wants exact facts should keep using search. A person who wants the best-reviewed product should use reviews and specialist guides. A person who wants to lose half an hour to the feeling that the web is still too large to map should open Shufflr. It is a tool for curiosity, not certainty. That distinction gives the site more integrity than products that try to become every kind of discovery at once.
A small site with a large argument
Web Shufflr makes an argument without stating it in grand language. The argument is that the web becomes poorer when discovery is controlled by a small set of platforms whose incentives reward sameness, speed, monetization, and emotional capture. The site answers that argument with an unusually concrete act: one external link at a time. It does not need a grand theory of the internet because its interface embodies a different habit.
The project’s strongest move is to regard obscure, old, personal, and imperfect sites as worth more than their traffic figures suggest. Page views do not tell you whether a page has a memorable voice. Search rank does not tell you whether a hobby archive contains the only clear explanation of a minor subject. A polished domain does not tell you whether a person made it because they cared. Web Shufflr puts those missing measures back into circulation.
That does not make the site a neutral archive. Choosing categories is a form of taste. Preserving particular kinds of pages is a form of taste. A person may disagree with what counts as interesting, what belongs under a label, or whether certain pages deserve to be sent to strangers. The project is better understood as a point of view than a definitive map. Its point of view is generous toward independent publishing and suspicious of the systems that have made independent publishing harder to find.
The site is still young by its own description. Its launch post calls it “in its infancy,” says categories and websites will continue to be added, and says the categorization system will keep being refined. The January 2026 academic-homepages addition shows that this is not an abandoned concept: the archive is still being extended in specific directions. That early-stage quality is part of the appeal, but it is also the thing to watch. A project like this earns its place through steady maintenance, not a flashy launch.
The risks are plain. Collection scale can dilute taste. Automation can sort pages into labels that feel ridiculous. Old URLs can be claimed by new owners. A site that celebrates the old web can become trapped in a single nostalgic mood. The remedy is not more gloss. It is active curation, working feedback controls, clear reporting routes, and a willingness to remove pages that no longer fit. The home page’s acknowledgement of bad matches is a good beginning.
There is also a practical reason to wish the project well. Independent web publishing needs discovery systems that do not demand that every creator become a performer, a growth strategist, a short-form video editor, or a brand. A person should be able to make one careful page and still have a chance of being found. Shufflr cannot solve the economic problems of the web, but it offers a small counterexample to the idea that visibility must be purchased or algorithmically earned.
The best way to use the site is almost deliberately unproductive. Visit without a task. Choose a topic that feels a little off your normal path. Give the result enough time to reveal what it is. Follow one or two side links. Treat the site’s back button as a reset, not a failure. The point is to practice being a browser rather than a consumer. It is a modest habit, but it alters how the web feels.
There is pleasure in finding a useful page, of course. You might discover a reference collection, a small blog, a research page, a fan archive, an old tutorial, or a site that makes you laugh. The more lasting pleasure comes from remembering that such things still exist outside the few interfaces that dominate daily attention. Web Shufflr makes the internet feel less finished. It reintroduces a little uncertainty, and uncertainty is where exploration begins.
A culture that only values the newest, cleanest, most measurable pages will lose much of its texture. The old web was not better in every respect, but it preserved a simple truth that still matters: people make strange little places when they are given an address and left alone. Web Shufflr goes looking for those places. It gives them a route back to readers who might never have typed the right words into a search box.
That is why the site is worth opening now, even in an unfinished state. It is not asking you to join a new platform. It is not trying to become your home page or replace your search engine. It asks for a few minutes and offers an encounter. Sometimes the encounter will be forgettable. Sometimes it will make you click three layers deeper into a web you thought had disappeared. That is enough. The browser tab still knows how to lead somewhere strange.
The habit worth keeping
A good discovery system also has to resist the urge to turn itself into the place where every discovery is consumed. That is how platforms swallow the material they recommend. They show a headline, a clip, a comment, a reaction, a summary, and a related post until opening the source feels optional. Web Shufflr reverses that hierarchy. Its own page is a threshold. The external site is the room. The relationship is closer to a good librarian sliding a book across a desk than to a media company building a walled garden.
There is an older etiquette of browsing embedded in this design. You arrive somewhere because a person, a directory, a webring, a blogroll, or a friend sent you there. You accept that the page may be peculiar. You look around before deciding whether to leave. That etiquette is slower because it assumes the destination deserves a fair hearing. Shufflr does not force the visitor into that behavior, but its lack of previews and pre-chewed context gives the page a chance to speak in its own rhythm.
The system also lets a person choose a topic without making them declare an identity. A music feed usually infers taste and keeps proving that inference back to you. A “music” link on Shufflr does not say anything about who you are. It is an interest with no permanent profile attached. You can be curious about medieval history for ten minutes, then click on candy wrappers, then go back to programming. That freedom sounds trivial until you notice how much online life now turns every click into a record of the self.
Archive projects often become invisible precisely when they work well. The public sees a search box, perhaps a snapshot, and not the labor behind keeping URLs legible, verifying survival, handling redirects, or deciding which versions count. Web Shufflr makes some of that labor felt through its unevenness. A live page appears, or it does not. The category is right, or it is a little off. The visitor becomes aware that the web needs people and systems willing to revisit its old addresses.
The project’s use of older crawl material also points to a neglected fact about digital memory: the web does not preserve itself by default. Hosting ends. Personal domains expire. Universities restructure their directories. Platforms shut down. File formats age. A surviving URL is not the same thing as a saved page, but it is a precious form of continuity. It retains context that screenshots and isolated documents often lose: the surrounding navigation, the outbound links, the author’s chosen location, and the feeling of an active address.
A category index gives fragile pages a second life without pretending they are timeless. That balance matters. The goal is not to claim that a 1998 personal page is as current as a newly maintained reference source. The goal is to preserve its chance of being encountered for what it is. An old page can be wrong, moving, funny, or unexpectedly useful. Time does not erase its capacity to interest a reader; it changes the terms of the meeting.
The category list also works as a portrait of what the collection believes browsing is for. It includes conventional fields of knowledge, but it does not stop there. “Food” sits beside “philosophy.” “Pets” sits beside “theology.” “Comics” and “conspiracy” appear in the same long index without anyone trying to rationalize the order. That is the right kind of untidiness for a discovery site. It accepts that people do not separate their curiosities into professional departments.
A tightly controlled set of categories would make Web Shufflr easier to explain and perhaps easier to maintain. It would also make the site less pleasurable. Part of the charm comes from finding an entry that feels almost too specific to have its own door. “Jewelry” acknowledges that some readers will want to follow a thread of material culture. “Webgames” gives browser play a place of its own. “Handmade” gives craft and personal making a route that is not swallowed by shopping.
The home page’s changing topic selection contributes to this feeling. A fixed menu tells you what a product thinks is important. A rotating set of links allows secondary interests to surface without becoming a buried filter. The page keeps rearranging its own invitation. It quietly rewards returning visitors who might otherwise assume they already know the catalogue.
A visitor should still remember that a category title is not a quality label. “Academic homepages” may produce a page whose research is years out of date. “Personal blogs” may produce a blog that has been dormant since 2011. “Vintage” may lead to a site that has only a loose relationship with the word. Shufflr is about access to objects, not certification of their claims. The right response is curiosity followed by judgment, the same basic discipline the open web has always required.
That demand for judgment is a feature, not a burden. Recommendation products often remove so much friction that a visitor never practices deciding whether a source is credible, useful, or worth their time. Web Shufflr gives the reader that small responsibility back. It says, in effect, here is a page; now use your eyes. The result feels more adult than systems that quietly decide what deserves attention and hide the selection rules behind a black box.
The lack of an elaborate ranking layer is another good rough edge. Pages are not presented as “the best,” “trending,” “editor’s pick,” or “popular with people like you.” That absence keeps obscure material from having to compete on popularity terms. A strange fan page can arrive with the same visual weight as a polished educational resource. The user supplies the judgment that a feed usually pretends to have made already.
There is a difference between awkwardness and neglect, and Web Shufflr will sometimes leave the visitor to work it out. A rough site may be full of care. A polished site may be empty. A page with a dated layout may contain the most direct account of a niche subject available online. The point is not to romanticize bad design; it is to avoid confusing surface polish with worth. The web’s best surprises often have poor packaging.
That is why the project feels closer to browsing a used-book shop than shopping a well-lit chain store. The shelves are imperfectly organized. Some books are out of place. You may pull down a volume that goes nowhere. You may also find something written by a person with exactly the obsession you did not know you needed. The disorder creates the conditions for a real find. A perfectly managed catalogue gives you fewer reasons to look twice.
Web Shufflr also respects the fact that curiosity has rhythms. Some days a random link is enough. Some days a single page sends you into an hour of reading. A feed assumes that every minute should look like the last minute. This site leaves time unstructured. You are free to browse once, browse deeply, or abandon the experiment without being punished by a bad recommendation model or a nagging re-engagement prompt.
There is a quieter benefit too: the service reduces the feeling that every interest must become a project. You can click “mythology” without enrolling in a course. You can explore “painting” without deciding to buy supplies or build a portfolio. The web used to be better at low-stakes fascination. Shufflr brings a little of that back by letting each category be a temporary permission slip rather than a funnel toward action.
One measure of a discovery product is whether it makes the person behind it more visible than the product itself. Web Shufflr passes that test when it works. A good result leaves you remembering the author of the page, their unusual site name, their collection, their particular problem, or the sentence that made you keep reading. Shufflr’s success is self-erasing. The platform recedes, which is exactly what a discovery layer should do.
That creates a strange but healthy economic gesture. The dominant web asks creators to make content for a platform, then gives the platform the main relationship with the audience. Shufflr points readers to sites that retain their own domains, their own navigation, their own publishing rhythm, and their own sense of what a visitor should see. The click goes to the maker’s space. That is a small redistribution of attention, but attention is the currency that makes independent publishing feel possible.
The project will be judged less by how many topics it can add than by whether its link quality remains alive. There is always pressure to turn a promising index into a volume game: more URLs, more labels, more pages, more claims of scale. The more interesting path is careful density. A collection earns loyalty when the average click has a chance of being surprising, even if the directory never becomes exhaustive.
In that sense, maintenance is the real editorial voice. Keeping broken links out, accepting reports, checking category drift, and continuing to add collections with a reason for existing will matter more than a redesigned interface. A discovery site is a living editorial object even when its selection mechanism is automated. It needs somebody to care that a link still sends a reader somewhere worth arriving.
The January 2026 academic-homepages collection offers a good model for future growth because it is not merely a larger pile of URLs. It has a distinct reason to exist, a clear source history, and a recognizable browsing payoff. The best new categories will feel like that: a newly opened room, not another filing label. A project built on serendipity needs each expansion to create a fresh kind of accident.
A satisfying future for Web Shufflr would be quiet. It does not need celebrity endorsement, a tidal wave of shares, or a giant personalized app. It needs visitors who return when the web begins to feel too familiar and editors who continue to believe that obscure pages are worth keeping in circulation. The site’s scale should serve its invitation, not replace it. One good link remains the unit of value.
That may sound almost stubbornly small, but small is the point. The most durable web experiences are often not those that try to absorb every need. They are the ones that do one thing clearly and refuse to clutter it. Web Shufflr offers a better kind of idleness. It turns aimless browsing from a guilty habit into an alert way of seeing what other people have left online.
A person can visit because they miss the old web, but nostalgia is not required. The site is worth using because the current web still needs places that favor outgoing links over retention, independent pages over feeds, and surprise over prediction. Its real subject is not the past; it is the possibility of an internet that remains larger than its loudest platforms. Web Shufflr does not solve that problem. It gives the browser a living reminder that the problem is not finished.
There is a personal habit hidden inside the site’s mechanics. The visitor has to arrive with enough openness to be bored for a minute, puzzled by an unfamiliar page, or tempted to follow a link that has no obvious payoff. That is a form of attention modern interfaces rarely train. They train recognition, reaction, and fast abandonment. Web Shufflr rewards the older skill of staying with an object long enough to see why somebody made it.
The site’s strongest users may become informal collectors of routes rather than content. A link from a hobby page to an old forum can lead to a technical archive; a faculty homepage can point to a lab’s forgotten teaching materials; a personal blog can still have a blogroll that opens ten further doors. The first random result is often only the match that lights the fuse. This is how the web used to grow in a browser: not as a feed of isolated units, but as a set of paths made by people who kept sending each other somewhere else.
That structure has a quiet ethical appeal. It asks the visitor to give attention directly to the person or institution that published the page, on their own terms. It asks the collection to be honest about its errors. It asks the reader to exercise judgment instead of outsourcing it entirely. None of these are spectacular acts, but together they make browsing feel more reciprocal. You do not merely consume a recommendation; you enter a small chain of editorial decisions and personal efforts.
Web Shufflr is easy to underestimate because the first screen is so small. The category list, the random destination, and the feedback buttons look like a modest web toy. Yet the site carries a serious conviction: the internet is still full of pages that deserve to be met without an algorithmic biography arriving first. Open it when the usual routes feel exhausted. Choose a door. Let a stranger’s website interrupt the script.
Author:
Jan Bielik
CEO & Founder of Webiano Digital & Marketing Agency

This article is an original analysis supported by the sources cited below
Web Shufflr
The home page used to confirm the project’s stated purpose, rotating topic selection, feedback controls, and current academic-homepage announcement.
Welcome to the web shufflr website
The launch post used for the archive’s stated workflow, older crawl sources, the more-than-500,000-site figure, and the site’s StumbleUpon comparison.
A list of all categories for web shufflr
The published category index used to assess the breadth and character of Web Shufflr’s topic system.
Retro categories for finding personal homepages
The project’s explanation of its early-2000s homepages, Angelfire and Tripod, personal-blog, and Blogspot collections.
New category academic homepages
The announcement used for the nearly 10,000 academic-homepage collection, its 2012 crawl source, and its mix of old and maintained university pages.
| Citing this article? Brief excerpts are welcome. Please credit Webiano.digital, name the author where stated, and include a link to https://webiano.digital and to this original article. Full or substantial republication requires prior written permission. Read our Copyright and Content Use Policy. |