

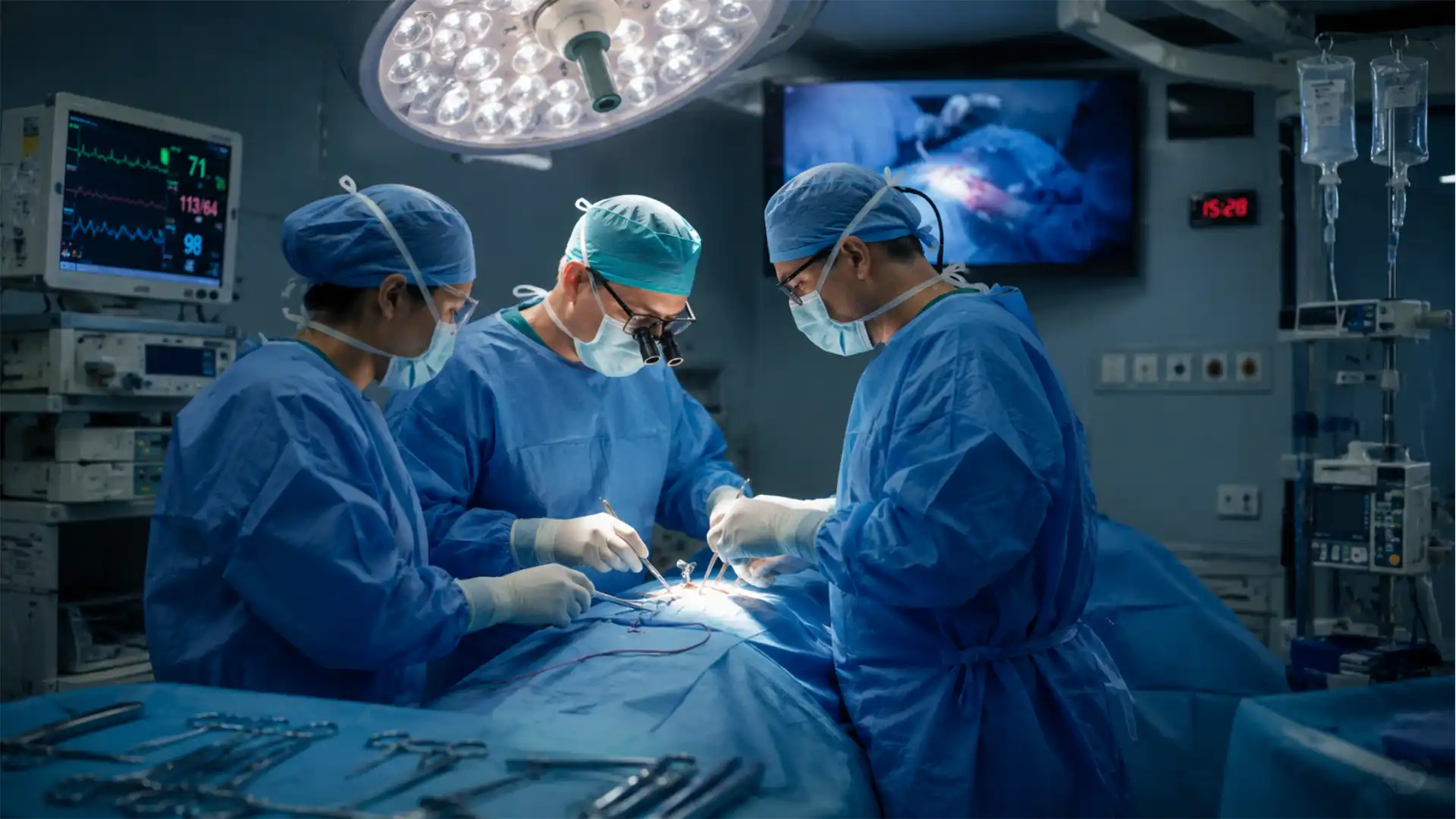
A surgical robot at Johns Hopkins University worked through a delicate part of a gallbladder operation eight times, on eight different specimens, and finished every one without a surgeon driving its instruments. No one held the console. No one steered the arms through the cuts. The robot looked at the tissue in front of it, decided what to do, did it, caught its own mistakes when they happened, and kept going. Across those eight runs it completed the task it was given every single time.
Table of Contents
A robot completed a surgical phase on its own and the result held up
That is the claim that drew a wave of coverage in the summer of 2025, and it is worth stating precisely because the precise version is more interesting than the headline version. The work, published in Science Robotics in July 2025 under the title SRT-H: A hierarchical framework for autonomous surgery via language-conditioned imitation learning, did not show a machine performing a complete cholecystectomy from first incision to closing stitch. It showed something narrower and, for engineers, more revealing: a system handling the clipping-and-cutting phase of a gallbladder removal, the step where a surgeon seals and divides the tube and the artery feeding the organ, on ex vivo pig tissue, with the kind of moment-to-moment judgment that earlier autonomous systems could not manage.
The distinction between a full operation and a single phase is not a quibble. The clipping-and-cutting phase is the part of a cholecystectomy where mistakes turn into lifelong complications, and it is the part that demands the surgeon read anatomy that is never quite the same from one patient to the next. The robot, called the Hierarchical Surgical Robot Transformer, or SRT-H, was built by a team led by senior author Axel Krieger, a medical roboticist at Johns Hopkins, with lead author Ji Woong “Brian” Kim, who has since moved to Stanford. Their stated framing was deliberate. They called what they achieved step-level autonomy, not autonomous surgery in the sweeping sense, and they were explicit that the road to a living human patient runs through challenges this experiment did not face.
What makes the result hard to dismiss is the combination of three things that rarely show up together. The robot generalized to gallbladders it had never seen, rather than repeating a memorized motion on a fixed setup. It corrected itself in real time when a grasp slipped or a clip sat wrong, instead of freezing or plowing ahead. And it did both while responding to spoken instructions from the team, the way a junior surgeon takes guidance from a senior one. Krieger described the shift bluntly, saying the work moves the field “from robots that can execute specific surgical tasks to robots that truly understand surgical procedures.” Kim was equally direct that the point was reliability: the team argued that surgical autonomy, long treated as a distant idea, is now “demonstrably viable” in a constrained setting.
This article works through what actually happened, how the system is built, and why the engineering choices matter. It also takes seriously the parts the demonstration did not prove. A 100 percent success rate on eight pig gallbladders is a real engineering milestone and a weak clinical claim at the same time, and holding both of those thoughts at once is the only honest way to read it. The sections that follow cover the mechanism, the data, the autonomy framework the field uses to grade systems like this one, the commercial setting it lands in, the regulatory questions it raises, and the realistic distance between a clean run on cadaveric tissue and a robot anyone would let near a living person.
The exact thing the robot did, clip by clip
A cholecystectomy removes the gallbladder, usually because of gallstones, and in modern practice it is done laparoscopically through a few small ports rather than a large open incision. The operation has several phases: exposing the area, identifying the structures, sealing and cutting the cystic duct and cystic artery, separating the gallbladder from the liver bed, and removing it. SRT-H was tested on the clipping-and-cutting phase, which is the middle and most exacting part of that sequence.
In that phase, the surgeon has to find the cystic duct, the tube that drains bile from the gallbladder, and the cystic artery, the vessel that supplies it. Both have to be sealed before they are divided, or the patient bleeds and bile leaks into the abdomen. Surgeons seal them with small metal clips applied by a dedicated instrument, then cut between the clips with scissors. The robot did exactly this. It applied six clips in total, three on the duct and three on the artery, positioned them with enough spacing to leave room for a clean division, and then made two cuts between the clipped segments while keeping its instruments clear of the surrounding tissue.
The procedure is not one motion. The paper and the team describe it as a string of 17 distinct surgical tasks carried out in sequence, each lasting from seconds to a minute or more, with the whole phase running several minutes. Identifying a structure, reaching for it, grasping it, applying a clip, repositioning, applying the next clip, swapping the clip applier for scissors, cutting, checking the result: each of these is a separate task the system had to plan and execute, and a failure at any one could compromise the whole. Getting through all 17 in order, on tissue the model had never encountered, is the achievement the success rate refers to.
One detail that often gets lost in the coverage is the tool change. The clip applier and the scissors are different instruments, and on the robot used here they cannot both be mounted at once for this workflow. When the robot needed to switch from clipping to cutting, it did not silently expect a human to notice. It requested the tool change itself, paused, and resumed the procedure after a person physically swapped the instrument. That is the bulk of what people mean when they describe the human assistance as minimal. The human did not make surgical decisions. The human handed the robot a different tool when the robot asked for one, the way a scrub nurse passes an instrument across the table.
The robot also took spoken guidance. The system was built to respond to plain-language commands and corrections, things on the order of “grab the gallbladder head” or “move the left arm a bit to the left.” During the trials, members of the team could issue instructions and corrections by voice, and the robot would act on them and, in the high-level part of the system, learn from them. This is closer to how a teaching hospital actually runs than to the image of a sealed black box operating untouched. A resident under a senior surgeon is autonomous in the sense that their hands do the work and their judgment drives most of it, but a word of correction at the right moment is part of the process, not a failure of it.
Two facts bound the claim honestly. First, the tissue was porcine and ex vivo: pig gallbladders, outside a living body, with no heartbeat, no breathing, no active bleeding, and no inflamed or scarred anatomy of the kind a real diseased gallbladder often presents. Second, the robot was slower than a human surgeon. It completed the phase, and the quality of the result was described as comparable to expert work, but it took longer to get there. Neither fact erases the milestone. Both are exactly the sort of thing that separates a controlled demonstration from a clinical procedure, and the team said so plainly.
The people and labs behind SRT-H
The work came out of the Laboratory for Computational Sensing and Robotics at Johns Hopkins University in Baltimore, with the senior author Axel Krieger, an associate professor of mechanical engineering who has spent more than a decade building robots that operate on soft tissue. Krieger is the connective thread across a body of work that runs from the early Smart Tissue Autonomous Robot through to SRT-H, and his lab sits at the point where mechanical engineering, computer vision, machine learning, and surgery overlap. The Johns Hopkins Malone Center for Engineering in Healthcare and the university’s Department of Surgery were both part of the effort, which matters because surgical projects that stay inside an engineering department tend to miss what surgeons actually need.
The lead author, Ji Woong “Brian” Kim, was a postdoctoral researcher at Johns Hopkins during the project and has since joined the Department of Computer Science at Stanford University. His framing of the result has been consistent and measured. He described the central barrier the work tackled as reliability, arguing that the field had treated dependable surgical autonomy as far off, and that the experiment showed it can be reached in a defined task. He also explained the underlying method in plain terms, comparing the model to the way a language model predicts the next word from what came before, except that this model predicts the next robot motion from what its cameras see.
The author list runs to 14 people across institutions, and the cross-pollination is part of the story. Alongside the Johns Hopkins team, the project included researchers from Stanford, among them Chelsea Finn, a well-known figure in robot learning whose group has pushed the imitation-learning methods that SRT-H builds on, and Lucy Xiaoyang Shi. Other contributors included Juo-Tung Chen, Pascal Hansen, Antony Goldenberg, Samuel Schmidgall, Paul Maria Scheikl, and Anton Deguet on the engineering and systems side, with Jeffrey Jopling from the Department of Surgery bringing the clinical perspective and Richard Jaepyeong Cha, affiliated with the Sheikh Zayed Institute for Pediatric Surgical Innovation at Children’s National Hospital, linking the work to a pediatric surgical research program. The collaboration with Children’s National is not new; Krieger’s earlier autonomous-surgery work ran through the same partnership.
The funding came from U.S. government sources, which places the project in the public research base rather than inside a company’s product pipeline. That distinction shapes how the result should be read. A university lab publishing a peer-reviewed paper with full methods and an accompanying open dataset is doing something different from a manufacturer announcing a product. The incentives point toward demonstrating a method and inviting scrutiny, not toward selling a system. It also means the path from this result to anything a hospital could buy runs through commercialization steps that have not happened, and through a regulatory process that this kind of academic demonstration does not, by itself, begin.
The institutional mix matters for a second reason. Surgical autonomy is not a problem any single discipline can close. The vision and learning come from computer science, the manipulation and control from robotics and mechanical engineering, the framing of what counts as a safe and correct surgical action from practicing surgeons, and the data collection from people willing to perform the same procedure on cadaveric tissue hundreds of times under recording. SRT-H is in part a demonstration that a group able to span all of those roles can produce a result none of them would reach alone, and the lineage that produced it is the subject of the next section.
From marked tissue to messy anatomy, the road that led here
SRT-H did not appear from nothing. It is the latest point on a research line that Krieger’s lab has been advancing for roughly a decade, and the earlier steps explain both how far the field has come and why this particular result counts as a jump rather than an increment.
The lineage starts with the Smart Tissue Autonomous Robot, STAR. The concept was published as early as 2014 as a vision-guided system for laparoscopic suturing, and in 2016 the team reported success performing an intestinal anastomosis, the stitching together of two cut ends of intestine, on a stabilized tissue sample. Anastomosis is one of the hardest things to do well in abdominal surgery because a single misplaced stitch can cause a leak with severe consequences, so it was a deliberate choice of a demanding target.
The headline moment for STAR came in January 2022, when the team reported in Science Robotics that the robot had performed laparoscopic intestinal anastomosis on a live pig, the first autonomous robotic soft-tissue surgery on a living animal. Krieger’s summary at the time was striking: STAR performed the procedure in four animals and produced results better than human surgeons doing the same task. That was a real milestone, and it still stands as a marker of how precise a machine can be on a repetitive suturing task.
But STAR worked under conditions that SRT-H specifically moves beyond, and the contrast is the whole point. STAR relied on specially marked tissue, using biocompatible near-infrared fluorescent markers placed on the intestine so the robot’s cameras could track the surface and plan its stitches. It operated in a tightly controlled setup, with one robot arm carrying a motorized suturing tool and another carrying the imaging system, and it followed a rigid, predetermined surgical plan. Krieger’s own analogy captures the limit. He has described STAR as like teaching a robot to drive along a carefully mapped route, while the new system, in his words, “is like teaching a robot to navigate any road, in any condition, responding intelligently to whatever it encounters.”
Between STAR and SRT-H came an intermediate step that explains the architecture. In 2024 the lab introduced the Surgical Robot Transformer, SRT, and used it to train a robot on three foundational surgical tasks: manipulating a needle, lifting body tissue, and suturing. Each of those tasks lasted only a few seconds. SRT showed that the transformer-based imitation-learning approach, mapping camera images to robot motions the way a language model maps text to text, could work on real surgical motions on the standard research platform. What it had not yet shown was the ability to chain many such tasks into a long, coherent procedure and recover when one of them went wrong.
That gap, between short isolated tasks and a minutes-long string of dependent steps on variable anatomy, is exactly the gap SRT-H closes. The “H” stands for hierarchical, and the hierarchy is the mechanism that lets the system plan at the level of a whole step while executing at the level of a single motion, and correct itself when the two come apart. Seen against this history, the result is not “a robot did surgery.” It is “a robot stopped needing the markers, the fixed plan, and the controlled setup, and started handling tissue it had never seen while fixing its own errors.” That is the shift the field had been working toward, and it is why the 2025 result drew the attention it did even though it stopped at a single phase on cadaveric tissue.
The other thing the lineage shows is realism about pace. STAR’s live-animal result was 2022; SRT-H’s ex vivo result was 2025. The gap between a controlled live-animal suturing task and an adaptive ex vivo clipping-and-cutting task was three years of work, and the gap from here to a living human patient is, by the team’s own account, larger still.
The architecture that lets a robot talk itself through an operation
The core idea behind SRT-H is a split brain. Instead of one model trying to do everything at once, the system uses two policies stacked in a hierarchy, and the division of labor between them is what makes long, variable procedures tractable.
At the top sits the high-level policy, which acts as a planner. It looks at the current view of the surgical field and decides what should happen next, then expresses that decision as an instruction in plain language. The instruction is not abstract math; it is text on the order of “apply the first clip” or “cut the cystic duct,” and when something has gone wrong it can be a correction such as “move the left arm a bit to the left.” Underneath sits the low-level policy, which takes that language instruction together with the live camera images and produces the actual robot motion, the trajectory in space that moves the instrument where it needs to go. The high-level policy thinks in steps. The low-level policy turns each step into movement.
Both halves are built as transformer decoders, the same family of neural network that underpins large language models, which is why the team and the press repeatedly compare SRT-H to the technology behind systems like ChatGPT. The comparison is accurate at the level of architecture rather than function. A language model predicts the next token of text from the tokens before it. SRT-H’s low-level policy predicts the next increment of robot motion from images and a language instruction, and its high-level policy predicts the next language instruction from what the cameras have shown over recent moments. The mathematics of attention and sequence prediction is shared. The output is motion and surgical instructions rather than prose.
The high-level policy’s visual front end is worth naming because it is a deliberate engineering choice. It uses a Swin transformer to encode the camera images into tokens, the compact numerical representations the model can reason over, and a transformer decoder then turns those tokens into the next instruction. The low-level policy consumes the instruction and the images and emits motions in Cartesian space, meaning ordinary three-dimensional coordinates for where the instrument tip should go, rather than directly commanding each joint angle. Working in Cartesian space keeps the motion model closer to the geometry of the task and away from the idiosyncrasies of the specific robot’s mechanics.
Two design details do a lot of the work in making the system reliable rather than merely functional. The first is temporal context: the high-level policy does not look only at the single current frame but at a window of recent frames. Surgery is full of moments that look almost identical in a still image but mean different things depending on what just happened. A clip site before the clip and the same site after the clip can be visually similar; the duct before grasping and after grasping can be hard to tell apart from one frame. Feeding the model a short history of what it has just seen lets it distinguish steps that are visually close but temporally distant, which is the difference between knowing you are about to place the second clip and thinking you still need to place the first.
The second detail is the use of wrist-mounted cameras in addition to the main endoscope. The endoscope gives the wide view a human surgeon sees on the monitor. The cameras near the instrument tips give a close, almost hands-on perspective of the interaction between tool and tissue, the kind of view that tells you whether a grasp actually has the structure or has slipped off it. The paper pairs this multi-view perception with a specialized loss function for training the high-level policy, a technical adjustment to how the model is penalized during learning so that it pays attention to the right visual cues. Together these choices improve the system’s visual reliability, its ability to keep track of what is happening even as tissue moves and instruments occlude the view.
The reason a hierarchy beats a single end-to-end model here is recovery. A flat model trained to map images straight to motions can perform a memorized task well, but when it drifts into a state it did not see much during training, it has no higher-level sense of the plan to fall back on, and the small errors compound until the whole attempt fails. By separating the planner from the executor, SRT-H lets the high-level policy watch the low-level policy’s work and issue a corrective instruction when the execution goes off course. The planner does not need to know how to move the arm; it needs to recognize that the arm is in the wrong place and say so. That separation is the structural reason the system can climb back out of the suboptimal situations that are unavoidable in real tissue, and it is the part of the design with the most direct line to clinical relevance.
Plain instructions instead of raw motion, and why that matters
The choice to route the system’s planning through natural language rather than through internal numerical codes looks at first like a presentation gimmick, the sort of thing that makes a demo readable. It is more than that, and the reasons it matters are worth pulling apart because they bear on safety, training, and the eventual question of whether anyone can trust such a system.
Start with what language buys the model internally. By forcing the high-level policy to commit to an instruction expressed in words, the design creates a clean interface between planning and execution. The planner’s entire output is a short, discrete instruction. The executor’s entire input includes that instruction. There is no tangle of continuous signals passing between them that no one can inspect. The instruction set is small and human-readable, which means the boundary between “deciding what to do” and “doing it” is a place a person can actually look. In a system meant eventually to operate on people, having a legible seam in the middle of the model is not a small thing.
Language also makes correction natural. Because the planner already speaks in instructions, a correction is just another instruction of the same kind. “Move the left arm a bit to the left” is structurally identical to “apply the first clip”; both are language commands the low-level policy knows how to act on. This is why the same channel handles the robot’s own self-generated corrections and a human’s spoken corrections. The system does not need a separate mechanism for outside guidance. A person can drop an instruction into the same slot the planner uses, and the executor treats it the same way. That is what allowed the trials to run with voice guidance that felt like a senior surgeon coaching a resident rather than an operator overriding a machine.
There is a learning advantage as well. When corrections are language, they can be recorded and learned from as a normal part of the data. A moment where a human said “move left” and the procedure then went well is a labeled example of what to do in that situation, and it can feed back into training so the planner gets better at issuing that correction on its own next time. The team built data collection around exactly this idea, capturing not only clean executions but also recovery sequences, so the model learns the act of getting back on track rather than only the act of doing it right the first time. Most of the world’s surgical demonstration data, if it existed at scale, would be clean runs; the deliberate capture of corrections is part of why this system recovers.
The approach connects to a broader current in robotics, where language-conditioned policies have become a way to give general-purpose robots flexible, instructable behavior. The surgical setting pushes the idea into a domain where the stakes are far higher and the tolerance for error far lower than in the warehouse and kitchen tasks where these methods first matured. A robot that fumbles a language instruction while folding laundry wastes a few seconds. A robot that misreads “cut the cystic duct” has done something irreversible to a patient. The high-level planner’s job of issuing the right instruction at the right time, and recognizing when it must instead issue a correction, is therefore not a convenience layer. It is the part of the system carrying the most safety-relevant responsibility, and it is the part the hierarchy is designed to make both reliable and inspectable.
The training data and how it was gathered
A learning system is only as good as what it learns from, and the data behind SRT-H explains both its capabilities and its limits more honestly than any single performance number. The model was trained on roughly 16,000 to 18,000 demonstrations collected across more than 30 pig gallbladders, amounting to on the order of 20 hours of recorded surgical activity. This is the place where the popular description that the robot learned from “human surgery videos” goes slightly wrong, and the correct version is more informative.
The demonstrations were produced by people operating the robot through teleoperation, not by filming live human operations. On the research platform, an operator sits at a console and controls the instruments like a precise joystick while watching through the endoscope, exactly as a surgeon does during a standard robot-assisted procedure. The system records the camera images alongside the motion data, the joint angles and trajectories the operator’s commands produced. Training the model then becomes a matter of teaching it to map the images to the motions, so that the model reproduces what the operator did when it sees a similar scene. Kim has described the workflow plainly: the team trained people to perform the chosen operation on pig cadavers, learning the procedure from a surgical resident, and then recorded them doing it many times over.
This is imitation learning, and its strengths and weaknesses both follow from the fact that the model copies demonstrations. Its strength is that it can acquire genuinely dexterous, situation-dependent behavior without anyone writing explicit rules for every contingency, which is what defeated earlier logic-based approaches on soft tissue. Its weakness is that it only knows what the demonstrations contained. If a situation never showed up in the 20 hours of data, the model has no grounded experience of it, and the kinds of situations a diseased human gallbladder presents, inflammation, scarring, dense adhesions, distorted anatomy, were largely not in that data because pig cadaver tissue does not present them.
The team did something specific to push past the most obvious failure of pure imitation. They collected not only optimal demonstrations, the clean runs where everything went right, but also recovery demonstrations, sequences showing how to get back on track after something went wrong. They also used a method known as DAgger, short for dataset aggregation, in which the system is run, the situations where it struggles are identified, and human corrections in those situations are folded back into the training data. The language corrections that the high-level policy issues were either given live during data collection or added afterward during processing. The result is a model that has seen not just success but failure-and-rescue, which is precisely what lets it self-correct rather than collapse when a grasp slips.
The data also reflects the multi-camera, multi-modal design. Each demonstration pairs the endoscopic video with the close-up wrist-camera views and with the kinematic record of how the instruments moved. That richness is part of why the model can keep its bearings during occlusion and tissue motion: it learned from views that showed the tool-tissue interaction directly, and from the geometry of the motions, not from a single distant camera angle.
To support work beyond their own lab, the broader effort produced a public dataset, released under the name ImitateCholec, drawn from a larger set of ex vivo porcine cholecystectomies and segmented into the same 17 surgical tasks, integrating the multi-view endoscopic video with the instrument kinematics and capturing both ideal executions and recovery maneuvers. Releasing the data matters for the field’s pace, because the central bottleneck in surgical autonomy is not clever architectures but the scarcity of high-quality demonstration data, and a shared dataset lets other groups train and compare methods on the same foundation. It is also a reminder that the capabilities shown here are downstream of an enormous, painstaking data-collection effort, the kind that does not scale by itself and that becomes far harder when the target moves from cadaveric pig tissue to the variable reality of living patients.
Self-correction is the part worth paying attention to
Of everything SRT-H demonstrated, the capability with the clearest line to clinical value is not the clipping or the cutting. It is the error recovery. Earlier autonomous systems, including the team’s own STAR, tended to perform well exactly as long as conditions matched what they were built for, and to fail badly when they did not. They could follow a mapped route; they could not handle the road changing under them. The behavior that separates SRT-H from that pattern is its ability to recognize that something has gone off course and fix it without a human taking over.
Real surgery, even the contained phase tested here, produces a steady stream of small deviations. A grasp closes on the wrong spot. The tissue shifts as it is manipulated. A clip lands at a slightly off angle. An instrument briefly blocks the view of the structure being worked on. A human surgeon handles these constantly and mostly without conscious effort, adjusting grip, repositioning, trying again. The hard part for a machine is not executing the ideal motion; it is the recovery when the world refuses to cooperate, because recovery requires noticing the problem, understanding the current state, and choosing a corrective action rather than continuing as if nothing happened.
The hierarchy is what makes this possible. The high-level policy watches the result of the low-level policy’s actions and, when the execution drifts into a poor state, issues a corrective instruction that nudges the system back toward a good one. The planner does not need to compute the corrective motion itself. It only needs to recognize the situation and name the fix in language, and the executor turns that into movement. Because the model was trained on recovery sequences and on human corrections through DAgger, the planner has learned what good corrective instructions look like in the situations that actually arise, so it can issue them on its own. The team’s framing is that the hierarchical approach improved the policy’s ability to recover from the suboptimal states that are unavoidable in a dynamic surgical environment, and the ablation studies in the paper were designed to show that the design choices behind this, the hierarchy, the temporal context, the multi-view perception, each contributed to the result rather than being decorative.
The practical reading is that autonomy without recovery is fragile to the point of uselessness in surgery. A system that performs flawlessly on tissue exactly like its training data and fails the first time anatomy differs is not a surgical system; it is a demonstration. What clinical deployment would require is a system that holds up when the situation is not ideal, because in a living patient the situation is never ideal. SRT-H does not prove that such robustness exists at the level surgery on humans would demand, since its recoveries were demonstrated on cadaveric pig tissue under controlled conditions. What it proves is that the recovery behavior can be learned and built into the system’s structure rather than scripted, which is a different and more promising thing than a longer list of pre-programmed contingencies. The open question, taken up later in this analysis, is how far that learned recovery generalizes when the variation it must handle grows from the modest differences between pig gallbladders to the wide, sometimes pathological range a human surgical population presents.
The hardware sitting underneath the intelligence
The intelligence in SRT-H is the new part, but it runs on hardware that is anything but new, and that choice is itself informative. The system was deployed on the da Vinci Research Kit, the dVRK, in its Si configuration. The dVRK is a research platform built from the components of Intuitive Surgical’s da Vinci system, the most widely used surgical robot in the world, made available to academic groups for exactly this kind of experimentation. By building on the dVRK, the team did its work on the same mechanical foundation that already sits in thousands of operating rooms.
That decision separates two questions that are easy to conflate. One is whether the robot’s hands are good enough to do surgery, the mechanical question of precision, dexterity, and reach. The other is whether a machine can decide what to do with those hands, the intelligence question. The da Vinci platform settled the first question years ago; surgeons perform millions of procedures on it. What SRT-H tackles is the second. By using proven hardware, the team isolated the contribution of the AI, and it also kept the result close to the equipment that any eventual clinical version would plausibly use, rather than tying it to a one-off mechanism that exists only in a lab.
The sensing setup is where the hardware was adapted. The standard da Vinci view comes from a stereo endoscope, the dual-lens camera that gives the surgeon depth perception on the console. SRT-H kept that and added two wrist-mounted cameras near the instrument tips. The endoscope provides the overall scene; the wrist cameras provide the close, tool-level view of how the instruments meet the tissue. For a human surgeon the endoscopic view is enough because the surgeon’s trained perception fills in the rest. For a model learning from images, the extra close-up perspective supplies cues that a single distant camera cannot, particularly about whether a grasp has actually taken hold and whether a clip is seated correctly.
The instruments themselves were the ordinary ones for the task: a clip applier for sealing the duct and artery, and scissors for cutting. The constraint that drove the autonomous tool-change request was practical. The workflow needed both instruments, and switching between them required physically changing the tool on the arm, which is why the robot paused and asked for the swap rather than performing it itself. A clinical system would have to handle this more smoothly, but it is an engineering and integration problem rather than a question of whether the AI can run the procedure.
There is a strategic point hiding in the hardware choice. Because SRT-H runs on the dVRK, the gap between this research result and a deployable capability is not primarily about building a new robot. The robot exists. The gap is about the model’s reliability across real anatomy, the regulatory approval such a capability would require, and the integration work to make autonomy a safe feature of an existing platform. That framing should temper both the optimism and the dismissal. The optimist who says a usable product is close underestimates the reliability and regulatory distance. The skeptic who says the hardware is exotic and impractical is simply wrong, because the hardware is the same family of machine already doing the world’s robot-assisted surgery.
A 100 percent success rate and what it leaves out
The number that traveled furthest from this study is 100 percent, and it is the number most in need of careful handling. It is true, it is impressive in context, and it supports far less than a casual reading assumes. Understanding exactly what it counts is the difference between an informed view of the result and a misled one.
The figure refers to the system completing the clipping-and-cutting phase successfully on all eight unseen ex vivo pig gallbladders it was tested on, operating fully autonomously through the surgical decisions, with self-correction and without a human taking control. “Unseen” is the word doing real work. The robot was not repeating a motion on the same setup it had trained on; it was generalizing to gallbladders it had never encountered, which is a meaningfully harder test than reproducing a memorized trajectory. For an autonomous soft-tissue system, succeeding on every member of a set of novel specimens is a strong result, and it is the kind of consistency earlier systems could not deliver outside their controlled conditions.
Now the limits, each of which the team itself acknowledged. First, eight is a small sample. A 100 percent rate on eight specimens is statistically thin; it is entirely compatible with a real failure rate that would be unacceptable in a clinic, simply because eight trials cannot resolve a rate of failure that might be one in twenty or one in a hundred. The honest statistical statement is that the system succeeded on all eight, not that it has a vanishingly small failure rate. Second, the tissue was cadaveric pig tissue, which strips out the hardest variables of real surgery: no active bleeding to obscure the field and create urgency, no breathing or heartbeat moving the anatomy, no inflammation or scarring distorting the structures, and a narrower range of anatomical variation than a human population presents.
Third, the robot was slower than a human surgeon, completing the phase with quality described as comparable to expert work but taking more time to do it. In a controlled experiment, slower is a footnote. In an operating room, where time under anesthesia carries its own risks and operating-room minutes are expensive, speed is part of whether a capability is usable at all. Fourth, the test covered one phase of one operation, not a full procedure, and not the range of procedures a surgical service performs. The 17 tasks are real, but they are 17 tasks in a single, deliberately chosen part of a single operation.
The right way to hold the number is as an engineering milestone and a weak clinical claim at the same time. As engineering, succeeding on every novel specimen with autonomous recovery is exactly the kind of consistency the field needed to show, and it moves the conversation forward. As medicine, it is nowhere near evidence that the system is safe for a living person, and the team did not claim otherwise. The danger is not in the number but in the compression that turns “100 percent on eight pig gallbladders in one phase” into “the robot does surgery perfectly.” That compression is how a careful result becomes an overclaim in the public mind, and the gap between the two is the subject the researchers and their critics both ended up addressing directly.
The rung this result occupies on the ladder of surgical autonomy
To judge a result like SRT-H, the field uses a graded scale of autonomy rather than a yes-or-no label, and placing the work on that scale clears up most of the confusion about what it does and does not represent. The framework, often described as the levels of autonomy for surgical robots, runs from a robot that does nothing on its own to a robot that needs no human at all, with the interesting territory in between.
Levels of autonomy in surgical robotics
| Level | Name | What the system does | Example |
|---|---|---|---|
| 1 | Robot assistance | The surgeon controls every motion; the robot steadies or scales movement | da Vinci in standard use, surgeon-driven |
| 2 | Task autonomy | The robot performs a specific task on a discrete command from the surgeon | Automated suturing initiated by the operator |
| 3 | Conditional autonomy | The robot generates a strategy, but a human must approve or select it | STAR-class systems requiring human sign-off |
| 4 | High autonomy | The robot makes and executes decisions under human supervision, without step-by-step approval | The level SRT-H’s authors claim for this work |
| 5 | Full autonomy | The robot performs the procedure with no human involvement | No real surgical system today |
This ladder maps a system’s decision-making and action-taking ability; the higher the level, the more the machine decides for itself, and the standard da Vinci in everyday use sits at the bottom because the surgeon drives every motion.
The authors placed SRT-H at level 4, high autonomy, and their reasoning is specific. The defining feature of level 3, conditional autonomy, is that a human has to directly approve the robot’s strategy before it acts. SRT-H did not require that approval; it generated and executed its plan on its own, with human input arriving as occasional spoken correction rather than as mandatory sign-off on each step. By that logic the system clears level 3 and belongs at level 4. It plainly is not level 5, because humans were present, supervising, occasionally correcting, and physically changing tools. The team’s claim is high autonomy under supervision, not full autonomy, and that is the accurate description.
The placement matters because of where the rest of the deployed world sits. A systematic review of surgical robots cleared by U.S. regulators between 2015 and 2023 found that the overwhelming majority, around 86 percent, were at level 1, mere robot assistance, and only a small fraction, roughly 6 percent, reached level 3, conditional autonomy. In other words, almost everything a patient might actually encounter in an operating room today is a tool the surgeon drives, and even conditional autonomy is rare in approved practice. A research system demonstrating level-4 behavior, even on cadaveric tissue in one phase, is therefore well ahead of what is cleared for clinical use, which is precisely the gap that makes the result notable and the regulatory questions urgent.
It is worth being clear that the levels are a description, not a safety guarantee. A system can be at level 4 and still be unsafe, because the level says only how much the machine decides, not how well it decides or how reliably. The scale answers “how autonomous,” not “how trustworthy.” SRT-H’s level-4 claim tells you the robot ran the phase without per-step approval. It does not tell you the robot is ready to do that on a person, and conflating the two, treating a high autonomy level as if it were a clinical endorsement, is one of the more common misreadings. The honest summary is that SRT-H sits at a level of autonomy that essentially no approved surgical system occupies, on a task and tissue that fall short of clinical conditions, which is exactly why it is both a real advance and an early one.
The cholecystectomy itself and why surgeons picked it
The choice of operation was not arbitrary, and understanding why a gallbladder removal made a sensible first target explains both the ambition and the caution in the work. Cholecystectomy is one of the most common abdominal operations in the world, performed hundreds of thousands of times a year in any large country, usually to treat gallstones and the pain or infection they cause. Its ubiquity means the procedure is well understood, well documented, and clinically meaningful in a way a rare or exotic operation would not be. A robot that could one day help with cholecystectomy would be addressing real, high-volume demand rather than a curiosity.
The anatomy also lends itself to a first attempt. The gallbladder sits in a reasonably predictable location under the liver, which gives a learning system a more consistent starting point than organs whose position varies widely. At the same time, the region is not simple. It presents a mix of structures that must not be confused: the cystic duct, the cystic artery, the common bile duct nearby, and the surrounding fat and connective tissue. The combination of a predictable location and genuinely demanding local anatomy is close to ideal for a research target, hard enough to be a real test, structured enough to be tractable.
The clipping-and-cutting phase carries a specific and well-known risk that makes precision matter. The danger surgeons worry about most in this operation is injury to the common bile duct, the main channel carrying bile from the liver to the intestine. If a surgeon mistakes the common bile duct for the cystic duct and clips or cuts it, the consequences for the patient are severe and often lifelong, requiring major reconstructive surgery and sometimes leaving lasting harm. Bile duct injury is the classic catastrophic error of cholecystectomy, and avoiding it depends entirely on correctly identifying the structures before sealing and dividing them. A task where misidentification produces lifelong complications is a demanding place to test whether a machine can correctly distinguish anatomy and act on it.
That risk profile cuts both ways for the argument about autonomy. On one hand, it is the reason the phase is a serious test: getting the clips and cuts right means the system identified the correct structures and treated them appropriately, which is the crux of doing the operation safely. On the other hand, it is the reason cadaveric pig tissue is a soft version of the real challenge. In a living patient with a diseased gallbladder, the anatomy is often obscured by inflammation, distorted by scarring, or hidden in dense adhesions from previous episodes, which is exactly when surgeons are most likely to misidentify the bile duct and exactly the condition the cadaveric model does not reproduce. The phase SRT-H performed is the right phase to test; the tissue it was tested on is the easy version of the conditions that make that phase dangerous.
There is a reason researchers across the autonomous-surgery field keep returning to procedures like this one. They want tasks that are common enough to matter, structured enough to learn, and consequential enough that getting them right would justify the effort, while still being approachable with current methods. Cholecystectomy fits, which is why it appears not only in SRT-H but across the broader set of surgical-automation efforts and datasets now emerging. Picking it signals a field trying to work on problems that would matter clinically rather than on contrived demonstrations, and it sets up the central tension the next section examines, the distance between performing the right phase on the easy tissue and performing it on the tissue that makes the phase hard.
The gap between a pig cadaver and a living patient
Everything that makes SRT-H impressive was demonstrated on ex vivo porcine tissue, and everything that makes its clinical relevance uncertain lives in the difference between that tissue and a living human being. The team was direct about this; in responding to commentary on the work they wrote that they accomplished autonomous robotic surgery for a phase of cholecystectomy in pig cadavers, but that much more work is needed to move into living subjects and eventually human studies, where patient-to-patient variation and inflammation present far greater challenges. The gap is not a detail to be closed by tuning. It is several distinct problems stacked together.
The first is bleeding. A cadaver does not bleed. In a living patient, even a small vessel nicked at the wrong moment fills the surgical field with blood, obscures the camera view the model depends on, and creates time pressure to control the bleeding before it worsens. A vision-driven system that has never had to operate through obscured views, identify a bleeding source, and manage it has not faced one of the defining challenges of real surgery. Bleeding is not an edge case in the operating room; it is a routine condition that competent surgery manages constantly, and it is almost entirely absent from cadaveric training and testing.
The second is motion. A living body breathes and has a beating heart, and both move the abdominal organs continuously. The anatomy a surgeon works on is not still; it shifts with every breath and pulse. A model trained and tested on motionless cadaveric tissue has not learned to track and compensate for that constant movement, which complicates everything from identifying a structure to placing a clip precisely on it. Respiratory and cardiac motion are persistent conditions of in vivo surgery that the ex vivo setting removes entirely.
The third, and the hardest, is pathology and variation. A research gallbladder is comparatively clean and normal. A gallbladder that has sent a patient to surgery is usually inflamed, sometimes acutely, often surrounded by scar tissue and adhesions from prior episodes, and its anatomy can be distorted to the point where even experienced surgeons proceed with great care to avoid the catastrophic bile duct injury described earlier. The variation across a human patient population, in body habitus, in disease severity, in anatomical anomaly, is far wider than the variation across a set of pig gallbladders. Imitation learning is bounded by what its data contained, and the data did not contain this range, so there is no basis yet for claiming the system would handle it.
These are not reasons to dismiss the work; they are the reasons the team described living subjects, not human patients, as the next step, and human studies as a more distant goal beyond that. The standard research path runs from ex vivo tissue to live animal models to eventually, after extensive additional work, carefully controlled human trials. Each of those transitions has historically taken years and has defeated approaches that looked promising in the controlled setting. The honest position is that SRT-H proved a method works under contained conditions and left open the question of whether it survives contact with the conditions that make surgery difficult. The team’s own words, that they accomplished a phase in pig cadavers and that far greater challenges lie ahead, are the most accurate one-sentence summary of where the result stands.
The researchers’ framing versus the headlines
The distance between what SRT-H demonstrated and what some coverage suggested became a small public argument in its own right, and it is unusually well documented because it played out in the pages of the journal that published the work. The episode is worth recounting, because it shows both researchers and critics converging on the same careful reading, and because it is a clean case study in how a precise scientific result becomes an imprecise public one.
The authors’ own language was consistently restrained. They called the achievement step-level autonomy within a defined surgical context, not autonomous surgery in general. Krieger’s strongest public statement was about a shift in kind, from robots that execute tasks to robots that understand procedures, which is a claim about capability rather than clinical readiness. Kim emphasized reliability as the barrier the work addressed and described the result as showing that surgical autonomy is demonstrably viable, again a statement scoped to what the experiment showed rather than a promise about patients. The framing built into the paper, ex vivo, one phase, a defined task, was not buried; it was the headline of the work for the people who wrote it.
The coverage that followed often kept less of that precision. Headlines compressed “autonomous completion of the clipping-and-cutting phase on pig cadavers” into “robot performs surgery on its own,” and some accounts blurred the tissue, describing the procedure variously as performed on a realistic model or a lifelike patient in ways that muddied the simple fact that it was pig gallbladder tissue. None of this was fabrication; it was the ordinary slippage of a careful claim losing its qualifications as it passes through retelling. But the cumulative effect was to imply a clinical reality, a robot ready or nearly ready to operate on people, that the work did not support.
The most telling part is what happened in the journal afterward. A published commentary noted that while the authors had carefully framed their work as step-level autonomy in a constrained context, some media coverage had amplified it to the impression that a robot performs surgery on its own, which risked overinterpreting the immediate clinical significance, and the commentary was explicit that this was through no fault of the authors. The researchers then responded, and their reply is candid. They agreed that some media coverage overstated the achievements beyond their intention. They reaffirmed that the work was a phase in pig cadavers with far greater challenges ahead in living subjects and humans. They defended their level-4 placement on the specific technical grounds that the robot did not require the human strategy approval that defines level 3.
Their response also contained a revealing line about incentives. Rather than simply lamenting the overstatement, they argued that hype can be positive, because it draws more people and more effort to the problem and can accelerate progress. That is an honest acknowledgment of a real dynamic in science, that attention brings talent and funding, and it is also exactly the mechanism by which careful results get oversold. A field benefits from the energy that hype attracts and pays for it in public misunderstanding, and the SRT-H episode shows researchers managing that trade-off in real time, defending their precise claims while declining to be too troubled by the imprecise versions circulating around them.
For a reader trying to form an accurate view, the lesson is to take the authors’ scoped language over the headlines’ compressed version, and to notice that the people closest to the work were the ones most insistent on its limits. The result is genuinely a milestone in autonomous-surgery research. It is genuinely not evidence that a robot is about to operate on a person. Both statements come straight from the researchers, and the gap between them is the part the headlines tended to lose.
The surgical robotics market this result lands in
A research result does not arrive in a vacuum; it lands in an industry with an established structure, dominant players, and strong economics, and understanding that setting is necessary to read what autonomy would actually mean commercially. The surgical robotics market is large, growing quickly, and unusually concentrated, and the shape of it determines who would gain or lose if autonomous capability matured.
The market was valued in the range of seven billion dollars in 2024 by several analyses, with forecasts pointing toward figures several times larger over the following decade and compound annual growth rates commonly estimated around 15 percent. Different analysts put the precise numbers in different places, but the direction is consistent: this is a market expanding fast on the back of rising demand for minimally invasive procedures, shorter recovery times, and the steady migration of operations onto robotic platforms. The growth is not speculative; it is driven by procedure volumes that climb year after year.
The defining feature of the market is the dominance of one company. Intuitive Surgical, maker of the da Vinci system, controls well over 70 percent of global robotic procedures, by some measures closer to 80 percent, through an installed base that surpassed ten thousand systems in 2025 and continued climbing. The scale is hard to overstate: in 2024 alone, more than two and a half million procedures were performed on da Vinci systems, and the cumulative total across the platform’s history runs into the tens of millions. Intuitive has been at this since the early 2000s, and that head start has compounded into a position that newer entrants find extremely hard to challenge.
The economics behind that position are as important as the hardware. Intuitive’s business does not rest mainly on selling robots; it rests on the recurring revenue from the instruments and accessories consumed in every procedure, plus service contracts. Analyses commonly attribute the largest single share of the market, well over half, to instruments and accessories rather than to the systems themselves. This is the razor-and-blades pattern applied to surgery: the system is the razor, placed in hospitals to generate a stream of per-procedure consumable sales that follows for years. It produces durable, predictable revenue, and it locks hospitals in, because once an institution has standardized on a platform, the switching costs in retraining, requalification, and consumable supply are high.
That structure creates both a strong incumbent and strong barriers to entry. A challenger has to overcome not just Intuitive’s technology but its installed base, its training ecosystem, its accumulated procedure data, and the high switching costs that keep hospitals on the platform they already use. The barriers, substantial research and development costs, the regulatory burden of clearing a surgical robot, and the installed-base advantage, are exactly why the market has remained an oligopoly rather than opening into broad competition. Into this setting, autonomy enters as a potential new axis of competition, a capability that does not yet exist in any approved product and that could, if it matured, shift the basis on which these systems compete. Whether it strengthens the incumbent’s moat or gives challengers an opening is a genuinely open question, and it depends on who can turn research like SRT-H into a safe, approved, integrated feature first.
The challengers circling Intuitive’s lead
The incumbent’s dominance has not gone unchallenged, and the field of competitors matters for the autonomy question because the companies racing to take share from Intuitive are the same ones that would eventually decide whether to build advanced AI into their platforms. The competitive picture as of 2025 and into 2026 is a set of well-funded challengers attacking from different angles, none yet close to Intuitive’s scale but several gaining real traction.
The most credible challenger by sheer corporate weight is Medtronic with its Hugo system. Medtronic is one of the largest medical-device companies in the world, and its strategy leans on that scale: deep existing relationships with hospital purchasing departments, a modular system design, and pairing the robot with its broad portfolio of surgical instruments. Hugo has been in use in Europe since 2022 and has expanded across more than two dozen countries, and Medtronic has been working through the clinical studies needed for U.S. clearance, with investigational studies in areas including urology, hernia repair, and gynecology reported to have met their primary safety and effectiveness endpoints. Hugo’s threat to Intuitive comes less from technical superiority than from Medtronic’s ability to compete on price, distribution, and entrenched commercial reach.
The nearest rival to da Vinci by procedure count globally is CMR Surgical’s Versius, a British system built around a modular, cart-based design meant to fit more flexibly into operating rooms and to suit smaller and outpatient settings. Versius made a notable regulatory step by securing U.S. authorization through the De Novo pathway in late 2024, initially for cholecystectomy, the very operation at the center of the SRT-H work, and it has been expanding commercially across Europe, India, and Latin America. Its pitch is flexibility and lower cost, aimed at the structural shift of suitable cases toward ambulatory surgery centers where the large, fixed footprint of a traditional system is a poor fit.
A third major entrant is Johnson & Johnson with its Ottava system, which has been developed with characteristic secrecy and aims at a fully integrated, low-footprint design competing on workflow efficiency. J&J brings a vast surgical-instrument business and a clinical network spanning well over a hundred countries, and Ottava has been moving through the U.S. regulatory process, with the company layering machine-learning features such as port guidance and collision prediction onto the platform. Its advantage, like Medtronic’s, is commercial infrastructure rather than a decisive technical lead, and it faces the same hurdles of regulatory approval and surgeon adoption against Intuitive’s long head start.
Beyond these soft-tissue rivals, the market has specialized players that matter for the broader picture. Stryker’s Mako system dominates orthopedic robotics, holding more than half of that segment and effectively limiting Intuitive’s expansion into joint replacement, and orthopedic robots are notable because some, like systems for bone milling, already perform automated actions within their narrow domain. Chinese manufacturers such as MicroPort and TINAVI are deploying price-competitive systems aligned with domestic reimbursement, expanding across the Asia-Pacific region and threatening established margins in those markets. And a category of lighter assistant robots is emerging for outpatient economics and staffing constraints, reflecting the same pressures pushing the field toward smaller, more flexible systems.
The competitive frontier, as industry observers describe it, is shifting from mechanics to software and data: advanced vision, energy integration, AI-assisted workflows, and cloud connectivity. Every major player is investing in intraoperative AI features, and the next generation of flagship systems emphasizes data capture and machine-learning-assisted guidance. This is the setting that makes a result like SRT-H commercially relevant even though it came from a university lab. It demonstrates a capability, step-level autonomy with self-correction, that sits at the far end of the software-and-data axis the whole industry is now competing on. Whichever company can eventually turn that kind of research into a safe, approved, integrated feature would hold something none of its rivals has, which is why the autonomy question is not academic for any of them.
The business-model stakes of autonomy for device makers
If autonomous capability matured into something approvable and deployable, it would not simply add a feature to existing surgical robots; it would press on the business models underneath them, and the direction of that pressure is worth thinking through carefully because it is not obvious. Autonomy could entrench the incumbent, or it could give challengers an opening, and the case for each is real.
The argument that autonomy strengthens the incumbent starts with data. Learning-based surgical systems are built from demonstration data, and the more procedures a platform performs, the more data its maker can, in principle, accumulate to train and improve autonomous features. Intuitive performs the overwhelming majority of the world’s robotic procedures, which means it sits on a data position no rival can match, and its newest systems emphasize data capture precisely because the company understands this. If autonomy is fundamentally a data problem, the player with the most procedures has a compounding advantage, and autonomy becomes another layer of an already deep moat. The recurring-revenue model would survive intact or strengthen, because autonomous features could be sold as premium capabilities consumed per procedure, extending the per-use economics that already define the business.
The argument that autonomy opens the door for challengers runs the other way. A genuinely new capability resets some of the basis of competition. Hospitals choose platforms partly on what those platforms can do, and a challenger that fielded a meaningful autonomy or AI-assistance feature first could differentiate itself in a way that raw catch-up on mechanical performance never allowed. The shift toward software and data also favors companies with strong AI capabilities regardless of their installed base, and the migration of cases to ambulatory centers rewards flexible, lower-cost systems where a smart assistant that reduces staffing demands could be a deciding factor. Crucially, much of the foundational research is happening in the open, in university labs publishing methods and releasing datasets, which means the core techniques are not locked inside the incumbent. A challenger that integrated open research effectively could partly bypass the data advantage.
There is also a structural point about where value would accrue. Today, value sits heavily in consumables and the installed base. Autonomy could shift some of it toward software, data, and per-procedure intelligence, a different kind of recurring revenue that rewards algorithmic capability and data assets rather than only razor-and-blades hardware economics. That shift would favor whichever companies can build and validate reliable surgical AI, a skill set that overlaps only partly with the mechanical and commercial strengths that define the current leaders. A device maker that is excellent at hardware and distribution but weak at machine learning could find the ground shifting under a competitive position it thought was secure.
None of this is near-term. The capability does not exist in any approved product, the regulatory path for autonomy is unsettled, and the liability questions are unresolved, all of which the later sections address. But device makers do not plan on near-term horizons, and the strategic logic is already visible in their behavior: every major player is investing in intraoperative AI, the newest systems are built around data capture, and the public framing of the competitive frontier has moved decisively toward software and intelligence. SRT-H is a research result, but it is a research result that points directly at the axis these companies have chosen to fight on, and that is why it belongs in any serious reading of where the industry is heading rather than only in a science section.
Hospitals, the operating room, and the economics of an unattended robot
Whatever autonomy eventually means for device makers, it would be felt most concretely by the hospitals that buy and run these systems, and the economics there are specific enough to make the abstract promise of autonomy concrete. A robot that could perform parts of a procedure with less direct surgeon involvement would touch hospital costs, operating-room throughput, and staffing in ways that explain why institutions are interested even though the technology is not ready.
Robotic surgery is already expensive to adopt. A surgical system represents a capital outlay in the low millions, the consumable instruments add a per-procedure cost, and service contracts run continuously, on top of which sits the cost of training surgeons and staff to use the platform. Hospitals justify this against benefits that are real but sometimes contested: robotic approaches can enable minimally invasive techniques that reduce patient length of stay and recovery time, and they can improve outcomes for specific patient groups such as those with obesity or complex anatomy. The financial case for robotics today rests on procedure volume and these downstream benefits rather than on any labor savings, because the systems require at least as much skilled human involvement as conventional surgery, not less.
Autonomy is interesting to hospital economics precisely because it could change the labor side of that equation, which nothing in current robotics does. If a system could reliably handle defined portions of a procedure, the most-discussed effect is on operating-room throughput and the use of scarce surgeon time. A surgeon’s attention is the binding constraint in most surgical services; there are only so many hours in a day and only so many trained surgeons. A capability that let a surgeon supervise rather than execute certain steps, or that handled repetitive sub-tasks while the surgeon focused on the parts requiring judgment, could in principle let a given number of surgeons handle more cases. Whether it actually would depends on speed, and here the current evidence is a caution: SRT-H was slower than a human, and a slower autonomous step is a throughput loss, not a gain, until the speed gap closes.
The structural shift in where surgery happens makes autonomy more relevant, not less. A substantial and growing share of suitable procedures is migrating to ambulatory surgery centers, outpatient facilities with tighter economics and tighter staffing than large hospitals. These settings reward systems with smaller footprints, faster room turnover, and lower staffing demands, which is exactly why the lighter, modular, assistant-style robots are gaining attention. An autonomy or strong-assistance feature that reduced the number of skilled hands needed per case would fit the outpatient model well, where every minute of room time and every staff member carries a sharper cost than in a large academic center.
Consistency is the other economic argument, and it is subtle. Surgical outcomes vary with the individual surgeon’s skill and even with the same surgeon’s day-to-day performance, fatigue, and experience. Part of the long-run case for autonomy is reducing that variation, delivering a consistent standard regardless of which surgeon is available or how tired they are. For a hospital, lower variation can mean fewer complications, fewer repeat procedures, and lower associated costs, which is a meaningful financial benefit even before any labor savings. The catch is that consistency only helps if the consistent standard is high; a system that reliably performs at a mediocre level would entrench mediocrity, and demonstrating that an autonomous system performs consistently at an expert level across real patients is exactly what has not been shown.
The realistic near-term picture for hospitals is not autonomy at all but incremental AI assistance: better visualization, guidance features, automation of small repetitive sub-tasks, and decision support, layered onto systems that surgeons still drive. These features improve workflow and may improve outcomes without raising the regulatory and liability questions that full autonomy does, and they are what the industry is actually shipping. Autonomy of the kind SRT-H demonstrates sits beyond that horizon, a capability hospitals have reason to watch and prepare for but not to plan budgets around yet. The economics are genuinely attractive in the long run and genuinely speculative in the short run, and the gap between those is filled by the reliability, speed, and regulatory work the technology still requires.
The surgical workforce problem this technology is aimed at
Behind the engineering and the economics sits the motivation that researchers in this field return to repeatedly, and it is a serious one: there are not enough surgeons in the world, and the shortfall causes measurable harm. Autonomous and assistive surgical systems are pitched, in large part, as a response to that shortage, and the scale of the problem explains why the goal is taken seriously even by people skeptical of the current technology.
The global figures are stark. By common estimates, a large majority of the world’s population, on the order of two-thirds, lacks reliable access to safe surgical care when they need it. The Lancet Commission on Global Surgery, the most-cited authority on the subject, has framed surgery as a neglected component of universal health coverage and estimated that deficiencies in surgical, obstetric, and anesthesia care contribute to roughly 18 million preventable deaths a year. Surgery is not a marginal part of medicine; it addresses a substantial share of the global disease burden, commonly estimated near 30 percent, and a large fraction of hospital inpatients undergo a major operation at some point in their care. A shortage of surgical capacity is therefore a shortage with a body count, concentrated heavily in lower-income regions but not absent from wealthy ones.
Even rich countries with comparatively good access face a workforce squeeze driven by demographics. In the United States, where surgical access is relatively high, an aging population is expected to increase demand for surgery faster than the supply of surgeons can grow, with projections pointing to a shortage of something like 10,000 to 20,000 surgical specialists within the next decade or so. Surgeons take many years and great expense to train, the pipeline cannot be expanded quickly, and the existing workforce is itself aging toward retirement. The result is a structural mismatch between rising need and constrained supply that no near-term increase in training can fully close.
This is the gap autonomous surgery is meant to address, and the logic is straightforward even if the execution is hard. If a system could reliably perform parts of procedures, or eventually whole procedures, it could extend the capacity of the existing surgical workforce, letting a limited number of surgeons cover more cases, or allowing care to be delivered in places and at times where a fully staffed surgical team is not available. In the most ambitious version, autonomy could bring a consistent standard of surgical care to settings that currently have none, addressing the access problem at its root rather than at its margins. The appeal is real, and it is why the field frames its work in terms of access and shortage rather than only precision.
The honest qualification is that this motivation, however genuine, does not lower the bar the technology has to clear, and it can be misused to do so. A serious unmet need is a reason to pursue a solution, not a reason to deploy an unready one, and the history of medicine is full of harm done by technologies adopted because the need was urgent before the evidence was sufficient. The places with the least surgical access are also, often, the places least equipped to manage a complex autonomous system safely or to handle its failures, which means the access argument cuts in complicated ways. SRT-H and its peers are aimed at a real and severe problem. Whether they end up easing it or simply adding an expensive, hard-to-deploy technology that mostly benefits well-resourced systems depends on choices about reliability, cost, regulation, and equity that have not yet been made, and that the access framing should inform rather than short-circuit.
The changes ahead for surgeons, residents, and operating-room staff
The people most directly affected by autonomous surgery are the ones in the operating room, and the technology raises pointed questions about their roles, their training, and the skills the next generation of surgeons will or will not develop. The likely path is not replacement but a change in what the human does, and that change carries both relief and risk.
The framing the researchers themselves use is instructive. They describe SRT-H as behaving less like a rigid industrial arm and more like a junior surgeon who can learn on the fly, taking spoken guidance and corrections the way a resident takes them from a mentor. That analogy points to the near-term reality: a surgeon supervising an autonomous or semi-autonomous system would occupy something like the role a senior surgeon plays with a trainee, watching, guiding, correcting, and stepping in when needed, rather than executing every motion personally. The most-discussed benefit of this shift is the handling of repetitive and fatiguing sub-tasks. Surgery involves long stretches of demanding but routine work, and a system that took on the repetitive parts could let surgeons focus their attention and judgment on the parts that genuinely require them, while reducing the physical fatigue that lengthy operations impose. Robotic systems already improve surgeon ergonomics by letting them operate seated at a console rather than hunched over a table, and autonomy extends that logic.
The professional bodies thinking seriously about this future emphasize that AI should sustain rather than disrupt the operating room, supporting the refinement of surgical skill and remaining under human and regulatory oversight, with surgeons as the chief decision-makers. That is the official posture, and it reflects a real concern that the technology be integrated in a way that strengthens surgical teams rather than fragmenting their roles or eroding the lines of responsibility. The vision being articulated is collaborative, a capable assistant within the team, not an autonomous replacement for it.
The sharpest risk in this picture is deskilling. If autonomous systems take over the routine parts of procedures, residents may get less hands-on practice at exactly the foundational tasks that build surgical competence, and the skills a surgeon needs when something goes wrong, when they have to take over from a failing system or handle a complication the machine cannot, are precisely the skills built through the repetitive practice the machine would absorb. A generation of surgeons trained to supervise rather than to do could be less prepared to intervene when intervention is what matters most. This is not hypothetical worry; it is a known dynamic in every field where automation handles the routine and humans are expected to manage the exceptions, and surgery has unusually little tolerance for an unprepared human in the loop at the critical moment.
There is also a question of judgment versus execution. Much of surgical expertise is not in the hands but in the decisions: reading anatomy, recognizing when the standard approach will not work, knowing when to abandon a plan. A system that executes well but lacks that judgment shifts more decision-making weight onto the supervising surgeon, even as it removes the execution practice through which surgeons historically developed their judgment in the first place. Separating the two, automating execution while expecting humans to retain judgment, may prove harder than it sounds, because the two have always been learned together.
The operating-room team beyond the lead surgeon would change too. The SRT-H trials still required a person to physically change instruments when the robot requested it, a role analogous to a scrub nurse, and a realistic autonomous future would reconfigure rather than eliminate the supporting roles, with humans handling the physical setup, the exceptions, and the oversight while the system handles defined execution. How those roles are defined, trained for, and held responsible is unsettled, and it is part of the broader integration question that surgical organizations are urging be worked out through careful, multi-stakeholder discussion rather than left to unfold by default. The technology’s effect on the workforce is not predetermined; it depends on choices about how it is introduced, and the people making those choices have reason to weigh the deskilling risk as heavily as the efficiency promise.
The regulatory machinery that is not ready yet
A capability like SRT-H would have to pass through a regulatory system before it reached patients, and that system was not built for autonomous, learning-based surgical machines. The mismatch between what the technology is becoming and what the rules are designed to handle is one of the most concrete obstacles between research results and clinical reality, and it is widely recognized by the people who study it.
In the United States, surgical robots have historically reached the market through two routes. The 510(k) pathway clears a device by showing it is substantially equivalent to a product already on the market, a predicate, and it is the route most surgical robots have taken; the original da Vinci was cleared this way as a moderate-risk device, setting a precedent that shaped the field. The De Novo pathway is for genuinely new types of device without a clear predicate, and a growing number of newer systems, including recent entrants cleared for specific procedures, have used it. Most surgical robots are classified as Class II, moderate risk, a classification that fit the surgeon-controlled tools the framework was designed around.
The problem is that this machinery was built for tools, not for decision-makers. A systematic review of surgical robots cleared between 2015 and 2023 found that the classification and regulatory frameworks have not kept pace with rising autonomy, that the overwhelming majority of cleared systems sit at the lowest autonomy level, and that the taxonomies regulators use still carry legacy assumptions from an era of purely assistive devices. The current approach places the burden of responsibility on the surgeon as the ultimate decision-maker, which works when the surgeon controls every action but breaks down for a system that generates and executes its own strategy. A robot operating at high autonomy is not a tool the surgeon drives; treating it as one for regulatory purposes does not match what it does.
Several specific gaps make the mismatch worse. As autonomy rises, devices may need to be reclassified to Class III, the high-risk category, with the far more demanding approval that entails, but the criteria for when that threshold is crossed are not clearly defined. The 510(k) route carries a well-documented risk known as predicate creep, where manufacturers add substantial new features while claiming equivalence to older devices, accumulating capability without the scrutiny a genuinely new high-risk function should trigger, a gap that is exploitable and poses a patient-safety risk precisely in the direction of added autonomy. And the frameworks were not designed for adaptive AI, systems that can change their behavior as they learn, which sits uneasily with a regulatory model built to approve a fixed, unchanging device and verify it stays the same.
The consequence is a genuine lag between capability and oversight. Regulators are aware of it, and there are active calls to modernize the frameworks with practical benchmarks that recognize different levels of autonomy and different modes of human-robot interaction, rather than forcing new systems into categories built for old ones. But that modernization has not happened, and until it does, an autonomous capability like SRT-H would face a regulatory route that is either ill-fitting or undefined. This is not a reason the technology cannot advance; it is a reason its path to patients runs through policy work as much as through engineering, and a reason the timeline to clinical use is governed by more than the pace of the research. A system can be technically ready in the lab and still be years from approval because the rules for approving something like it do not yet exist in usable form.
Responsibility when an autonomous robot makes the wrong move
The regulatory gap has a twin in the legal one, and it may be the harder of the two: when an autonomous surgical system harms a patient, it is genuinely unclear who is responsible, and that uncertainty is a serious obstacle to deployment that engineering alone cannot resolve. The question of liability is repeatedly named by researchers and clinicians as one of the substantial institutional hurdles to clinical translation, and it has no settled answer.
Today the lines are clear because the surgeon is in control. If a surgeon makes an error during a robot-assisted procedure, the framework of medical malpractice applies in the ordinary way; the surgeon, and by extension the institution, bears responsibility for the clinical decisions and actions. The robot is a tool, and a tool’s maker is liable only for defects in the tool, not for how a competent surgeon used it. This allocation has worked for decades of surgeon-driven robotics because it matches reality: the human made the decisions and performed the actions, so the human is accountable for them.
Autonomy breaks that match. If a system generates and executes its own surgical strategy and that strategy causes harm, the surgeon who supervised it did not make the decision in the way malpractice law assumes, which makes it strained to hold the surgeon responsible for a choice the machine made. But shifting responsibility to the manufacturer under product-liability law raises its own difficulties, because a learning-based system’s behavior depends on its training data and its situation in ways that do not fit neatly into the categories of manufacturing defect or design defect, and a manufacturer may reasonably resist open-ended liability for every decision an autonomous system makes across the unpredictable range of real patients. The accountability could plausibly land on the surgeon, the manufacturer, the hospital that chose to deploy the system, or some combination, and no clear rule currently assigns it.
The adaptive nature of the technology sharpens the problem further. A system that changes as it learns is not the same product from one moment to the next in the way liability frameworks assume, which complicates any attempt to pin responsibility on a fixed design. And the supervisory role itself is ambiguous: a surgeon supervising an autonomous system is expected to catch and correct its errors, but if the system is fast, complex, and mostly reliable, the human supervisor faces the well-documented difficulty of staying genuinely engaged enough to intervene at the right instant, the same automation-oversight problem that troubles other safety-critical domains. Holding a supervisor liable for failing to catch an error the system was designed to make unlikely, in the brief window available to catch it, is legally and ethically fraught.
This uncertainty is not a side issue that gets resolved after deployment; it is a precondition for deployment. Hospitals will be cautious about adopting systems whose failure exposes them to undefined liability, manufacturers will be cautious about building capabilities that expose them to open-ended product-liability risk, and insurers will struggle to price a risk whose responsibility is unallocated. The clinicians and researchers urging careful preparation for this technology consistently list clarity of liability among the things that must be worked out, alongside bias, integration, equity, and regulation, and they frame it as requiring deliberate multi-stakeholder effort rather than emerging on its own. Until there is a workable answer to who is responsible when an autonomous robot errs, the legal exposure will act as a brake on adoption regardless of how good the technology becomes, which means the path from a result like SRT-H to a deployed capability runs through courtrooms and legislatures and insurance models as surely as it runs through laboratories.
Data, consent, and the surgical video pipeline
Learning-based surgical systems are built from recordings of surgery, and that fact opens a set of questions about data, consent, and privacy that are easy to overlook amid the engineering but that shape both the ethics and the practicality of the technology. The same data dependence that makes these systems possible makes them subject to concerns the field is only beginning to address.
The foundation of a system like SRT-H is demonstration data: thousands of recordings pairing what the cameras saw with what the instruments did. For the SRT-H work, that data came from teleoperated procedures on pig cadavers, which raises few human-data concerns of its own. But the trajectory of the field points toward training on data from real human surgeries, because the variation, pathology, and conditions that the cadaveric data lacks exist only in recordings of actual patients, and the obvious way to teach a system to handle real surgery is to train it on real surgery. That shift moves the data question from animal tissue to patient information, and patient surgical recordings are sensitive in ways that demand careful handling.
Surgical video and the associated data are patient health information, and using them to train AI raises the standard questions of medical-data governance: whether patients consented to their procedures being recorded and used for this purpose, how the data is de-identified given that surgical footage can be hard to fully anonymize, who holds and controls it, and how it is secured. Hospitals, device makers, and academic groups all have potential claims and interests in surgical recordings, and the question of who owns and may use the vast amount of data that robotic systems already capture is not cleanly settled. A platform that performs millions of procedures generates an enormous data asset, and the rules governing that asset, what the maker may do with it, what the hospital and patient retain, sit at the intersection of privacy law, contract, and medical ethics.
There is a competitive dimension to this as well, which connects the data question back to the market. If autonomous capability depends on training data, then control of surgical data becomes a strategic asset, and the company performing the most procedures holds the largest store of it. That concentration raises concerns beyond the individual patient: it could entrench market power, and it makes the governance of surgical data a matter of both privacy and competition. The same recordings that train a system to operate more safely also constitute a commercially valuable resource whose control confers advantage, and balancing patient interests against that commercial logic is an unresolved problem.
Bias enters through the data too, though it deserves its own treatment and gets it in the next section. The short version is that a system trained on data from particular institutions, particular populations, and particular surgeons will reflect the characteristics and limitations of that data, and the question of whether the training data adequately represents the diversity of patients the system would eventually serve is both a safety question and an equity question. The people thinking carefully about this future name minimization of bias alongside liability and regulation as a requirement for responsible deployment, and bias is fundamentally downstream of data: what the system learns, and therefore who it serves well and who it serves poorly, is determined by whose surgeries it was trained on. The data pipeline that makes autonomous surgery possible is also the pipeline through which its fairness, its privacy protections, and its concentration of power will be decided, and none of those are settled by the engineering that gets the robot to clip and cut correctly.
The failure modes that matter most in soft-tissue surgery
A clear-eyed view of autonomous surgery means thinking carefully about how it fails, not only how it succeeds, because in surgery the failures are what determine whether a system is safe enough to use. SRT-H’s self-correction addresses some failure modes and leaves others untouched, and the ones it does not yet address are the ones most likely to cause harm in a living patient.
The first and most consequential is bleeding from a vessel injury. The whole point of the clipping-and-cutting phase is to seal vessels before dividing them, and the catastrophic version of failure is a vessel that is cut without being properly sealed, or a clip that slips or sits wrong, producing bleeding. In cadaveric tissue there is no blood to flow, so this failure mode is invisible during testing; the system can place a clip imperfectly without any of the consequences that imperfection would have in a living patient. A system validated where vessel-injury bleeding cannot occur has not been tested against one of the defining dangers of the procedure, and managing active bleeding, recognizing it, controlling it, working through the obscured view it creates, is a skill the cadaveric setting cannot teach or test.
The second is misidentification of anatomy, specifically confusing the common bile duct for the cystic duct, the classic catastrophic error discussed earlier. The system’s success depends on correctly identifying which structure is which before sealing and dividing it, and on clean cadaveric tissue with clear anatomy that identification is comparatively easy. In a diseased gallbladder obscured by inflammation and scarring, the identification is hard even for experienced surgeons, and a system that has not been tested against distorted anatomy has not been tested against the conditions under which misidentification actually happens. A confident wrong identification, the model treating the common bile duct as the cystic duct and acting on it, is precisely the kind of error that does lifelong harm, and a vision-based system trained on clear anatomy is exactly the kind of system that might make it when the anatomy is unclear.
The third is distribution shift, the general problem that a learning-based system encounters a situation sufficiently different from its training data that its behavior becomes unreliable. The whole class of conditions that distinguish a living patient from a pig cadaver, bleeding, motion, inflammation, anatomical variation, pathology, represents a distribution the model was not trained on, and a system can behave confidently and wrongly when it is outside its training distribution, because it has no internal signal that it has left the territory it understands. This is the deepest reason the cadaveric result does not transfer automatically: not just that the model has not seen these conditions, but that a model outside its distribution may act with the same apparent confidence it shows inside it, which makes its failures hard to anticipate.
The fourth is occlusion and perception failure under realistic conditions. The system depends on its cameras to know what is happening, and surgery routinely obscures the view, with blood, with smoke from cautery, with tissue and instruments blocking the structures of interest. SRT-H’s multi-camera design and temporal context improve its perception, but a vision-driven system is fundamentally vulnerable when it cannot see, and the conditions that obscure the view are common in real surgery and largely absent from the controlled test. A system that loses track of the anatomy because the field is obscured, and acts on a degraded or wrong perception, is a specific and realistic failure mode that the clean cadaveric setting does not stress.
What SRT-H’s self-correction does address is the routine, recoverable error: the slipped grasp, the slightly off clip, the suboptimal state that a corrective instruction can fix. That is real and valuable, and it is more than earlier systems managed. What it does not yet address is the catastrophic, irreversible error under realistic conditions, the wrong cut, the unsealed vessel, the misidentified duct, made worse by bleeding or obscured views the system has never faced. The distance between handling recoverable errors on clean tissue and handling catastrophic errors on diseased, bleeding, moving anatomy is the distance the technology still has to cover, and it is why the careful conclusion is that SRT-H demonstrated a capability while leaving the hardest safety questions for the work that must follow.
Bias, generalization, and the limits of imitation learning
Underneath the specific failure modes lies a more fundamental constraint, one built into the method itself: a system that learns by imitating demonstrations is bounded by those demonstrations, and that boundary determines both how well it generalizes and whom it serves. Imitation learning is what gives SRT-H its dexterity, and it is also the source of its deepest limitations, and the two cannot be separated.
The strength of the approach is that it acquires complex, situation-dependent behavior without anyone having to specify rules for every case, which is exactly what defeated the older logic-based methods on soft tissue. The corresponding weakness is that the model only knows what was demonstrated. It does not reason about anatomy from first principles or understand surgery in the way a trained human does; it has learned a mapping from what it has seen to what to do, and outside the range of what it has seen, that mapping has no guarantees. The model’s competence is the competence of its training data, and its incompetence begins wherever its training data ran out.
This is why generalization is the central technical question and why the cadaveric result, however clean, does not settle it. The system generalized across the eight unseen pig gallbladders, which shows it can handle variation within the range its training data spanned. It says nothing about whether it generalizes to variation outside that range, and the variation a human patient population presents, in anatomy, in disease, in body type, in anomaly, is far wider than the variation across pig gallbladders. Generalizing across similar specimens and generalizing across a diverse patient population are different problems, and success at the first is weak evidence for the second.
Bias is generalization seen through the lens of fairness, and it follows directly from the data. A system trained on demonstrations from particular surgeons, at particular institutions, on particular populations, will reflect the characteristics of that data. If the data underrepresents certain body types, certain anatomical variations, or the kinds of presentations more common in some patient groups than others, the system may perform worse for those patients, and it may do so without any signal that it is doing so. This is a recognized concern that runs through serious discussion of surgical AI, where minimization of bias appears consistently among the requirements for responsible deployment, and it is not a problem the engineering of the model solves; it is a problem determined by whose surgeries the model learned from. A technically excellent model trained on non-representative data is a model that works well for some patients and poorly for others, and the access argument for autonomous surgery, that it could serve underserved populations, sits in tension with the data reality that those populations may be exactly the ones least represented in the training data.
There is also a question about whether imitation alone is the right foundation for the most demanding cases. Imitating expert demonstrations teaches a system to do what experts did in the situations the experts faced. The situations where surgery is hardest, the rare anomaly, the unexpected complication, the presentation no one anticipated, are precisely the situations least represented in any demonstration set, because they are rare, and they are precisely the situations where judgment matters most. A method that learns from the common cases may be weakest exactly where the stakes are highest, which is part of why researchers in the field are looking beyond pure imitation toward approaches that could give systems more general capability, the subject the next sections take up. The limits here are not flaws in SRT-H specifically; they are properties of learning from demonstrations, and they define the boundary of what this class of method can be trusted to do until that boundary is pushed by better data, better methods, or both.
SRT-H against the rest of the autonomous-surgery field
SRT-H is the most-discussed recent result in autonomous surgery, but it is one entry in an active field, and placing it against its neighbors shows both what is distinctive about it and where the broader effort is heading. The comparison also corrects the impression, easy to form from a single splashy result, that autonomous surgery is one lab’s project rather than a research front with many groups and approaches.
Selected milestones in autonomous and automated surgery
| System or work | Approach | What it did | Setting |
|---|---|---|---|
| STAR (2022) | Vision-guided control, fixed plan, tissue markers | Intestinal anastomosis on a live pig | In vivo, controlled |
| SRT (2024) | Transformer imitation learning | Three short tasks: needle handling, tissue lifting, suturing | Ex vivo, seconds-long tasks |
| Think Surgical (cleared) | Patient-specific planning, automated milling | Autonomous bone milling in orthopedics, surgeon watching | Clinical, hard tissue |
| SRT-H (2025) | Hierarchical, language-conditioned imitation learning | Clipping-and-cutting phase of cholecystectomy, self-correcting | Ex vivo pig tissue |
| Simulation and foundation-model work (2025-2026) | Sim-to-real transfer, world models, large datasets | Training and evaluating policies at scale | Mostly simulation and ex vivo |
This is a snapshot, not a ranking, and the systems are not directly comparable because they differ in tissue type, task, and setting; what the table shows is a field advancing along several lines at once rather than a single linear march.
The most instructive contrast is with orthopedic robots that already perform automated actions in clinical practice. Systems for joint replacement can generate a patient-specific plan and then autonomously mill bone to match it while the surgeon supervises, and these are cleared, deployed, and used on patients today. The reason they reach clinical use while soft-tissue autonomy does not is the tissue. Bone is rigid, predictable, and does not bleed, move, or vary in the way soft tissue does, which makes automated bone work a far more tractable problem than automated soft-tissue surgery. The existence of clinical automated milling shows that surgical autonomy in a narrow, favorable domain is already real; SRT-H’s contribution is pushing toward the much harder domain of soft, deformable, variable tissue, which is why it is a research result rather than a product even though automated surgery in another form already exists.
Against its own lineage, SRT-H’s distinction is the move from fixed plans and marked tissue to adaptive behavior on unmarked, unseen tissue with self-correction, the shift from STAR’s mapped route to the ability to handle variation, with the 2024 SRT as the bridge that proved the transformer-imitation approach on short tasks before SRT-H chained it into a long, recovering procedure. That progression, controlled live-animal suturing to short ex vivo tasks to a long, adaptive, self-correcting ex vivo phase, is the clearest way to see what each step added.
The frontier the rest of the field is pushing toward is visible in the most recent work, and it points beyond the data-collection approach SRT-H relied on. Researchers are pursuing simulation and sim-to-real transfer, training policies in high-fidelity surgical simulators and transferring them to real robots, which could sidestep the punishing cost of collecting real demonstrations. They are building world foundation models for surgery, large models that could provide broader capability and even automated evaluation of surgical policies. And they are assembling shared datasets like the public cholecystectomy dataset that came out of this effort, so that progress compounds across groups rather than being trapped in individual labs. A 2026 perspective in the literature frames the field’s trajectory as moving from algorithmic control toward what it calls surgical embodied intelligence, with simulation and hybrid approaches as the way past the data scarcity that currently limits everything. SRT-H sits at an interesting point in this picture: it is a strong result from the demonstration-data approach, arriving just as the field begins to look toward methods that would reduce its dependence on exactly that kind of data, which is the tension the next section examines.
The data bottleneck everyone is now racing to solve
The single biggest constraint on autonomous surgery is not the cleverness of the models but the scarcity of the data they need, and recognizing this reframes what SRT-H represents and where progress will come from. The architecture behind SRT-H is impressive, but the field’s experts are increasingly clear that the limiting factor is data, and the race now underway is largely a race to solve the data problem rather than to invent better architectures.
The problem is concrete. A system like SRT-H needed on the order of 20 hours of carefully collected, annotated demonstration data to learn a single phase of a single operation on relatively uniform pig tissue. Scaling that to the full range of procedures, the full variation of human anatomy, and the full set of conditions and complications that real surgery presents would require demonstration data on a scale that is extraordinarily expensive and slow to collect, because every hour of it requires skilled people performing real procedures under recording, and the rarest and most important cases are by definition the hardest to gather. Surgical demonstration data does not exist at internet scale the way text and images do, and it cannot be cheaply generated, which makes data the binding constraint on how far the imitation-learning approach can go.
Three responses to this constraint are visible in the recent work, and together they describe where the field is putting its effort. The first is shared datasets. The same effort that produced SRT-H released a public dataset of ex vivo cholecystectomy demonstrations, segmented into the same surgical tasks and capturing both clean executions and recovery maneuvers, so that other groups can train and benchmark on common data rather than each collecting its own. Shared data lets progress accumulate across the field and lets methods be compared fairly, and it partly addresses the cost problem by spreading the collection effort’s value across many users.
The second, and potentially the most consequential, is simulation and sim-to-real transfer. If realistic surgical scenarios can be generated in high-fidelity simulators, policies could be trained at scale in simulation, where data is effectively unlimited and cheap, and then transferred to real robots. Recent work has pursued exactly this, with approaches that train on abstracted representations so that a policy learned entirely in simulation can be deployed on a real robot and succeed without real-world fine-tuning, and with surgical simulators built specifically to support this kind of training. If simulation transfer works well enough, it could break the data bottleneck that limits the demonstration-collection approach, because the constraint shifts from collecting real procedures to building good simulators, a more scalable problem.
The third is larger and more general models, including the importing of ideas from the broader surge in AI. Researchers are exploring world foundation models for surgery, large models that could provide broad capability and even automated evaluation of surgical policies, reducing the need for human raters to assess every result. The hope is that, as in other areas of AI, scale and generality could produce systems that handle a wider range of situations than narrowly trained models, though surgery’s stakes and its data scarcity make this harder than in domains where data is abundant and errors are cheap.
The significance for reading SRT-H is that it is best understood as a strong proof of a method that the field is simultaneously trying to move beyond. The demonstration-data, imitation-learning approach produced a genuine result, and it also ran into the cost wall that makes everyone look for alternatives. The next major advances in autonomous surgery may come less from better hierarchies or better language conditioning and more from solving the data problem, through simulation, sharing, or scale, because that is the constraint that currently bounds what any architecture can achieve. SRT-H showed what is possible with painstakingly collected real data on a narrow task; the open question is whether the field can get the data, or generate it, to extend that capability to the breadth that clinical surgery demands, and the answer to that question will shape the timeline more than any single modeling advance.
A practical read for clinicians watching this space
For surgeons, residents, and others in clinical practice trying to decide what to make of results like SRT-H, the useful takeaways are specific, and they separate what is worth acting on now from what is worth watching but not yet planning around. The honest near-term picture is less dramatic than the headlines and more relevant to actual practice.
The first practical point is that autonomous surgery is not arriving in clinical practice soon, and nothing about SRT-H changes the immediate reality of robotic surgery, which remains a surgeon-driven tool. A clinician does not need to prepare for autonomous systems operating on their patients in the near term, because the technology is at the research stage, was demonstrated on cadaveric tissue, and faces the reliability, regulatory, and liability obstacles detailed throughout this analysis. The timeline to a living patient is measured in years, and the timeline to routine clinical use is longer still.
What is arriving, and what is worth attention now, is incremental AI assistance layered onto the systems surgeons already use. The features actually shipping and in development, better visualization, guidance, automation of small repetitive sub-tasks, decision support, are the realistic near-term face of AI in surgery, and they are where a practicing clinician will first encounter these capabilities. Engaging with those features, understanding what they do and do not do, and forming a view on where they help is a more useful use of attention than preparing for full autonomy. The trajectory runs through assistance before autonomy, and the assistance is the part that will affect practice first.
The deskilling concern deserves a clinician’s serious attention precisely because it is one they can influence. As assistive and eventually autonomous features take over routine tasks, the question of how residents continue to build foundational skills becomes a real one for surgical education, and the people best placed to address it are the surgeons and educators who design training. A clinician thinking about this future does well to weigh how automation of routine work affects the development of the judgment and manual skill that matter most when something goes wrong, and to treat the preservation of those skills as an active choice rather than something that takes care of itself.
The professional posture that the relevant surgical bodies are converging on is a reasonable guide: AI should support and sustain surgical practice under human oversight, with surgeons remaining the decision-makers, and its introduction should be deliberate rather than driven by hype. A clinician can hold a position that is neither dismissive nor credulous, taking the engineering progress seriously while insisting on the evidence, the oversight, and the integration that responsible adoption requires. Skepticism about overstated claims and openness to genuine capability are compatible, and the SRT-H episode, where the researchers themselves pushed back on the overstatement, models that stance.
Finally, the most accurate single thing a clinician can take from SRT-H is what it actually demonstrated: that a machine can learn to perform a defined surgical phase adaptively and correct its own routine errors under controlled conditions. That is a real research milestone and a reason to expect the field to keep advancing. It is not evidence that autonomous surgery is safe for patients, it does not establish performance on real anatomy, and it does not shorten the regulatory and liability timeline. Holding that precise understanding, impressed by the engineering, clear about the limits, is the most useful read for anyone whose work the technology might eventually touch, and it is the read the people who did the work would endorse.
A practical read for investors and hospital operators
For the people who allocate capital and the people who run operating rooms, SRT-H is a signal about direction rather than a near-term line item, and the useful response is to separate what it means for the long arc of the industry from what it changes about decisions being made this year. The result moves the technology story forward; it does not move the purchasing calculus that hospital operators and device investors actually work with today.
The clearest message for investors is that the center of gravity in surgical robotics is shifting from mechanical engineering toward software, data, and AI, and SRT-H is one of the sharper illustrations of that shift. For most of the field’s history the hard problems were mechanical, the wristed instruments, the precision, the ergonomics, and the incumbent’s advantage was built on that engineering plus a deep installed base and a recurring revenue stream from instruments and accessories. The autonomy research front says the next layer of differentiation will be built in software and data, which is a different kind of moat and a different kind of race. An investor reading SRT-H is reading evidence that the companies and labs with the best data, the best learning methods, and the ability to turn those into cleared, reliable features may shape the next phase, even though the incumbent’s installed base and recurring revenue remain formidable and are not threatened by a cadaveric research result.
The message for hospital operators is more immediately grounded, because it bears on capital decisions with multi-year horizons. A robotic surgery platform is a large purchase with a long life and a continuing cost stream, and operators making those decisions now are weighing systems whose value proposition is still surgeon-controlled operation, not autonomy. Nothing about SRT-H argues for waiting or for changing what an operator buys today, because autonomy is not a feature available for purchase and will not be for years. What the result does suggest is that the software trajectory of any platform matters more than it used to, and that an operator thinking over a long horizon has reason to weigh how a vendor is positioned on AI and data, not because autonomy is imminent but because incremental AI features, better guidance, automation of small sub-tasks, decision support, are the realistic near-term differentiators and will arrive on the platforms best positioned to deliver them.
The economic case that would eventually justify autonomous capability is real but distant, and operators and investors do well to hold it at the right distance. The argument is that autonomy could improve consistency, reduce complication-driven costs, and ease the workload on scarce surgical staff, and over a long horizon those are the kinds of outcomes that change institutional economics. But the same analysis that makes the case also lists everything that has to be true first, reliability on living patients, regulatory clearance for higher autonomy, a resolved liability model, and the workflow integration to make an autonomous step actually save time rather than add supervision overhead. None of those conditions is met, and until they are, the economic case is a thesis about the future rather than a basis for a present decision, which is exactly how a disciplined investor or operator should treat it.
There is also a quieter operational point that matters for anyone modeling this future. An autonomous or semi-autonomous step does not eliminate cost simply by removing a pair of hands; it relocates cost into supervision, validation, integration, and the institutional machinery for handling failure and liability. A result that works in a lab says nothing about whether it saves money in a hospital, and the history of automation in other high-stakes settings is full of cases where the human oversight required to run an automated system safely consumed much of the saving the automation promised. The practical read, then, is to take the technology trajectory seriously, position for the software-and-data phase that SRT-H points toward, and resist treating a cadaveric research milestone as a reason to change a near-term capital or purchasing decision, because the value it gestures at sits behind years of unfinished work.
The realistic timeline to a living patient
The question everyone asks about a result like this is when it reaches a person, and the honest answer is a range of years with a sequence of hard gates in between, each of which can take longer than expected and any of which can stall. Laying out that sequence is more useful than naming a single date, because the path, not the destination, is what determines how long this takes.
The first gate is the move from cadaveric tissue to a living animal, which the researchers have named as their next step and which is harder than it sounds. A living body bleeds, breathes, and reacts; tissue moves with the pulse and respiration, bleeding obscures the field and changes the anatomy in real time, and the controlled stillness of a cadaveric specimen is gone. A system that succeeded on eight pig cadavers has to be shown to work when the tissue is alive and responding, and that is a genuine research problem rather than a formality, because the very conditions that make living surgery hard are the conditions absent from the setting where the result was obtained. Clearing this gate convincingly, across enough cases and enough variation to mean something, is itself a multi-year effort.
The second gate is reliability at a standard fit for human use, which is a far higher bar than a strong result in a study. A 100 percent success rate on eight specimens is a promising research finding; it is not the kind of evidence that establishes a system is safe to use on patients, which requires performance across large numbers, across the full range of anatomical variation and disease and complication, with the rare and dangerous cases included rather than excluded. The gap between “worked every time in a small controlled study” and “reliable enough to operate on a person” is enormous, and closing it means demonstrating consistent performance precisely on the hard, varied, unpredictable cases that a small uniform study does not contain. This is the gate where many promising medical technologies slow down or stop, because the real world is more varied than any study population.
The third gate is regulatory clearance for a level of autonomy that existing pathways were not built to handle, examined earlier in this analysis. A system that makes its own intraoperative decisions does not fit comfortably into the predicate-based pathway that has cleared most surgical robots, may face the higher burden reserved for the highest-risk devices, and runs into the unresolved problem of how to regulate a system whose behavior is learned and potentially adaptive. New or adapted regulatory frameworks may be needed, and frameworks of that kind tend to develop slowly, often lagging the technology by years, which adds time that has nothing to do with the engineering and everything to do with the machinery of approval.
The fourth gate is the resolution of liability and the surrounding institutional questions, also covered above. Until there is a workable answer to who is responsible when an autonomous system errs, manufacturers face open-ended exposure, hospitals face unclear risk, and the practical willingness to deploy is constrained regardless of technical readiness. This is a legal and institutional gate rather than a technical one, and such questions are often settled slowly, sometimes only after early cases force the issue, which means liability could gate deployment even after the technology and the regulation are ready.
Stacking these gates is what turns a vague “years away” into something more textured. The researchers themselves, who have every incentive to be optimistic, describe full autonomy on living humans as years off, and the structure of the path explains why: living-animal validation, then human-grade reliability across wide variation, then a regulatory pathway that may have to be built, then a liability model that may have to be litigated or legislated into existence, with each stage capable of running long. A reasonable reading is that narrow, supervised, semi-autonomous steps in tightly controlled settings could appear within years, while broad autonomous surgery on diverse patients is a longer and far less certain prospect, and that the most likely near-term reality is not autonomy at all but the incremental assistance arriving on existing platforms now.
The useful mental model is a staircase rather than a switch. Surgical autonomy will not flip from off to on; it will climb step by step, from assistance, to automation of small sub-tasks under close supervision, to longer autonomous phases with a surgeon ready to intervene, with each step requiring its own evidence and its own clearance. SRT-H is best read as evidence that the staircase is climbable and that the field has found a method that scales to longer, self-correcting procedures, not as a sign that the top of the staircase is near. The distance to a living patient is the sum of the gates between here and there, and that sum is measured in years even on an optimistic accounting.
The questions the evidence cannot yet settle
A careful reading of SRT-H is as much about what the result leaves open as about what it shows, and naming the unsettled questions plainly is the best guard against the overinterpretation that the researchers themselves warned about. These are not reasons to dismiss the work; they are the honest boundaries of what one clean cadaveric study can establish, and they mark where evidence is still missing.
The largest open question is whether the performance transfers to living tissue at all, and the cadaveric result simply cannot answer it. Everything that distinguishes a living surgical field, bleeding, movement, the body’s response, was absent from the setting where the system was tested, and those are exactly the factors that make real surgery hard. The result shows the method works when those factors are removed; it is silent on what happens when they return, and there is no way to extrapolate from the one to the other. Until the living-animal work is done, the central practical question about SRT-H has no evidence behind it in either direction.
A second open question is whether the approach generalizes across the variation a real patient population presents. The eight specimens were unseen, which is a real test of generalization within the range the training data spanned, but pig gallbladders are far more uniform than human anatomy across thousands of patients differing in body type, disease, prior surgery, and anomaly. Nothing in the study speaks to performance at the edges of human variation, and a method bounded by its demonstrations has no guarantees outside their range. Whether the system holds up on the unusual case, the very case where autonomy would most need to be trusted, is unknown, and a study on uniform specimens is structurally unable to reveal it.
A third question the evidence cannot settle is how the system fails when it fails, because in the study it did not fail. A 100 percent success rate means there were no failures to characterize, which is encouraging and also means the failure modes that matter most, the rare, dangerous, hard-to-recover errors, were not observed. Self-correction of routine mistakes was demonstrated; recovery from the kind of serious intraoperative complication that threatens a patient was not, because no such event arose in eight clean cases. The shape of the system’s behavior at its worst, which is what safety finally turns on, remains unseen, and a small successful study is precisely the kind of evidence that leaves it unseen.
A fourth open question is whether the data needed to extend the method to clinical breadth can actually be obtained or generated. SRT-H worked because roughly twenty hours of demonstration data were painstakingly collected for one phase on uniform tissue. Whether that approach scales, to many procedures, to full human variation, to the rare cases, at acceptable cost, is unknown, and it is the question the simulation and foundation-model research is implicitly betting cannot be answered by collection alone. If the data cannot be gathered or simulated at the required breadth, the method’s reach is capped regardless of how good the architecture is, and the study tells us nothing about which way that bet resolves.
There are quieter unsettled questions layered under these. Whether autonomous surgery will prove economically worthwhile once the cost of supervision, validation, and liability handling is counted is unknown, because no one has run an autonomous system in a real clinical economy. Whether the access argument, that autonomy could serve underserved populations, holds up against the data reality that those populations may be least represented in training data is unresolved, and the two pull in opposite directions. Whether the regulatory and liability systems can adapt in a workable timeframe is a question about institutions that no technical result can answer.
What ties these together is that they are the right questions to hold, and holding them is not skepticism for its own sake but the appropriate response to a single study on cadaveric tissue. The result earns genuine respect for what it demonstrated and settles none of the questions that determine whether autonomous surgery reaches patients, and the most accurate posture is to take the engineering seriously while keeping every one of these questions explicitly open. The people who did the work would, on the evidence of their own public pushback against overstatement, agree that these are the boundaries, and that the honest description of the result is one that names them rather than glossing over them.
A careful version of this future and what it would take
If autonomous surgery does eventually reach patients, the version worth wanting looks different from the one the most breathless coverage imagines, and describing it makes clear how much of the work that matters is not technical at all. The SRT-H result is a reason to think seriously about that future; it is also a reason to be specific about what a good version of it would require, because the gap between a capable system and a trustworthy clinical practice is where most of the hard work lives.
A careful version begins with human oversight built in rather than bolted on, which is the posture the relevant surgical bodies are already converging toward. The professional consensus taking shape holds that AI should support and sustain surgical practice with surgeons remaining the decision-makers, and that its introduction should be deliberate rather than hype-driven. A good autonomous future is not one where the surgeon disappears; it is one where autonomy handles defined, well-validated steps under genuine human supervision, with a clear path for the surgeon to intervene, and where the division of labor is designed around safety rather than around the marketing appeal of removing the human. The SRT-H episode itself, where the researchers pushed back when coverage suggested the robot operated on its own, is a small model of the discipline this future would demand.
It requires evidence proportioned to the stakes, which means resisting the temptation to let a striking result stand in for the validation that patient use actually needs. A good version of this future is reached by clearing the gates honestly, living-animal work that confronts bleeding and movement, reliability demonstrated across wide variation including the hard cases, regulatory review suited to learned and adaptive systems, rather than by predicate creep, overstated claims, or pressure to deploy before the evidence supports it. The history of medical technology offers both models, the careful path and the rushed one, and the careful path is the one that protects patients and, in the long run, the credibility of the technology itself.
It requires a resolved answer to responsibility, because a future in which autonomous systems act on patients while no one is clearly accountable when they err is not a good future regardless of how capable the systems are. Working out who answers for an autonomous error, and building the institutional machinery, the standards, the validation regimes, the liability model, to support that answer is as much a part of a responsible future as the engineering, and it is work that lawyers, regulators, hospitals, and manufacturers have to do together rather than something a better model produces on its own.
It requires honesty about the access promise that motivates much of the field. The argument that autonomous surgery could help address the vast unmet need for surgical care is a serious motivation, given how many people lack access and how many deaths follow from that gap. A careful version of this future takes the promise seriously and takes seriously the obstacle that the populations most in need may be least represented in the training data, and treats closing that representation gap as part of the work rather than assuming the technology will serve everyone equally by default. A version of autonomous surgery that worked well only for the well-represented would betray the access argument used to justify it, and avoiding that outcome is a design choice that has to be made deliberately.
Finally, a careful version preserves the skill and judgment that autonomy is supposed to supplement rather than erode. If routine tasks migrate to machines, the surgical profession has to choose actively how residents still build the foundational competence that matters most when something goes wrong, because that competence does not maintain itself once the routine work that used to build it is automated. A good future keeps human surgical judgment strong even as machines take on more, which is a question for surgical education and professional culture more than for engineering.
The honest conclusion is that the SRT-H result earns its place as a real milestone and earns none of the overstatement that surrounded it. A machine learned to perform a defined surgical phase adaptively and to correct its own routine errors under controlled conditions, which is a genuine advance and a reason to expect the field to keep moving. Whether that advance becomes a future worth having depends far less on the next modeling breakthrough than on the unglamorous work of evidence, oversight, accountability, fairness, and education that turns a capable system into a trustworthy practice. The technology made a real step; the harder and more human work of deciding how to use it well has barely begun, and that work, not the next result from the lab, is what will determine whether autonomous surgery ever deserves the trust that operating on a person requires.
Common questions about the Johns Hopkins autonomous surgery result
It autonomously performed the clipping-and-cutting phase of a gallbladder removal on pig tissue, applying six clips and making two cuts across seventeen distinct surgical tasks. It was not a full operation but a defined, technically demanding phase of one, carried out without a human controlling the instruments during the work.
No. It completed one phase, the part where the cystic duct and cystic artery are clipped and divided, which is the most delicate portion of the procedure. Other parts of a full cholecystectomy, such as freeing the gallbladder from the liver bed and removing it, were not part of the autonomous task.
Neither. The work was done on ex vivo porcine tissue, meaning gallbladders from pig cadavers, not on a living animal or a human. This matters because cadaveric tissue does not bleed, breathe, or move the way living tissue does, and those are the conditions that make real surgery hard.
It stands for Hierarchical Surgical Robot Transformer. The “hierarchical” part refers to its two-layer design: a high-level component that issues plain-language instructions and a low-level component that turns those instructions into the robot’s physical movements.
It learned by imitation from a large set of teleoperated demonstrations, on the order of sixteen to eighteen thousand, gathered across more than thirty pig gallbladders, totaling roughly twenty hours of data. The demonstrations included both clean executions and recovery maneuvers, so the system learned not only how to do the task but how to get back on track after a mistake.
It means the system completed the task successfully on all eight of the unseen pig gallbladders it was tested on. It is a promising research finding on a small, uniform sample, not evidence that the system is safe or reliable enough for human patients, where performance would have to hold across far wider variation and far larger numbers.
Self-correction is the system’s ability to notice when something is off and adjust on its own, rather than following a fixed script. It matters because real surgery is unpredictable, and a system that can only execute a predetermined plan is brittle, while one that recovers from its own routine errors is far closer to what operating on variable tissue actually requires.
The STAR system, which performed intestinal surgery on a live pig in 2022, relied on specially placed tissue markers and followed a rigid, predetermined plan. SRT-H worked on unmarked tissue, made its own decisions about a longer sequence of tasks, and corrected itself, which is the shift from following a mapped route to adapting to conditions.
The researchers describe it as reaching a high level of autonomy, often called Level 4 on a five-level scale, because it carried out the task and made intraoperative decisions without needing a human to approve its strategy. This is a contested and technical classification, and it applies to a narrow task under controlled conditions, not to surgery in general.
The work came out of Johns Hopkins University, with lead author Ji Woong “Brian” Kim and senior author Axel Krieger, and involved collaborators including researchers from Stanford and a surgeon and clinical experts from other institutions. It was supported by U.S. government funding.
It was published in the journal Science Robotics in July 2025, following an earlier preprint. Some descriptions circulating later carry a 2026 date, but the peer-reviewed result appeared in 2025.
Gallbladder removal is one of the most common operations, it has a well-defined structure that breaks cleanly into steps, and its clipping-and-cutting phase is delicate enough to be a meaningful test while bounded enough to be tractable. That combination of common, structured, and challenging made it a sensible target for an early autonomy result.
The researchers themselves describe full autonomy on living humans as years away. The path runs through living-animal testing, then reliability across wide variation, then regulatory clearance for a kind of system existing pathways were not built for, then a resolved answer on liability, and each of those stages can take years.
No. The near-term trajectory is AI assisting surgeons, not replacing them, and the relevant professional bodies favor keeping surgeons as the decision-makers with AI under human oversight. Even an eventual autonomous future is more likely to involve machines handling defined steps under supervision than operating independently.
The big ones are the leap from cadaveric to living tissue, achieving reliability across the full range of human anatomy and disease, regulatory frameworks that were not designed for learned and adaptive systems, and the unresolved question of who is responsible when an autonomous system errs. The data needed to extend the method to clinical breadth is a further constraint.
It does not change the market in the near term, where systems remain surgeon-controlled and the established da Vinci platform holds a dominant position with a large installed base and recurring revenue. Its longer-term significance is as a signal that competitive advantage in the field is shifting toward software, data, and AI rather than mechanical engineering alone.
In part. After publication, a comment in the scientific literature argued that some coverage turned step-level autonomy into the impression that a robot performs surgery on its own, and the researchers agreed that some coverage went beyond their intention, while defending their specific claims. The accurate description is narrower and more careful than the splashiest headlines suggested.
The method learns by imitating demonstrations, so it is bounded by what those demonstrations contained. It does not reason about anatomy from first principles, and outside the range of cases it was trained on, its behavior carries no guarantees, which is why generalization to the full variation of human patients is the central open question.
That is one of the long-term motivations, given how much of the world lacks access to safe surgical care. The hope is that consistent, capable systems could extend access and ease the workload on scarce staff, though this sits in tension with the fact that underserved populations may be the least represented in the data such systems learn from.
The stated next step is testing on living animals, where bleeding and movement come into play. Beyond that, the broader field is working on simulation and sim-to-real transfer, shared datasets, and larger models, largely in an effort to get past the data bottleneck that limits the demonstration-collection approach SRT-H relied on.
Author:
Jan Bielik
CEO & Founder of Webiano Digital & Marketing Agency
This article is an original analysis supported by the sources cited below
SRT-H: A hierarchical framework for autonomous surgery via language-conditioned imitation learning The peer-reviewed Science Robotics paper that reports the SRT-H system, its hierarchical language-conditioned design, and the autonomous clipping-and-cutting result on unseen ex vivo porcine gallbladders.
SRT-H research preprint The preprint version of the SRT-H work, with the full technical description of the two-level architecture, the training procedure, and the experimental evaluation.
SRT-H study record on PubMed The PubMed bibliographic record for the published study, confirming authorship, journal, and 2025 publication details.
SRT-H project page The research group’s project page for the Hierarchical Surgical Robot Transformer, with explanatory material and demonstration media accompanying the paper.
STAR robot performs intestinal surgery on a live pig Johns Hopkins coverage of the 2022 Smart Tissue Autonomous Robot result, useful for understanding the marked-tissue, fixed-plan approach that the later work moved beyond.
Autonomous robotic laparoscopic surgery for intestinal anastomosis in vivo The Science Robotics paper reporting STAR’s in vivo intestinal anastomosis, the earlier milestone against which SRT-H’s shift to unmarked, adaptive operation is measured.
Science Robotics study on learning-based surgical robot manipulation A Science Robotics contribution on learning approaches to robotic surgical manipulation, part of the research lineage leading toward language-conditioned autonomy.
Review of autonomy levels in surgical robotic systems An open-access review examining how cleared and experimental surgical robots map onto the recognized levels-of-autonomy framework, the basis for placing SRT-H near the higher end of that scale.
Open ex vivo cholecystectomy demonstration dataset The Scientific Data descriptor for the public dataset of segmented cholecystectomy demonstrations released alongside this line of work, illustrating the shared-data response to the field’s data bottleneck.
A blueprint for robotic surgery: from algorithmic control to embodied intelligence A 2026 perspective framing the field’s trajectory from explicit algorithmic control toward learning-based surgical embodied intelligence, including simulation and foundation-model directions.
Perspective on the future of autonomous surgery in Frontiers in Science A forward-looking analysis of where autonomous and AI-assisted surgery is heading, the obstacles to clinical use, and the role of simulation and data.
Surgical robots market analysis A market study covering size, growth, segments, and competitive structure of the surgical robotics industry, the commercial context this research result lands in.
The Lancet Commission on Global Surgery The Lancet Commission work documenting the global shortfall in access to safe surgical care and the scale of preventable death and disability tied to that gap.
World Health Organization on surgical care The WHO topic resource on surgical and anaesthesia care, supporting the access and disease-burden framing that motivates much of the autonomy effort.
AAMC physician workforce projections The Association of American Medical Colleges projections used for the expected shortfall of surgical specialists, relevant to the workforce argument for autonomy.
Intuitive Surgical da Vinci systems The manufacturer’s overview of the da Vinci platform, the dominant surgeon-controlled robotic system and the installed base any autonomy work has to reckon with.
CMR Surgical Versius system Information on the Versius robotic system, one of the competitors challenging the incumbent and a marker of the field’s mechanical-to-software competitive shift.
da Vinci Research Kit project The open da Vinci Research Kit used as the research platform for this and related academic surgical robotics work.
Johns Hopkins Laboratory for Computational Sensing and Robotics The Johns Hopkins research environment associated with the senior author and the broader surgical robotics program behind the result.
Chelsea Finn, Stanford University The page of a Stanford collaborator whose imitation-learning and robot-learning research informs the methods underlying the SRT-H approach.
Science Robotics journal The journal that published the result and the venue for much of the primary literature on autonomous and AI-driven surgery.














